

Imagine feeding your company’s multi-million-dollar AI model a daily diet of corrupted, mismatched, and incomplete data. For enterprises that treat web scraping as a simple “fetch and parse” script, this nightmare is often a reality.
In modern enterprises, web scraping is no longer just about writing a quick Python script. It is a complex data engineering and ETL pipeline that ensures high-quality data extraction. Websites constantly change their layouts, deploy aggressive bot software, and serve dynamic content, and without a robust Quality Assurance system, your data pipeline will inevitably break, taking your analytics and AI models down with it.
So, how do leading automated web scraping companies guarantee data accuracy at an enterprise scale? According to IBM’s 2026 Data Quality Research, 43% of operations leaders now rank it as a top priority. The secret lies in a multi-layered QA process.
Defining the output even before writing the scraper
The first meaningful shift is a process shift. Teams have to move on from thinking about collecting data to first defining it. Instead of extracting whatever is available, try to specify things like:
- Which fields are needed
- What valid values look like
- How complete should the dataset be
- How frequently should it update
Why is this so crucial? Without clear expectations, data validation in web scraping becomes reactive. With defined expectations, validation becomes measurable. Teams know what “correct” looks like and can detect when the system deviates from it.
In practice, automated web scraping companies use this step to anchor their QA workflows because every validation rule, alert, and review process depends on these definitions.
The Three-Stage QA Architecture
Professional web scraping companies build QA into the very crux of the data pipeline. This is typically structured in three distinct stages.
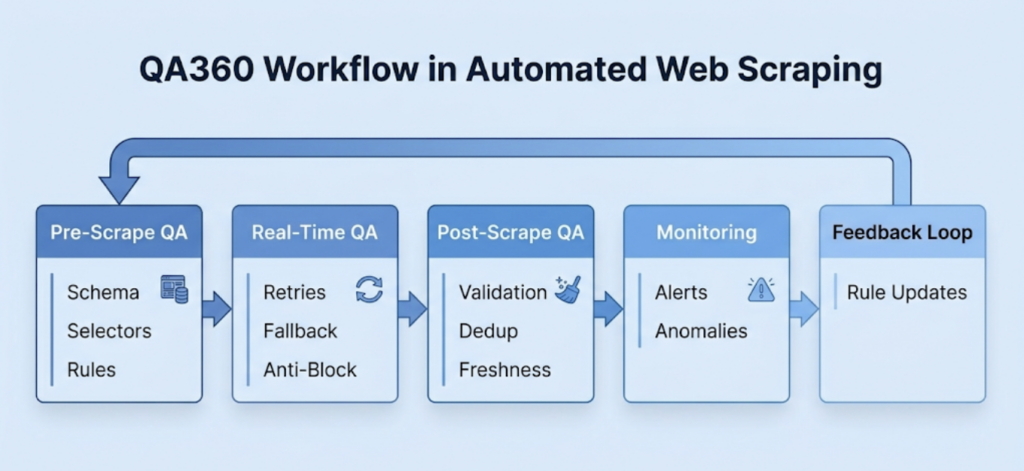
- Pre-Scrape Setup
The best way to handle an error is to prevent it from happening in the first place. Before a single byte of data is scraped, enterprise teams lay down a strong foundation that includes:
- Adaptive Selectors: Relying on a single CSS or XPath selector is a recipe for disaster. QA-driven setups build in fallback logic, ensuring that if a primary selector fails due to a minor UI update, the secondary and tertiary selectors immediately take over.
- Anti-Block Strategy: To deal with antibots, engineers configure intelligent IP rotation, header spoofing, and browser fingerprinting. This ensures the scraper is treated like a legitimate user rather than a suspicious bot.
- Real-Time Monitoring During Extraction
You need to ensure the scraper is extracting the exact data it is supposed to. Real-time QA acts as the pipeline’s immune system. Engineers deepnd of techniques like:
- Network & Captcha Monitoring: The system actively monitors HTTP response codes. If the scraper hits a wall of 403 Forbidden errors or triggers a CAPTCHA, it doesn’t just fail blindly. With AI-powered extraction, it is possible to circumvent the blocks during the crawl.
- Automated Recovery: When transient network issues or active blocking occurs, the system initiates automated retries and deploys fallback parsers, keeping the pipeline flowing without requiring manual intervention.
- Post-Scrape Validation
Extraction is only half the battle. Before the data is allowed anywhere near a production database, it must pass through a series of quality checks. Some are pretty basic, like checking the total number of entries, while others are advanced to ensure contextual accuracy. Here are a few examples:
- Schema Validation & Type Checking: Is the “Price” column actually a number? Are the “Date” formats standardized?
- Deduplication & Anomaly Detection: The system automatically scrubs duplicate entries and flags statistical anomalies, ensuring that downstream systems receive only clean, structured, and predictable data.
Rule-Based vs. AI-Assisted Validation
Traditionally, post-scrape validation relied entirely on rigid, rule-based systems, sometime with human-in-the-loop. While these are great for basic schema checks, they struggle with contextual ambiguity.
Imagine a scraper pulling pricing data for luxury hotels. A rule-based system might happily accept a room rate of ₹1 because it is technically a valid integer. An AI-assisted validation engine, however, understands context. It recognizes that a ₹1 per night luxury hotel room is highly improbable. It would likely be a promotional glitch or a parsing error, and it flags it for review. Integrating LLMs to determine contextual plausibility is an ideal example of AI-powered data validation.
Validation Criteria
What do we mean when we say validation? Well, most pipelines work on these 5 points to ensure complete data accuracy.
- Data completeness – Measures whether the dataset has all expected records and fields.
- Data validity – Ensures that the scraped data adheres to predefined formats, constraints, and rules.
- Data consistency – Ensures that the data is uniform, synchronized, and free from contradictions across the dataset.
- Accuracy signals – Indicates how closely the scraped data matches the real-world information.
- Data freshness – Measures how current the data is.
These checks form the core of automated web scraping QA.
| QA Signal | What It Measures | What it detects |
| Data Completeness | Are all expected records present? | Missing product listings due to pagination, Record coverage, etc. |
| Validity | Are values within expected formats? | Price showing as text instead of numeric. Includes format and range checks. |
| Consistency | Is data uniform across sources? | Different date formats across websites, ensures data uniformity and uniqueness as well as schema consistency. |
| Accuracy | Does data match the source? | Spots incorrect data using spot checks, cross-source verification, and outlier detection – is the value unusually high or low? |
| Data freshness | Is data fresh and updated? | Checks if outdated listings are not refreshed using timestamping and log monitoring. |
Human-in-the-Loop Feedback Cycle
Even with advanced AI, human oversight remains critical. Even though its role has evolved. In mature automated data extraction processes, humans shouldn’t be tasked with permanent, repetitive, and unscalable data cleaning. Instead, human review serves as a strategic input.
At Forage AI, we incorporate an automated system that flags a highly complex edge case, and a human reviews it. That human resolution is then used to refine the validation rules and train the system. By converting edge cases into automated rules, we’re able to continuously reduce technical debt and build smarter, more autonomous pipelines.
You must be wondering – why go through all this trouble? Well, because the quality of your web data directly dictates the intelligence of your AI. In the era of LLMs and RAGs, a common misconception is that more data equals a better model. The reality is that data must be structured, predictable, and highly accurate.
If your RAG system ingests scraped data with inconsistent formatting or missing fields, it directly degrades the context window provided to the LLM. The result? Your AI hallucinates, provides poor retrieval quality, and ultimately loses the trust of your users. You simply cannot build a reliable AI application on a foundation of bad data.
Enterprise scraping companies like Forage AI embed multi-layered QA processes into every stage of the workflow, ensuring data remains accurate, fresh, and dependable. As web data increasingly powers analytics and AI systems, QA-driven automation is foundational.
Custom QA For Custom Data
When dealing with custom automated data extraction workflows, the QA process becomes even more specialized. Because custom pipelines often target niche, highly complex, or heavily authenticated data sources, standard validation rules aren’t enough. As a custom data extraction partner, we build custom QA rules and guidelines for every project, integrating industry-specific context, schema validations, dynamic anomaly-detection thresholds, and tightly integrated human-in-the-loop workflows, guaranteeing that the final datasets perfectly align with our client’s highest operational standards.
If you’d like to chat more about our QA processes and how to improve the data quality of your project, reach out to us.



