

Manual data gathering is not always the most optimal approach. However, for most companies, adopting automated data extraction is not doing well either. And when you switch to automation, between constant website changes, aggressive anti-bot measures, and evolving compliance rules, maintaining reliable data flows requires more than just scripts.
In this blog, we’re going to share how to take the right steps to elevate your automated data extraction process and build a data infrastructure that is dependable and future-proof. These tips go beyond the basic recommendations.
True enterprise-grade automation means building systems that learn, adapt, and recover automatically turning the chaotic web into your most reliable data source.
The most reliable ways to automate large-scale web data extraction for enterprise use are:
- Designing a distributed crawler architecture – Using container orchestration with auto-scaling worker pools to prevent single points of failure.
- Incorporating multi-layer anti-blocking systems – Combining solutions like residential proxy networks, browser fingerprint rotation, behavioral pattern mimicry, and integrated CAPTCHA solving services.
- Building AI-powered adaptive extraction – Using computer vision and natural language processing to survive site redesigns without manual parser updates.
- Including human-in-the-loop validation – Human experts stepping-in to review complex cases and edge conditions while AI handles routine extraction.
- Building real-time monitoring infrastructure – Incorporating automated failover, self-healing recovery, and comprehensive alerting.
Enterprise-grade systems, because they are built to last the test of time, maintain significantly higher success rates, achieving sub-hour data freshness and regulatory compliance. The key differentiator is combining step-by-step strategic planning, identifying future needs and deploying solutions like AI-driven automation and human oversight ahead of time.
Lets dive deeper!
The Enterprise Data Extraction Blueprint: From Architecture to Compliance
Building a reliable, large-scale data extraction operation requires a strategic approach grounded in several key best practices. An ad-hoc collection of scripts will inevitably fail; a well-architected system is built to last. This blueprint should help you build a solid data extraction architecture.
A robust pipeline is modular and follows a clear, logical flow from source to insight. Think of it as a factory line for data.
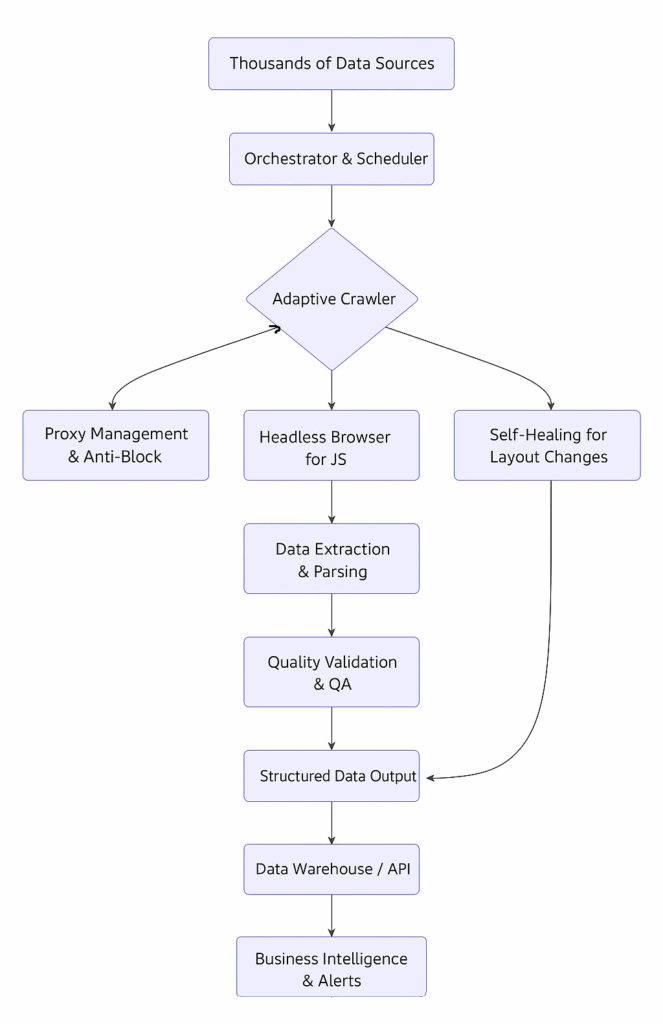
Let’s dissect each of the modules:
Modular, API-First Pipeline Design
The flow of our data extraction blueprint exemplifies true Modular, API-First Design. Each component in the diagram from the Orchestrator & Scheduler to the final Structured Data Output operates as an independent, containerized microservice.
This architecture creates clear fault isolation: if the Data Extraction & Parsing module encounters a problem, it doesn’t cascade back to crash the Adaptive Crawler. Crucially, an API-first approach means that clean, structured data is available at the end of the pipeline via a standardized Data Warehouse / API layer. This allows other business systems (like a CRM or BI tool) to consume the data instantly without understanding the underlying complexity of the crawling process, turning a complex technical pipeline into a simple, reliable data utility.
Anti-Block Defense Layers
The blueprint visualizes a multi-layered defense strategy, moving far beyond simple proxy rotation. The Adaptive Crawler is shielded by two dedicated, interconnected systems:
- Proxy Management & Anti-Block: This isn’t just a pool of IPs. It’s an intelligent system that rotates residential and datacenter proxies based on performance history, dynamically throttles requests to mimic human behavior, and uses TLS fingerprint randomization to avoid basic fingerprinting.
- Headless Browser for JS: For modern, JavaScript-heavy websites (like those built with React or Angular), this layer is non-negotiable. It fully renders pages and executes JS, allowing the system to access data exactly as a real user would see it, thereby bypassing client-side rendering blocks that would stop a simple HTTP client.
Together, these layers enable the crawler to access target data while scraping politely, reliably, and in accordance with the site’s terms of use.
Hot Tips: Handling Dynamic Sites and Layout Changes
When websites change structure, modern extractors use multiple fallback strategies to maintain data flow:
- Computer Vision to identify and extract key page elements by their visual position, not just HTML structure.
- Natural Language Processing to understand content context and relationships when DOM elements change.
- Automated A/B Testing of new extraction patterns to quickly identify the most effective parsing strategy.
- Human Review Queues for ambiguous cases that simultaneously resolve immediate issues and train future automation.
Data Quality at Scale: Automated Error Detection and Recovery
Reliable pipelines implement multiple validation gates that operate in real-time, each serving a distinct purpose in ensuring data integrity:
- Schema Validation acts as the first checkpoint, verifying that all extracted data matches expected formats and types. It ensures price fields contain numbers and dates follow consistent patterns, preventing malformed data from corrupting your datasets.
- Pattern Analysis serves as the intelligent monitor, comparing incoming data against historical trends to flag anomalies. It automatically detects when a normally $50 product shows as $5000 or when expected data patterns deviate, serving as your early warning system for both errors and significant market movements.
- Automated Retries function as the resilience engine, handling temporary failures like network timeouts or website unavailability. Using smart retry strategies with progressive delays, they automatically recover from transient issues without manual intervention, ensuring temporary problems don’t create permanent data gaps.
- Freshness SLAs provide a timeliness guarantee by monitoring the latency between source updates and data delivery. By enforcing strict time-bound commitments for different priority levels, they ensure your teams make decisions based on current market conditions rather than outdated information.
Together, these layers transform raw extraction into trustworthy intelligence, catching errors at multiple stages while maintaining continuous data flow.
Ensuring Scalability: From Hundreds to Millions of Data Points
Enterprise-scale architecture employs several key practices:
- Container Orchestration (Kubernetes) with auto-scaling worker pools that eliminate single points of failure.
- Distributed Crawling that parallelizes work across thousands of concurrent executions.
- Elastic Cloud Infrastructure that automatically scales compute and storage resources based on demand.
- Message Queue Systems that manage workload distribution and prevent data loss during traffic spikes.
If all this is too much for you, you can always work with expert data providers like Forage AI, who manage complex data extraction day in and day out.
Legal and Compliance Considerations
Operating at scale brings legal responsibility. A compliant strategy is the only sustainable one.
- Respect robots.txt and Terms of Service: Adhere to the rules set by website owners. This is the foundation of ethical data collection.
- GDPR, CCPA, and Data Privacy: Implement automated PII (Personally Identifiable Information) detection and redaction to protect consumer privacy and avoid severe regulatory penalties. Always follow legal guidelines.
- Intellectual Property: Be mindful of how you use extracted data. Follow copyright and intellectual property laws and best practices.
- Audit Trails: Maintain detailed logs of your extraction activities to demonstrate compliance in the event of an audit.
Handling Common Use Cases:
1. Price Intelligence and Market Monitoring
For e-commerce and retail, this is a direct competitive lever. Make sure you:
- Architect for Real-Time Freshness: Move from daily batches to minute-level updates with Data Freshness SLAs to react to market changes instantly.
- Implement Real-Time Alerting: Set rules to notify you when a competitor’s price drops, a product goes out of stock, or an anomalous price change is detected. Capture every opportunity.
2.Product Catalog Enhancement
- Automate supplier gap analysis by comparing your product attributes against supplier data to identify missing specifications, images, or certifications
- Implement cross-supplier matching using AI to reconcile different product identifiers (SKUs, UPCs) and create unified product records
- Set up continuous monitoring for product discontinuations, price changes, or specification updates from supplier sites.
3. CRM Enrichment
- Layer multiple data sources (Crunchbase, LinkedIn, news) to build comprehensive account profiles.
- Automate lead scoring based on real-time signals like hiring spikes or office expansions.
4. Market Intelligence
- Track competitor hiring velocity by department to anticipate new market entries or product launches.
- Monitor technology adoption through job descriptions and patent filings to gauge strategic direction.
5. Sentiment Analysis:
- Create sentiment lexicons tailored to specific industries that precisely understand domain-specific terminology.
- Correlate sentiment spikes with business metrics, such as sales data or stock performance, to validate signal quality.
6. Alternative data feed
- Establish ground-truth calibration: Periodically validate satellite imagery counts against physical audit data to improve model accuracy.
- Monitor leading indicators: Track shipping lane congestion and port activity as early signals for supply chain bottlenecks
- Create composite indices: Combine multiple operational metrics (parking lot traffic, shipping volumes, energy consumption) into single predictive scores
7. Regulatory Intelligence
- Automate jurisdiction tracking: Set up jurisdiction-specific monitors for policy changes in your operating regions
- Implement compliance cascade alerts: Trigger workflows when new regulations require updates to multiple internal policies
- Build regulatory change impact scoring: Rate new policies by potential business impact (high/medium/low) based on affected revenue streams
Take the smart way out: Build vs. Buy Analysis
The choice between building an in-house custom data extraction architecture or using a managed platform is a fundamental strategic decision with significant long-term implications. Navigating the data extraction landscape is tougher than you realize. It’s always better to work with partners who can help you extract the data you need without the hassles of building it all internally.
Pros & Cons: Managed Solutions vs. In-house Architecture
| Aspect | Managed Solution | Custom In-House Architecture |
| Time-to-Value | Deployment in weeks | 6-18 month development cycles |
| Total Cost | Predictable pricing | High hidden maintenance and recruitment costs (70-80% of TCO) |
| Expertise & Maintenance | Vendor-managed updates and scaling | Requires specialized/ additional team for constant maintenance |
| Compliance & Security | Built-in by design | Manual implementation and risk |
| Customization & Control | Platform limitations | Maximum flexibility for unique use cases |
For most enterprises seeking reliability and scale, a managed service provides faster time-to-value, predictable costs, and built-in compliance.
Criteria for Selecting a Vendor
If you do decide to go with a data partner, your next step is to find the right partner. Selecting a vendor is a strategic decision. Reflect on your requirements first before choosing your data provider. Key criteria include:
- Accuracy & Completeness: What is their success rate for data extraction in your industry? Do they provide samples?
- Scalability & Reliability: Can they handle your target volume and the sources you use? Ask about their uptime SLAs and architecture.
- Compliance & Security: Do they have built-in features for PII handling, audit trails, and respecting robots.txt?
- Ease of Integration: Do they offer native connectors to your data stack (e.g., Snowflake, Databricks) and easy-to-use APIs?
- Transparency: Do they offer a public status page and clear, SLA-backed performance metrics?
Project Deployment Roadmap
If you are working with a data partner, they will present an implementation timeline that is designed for max efficiency and fastest deployment. However, here’s sample roadmap for your guidance.
Phased Deployment Strategy
Phase 1: Discovery (Weeks 1-2)
Define your foundation for success
- Identify and prioritize your most critical data sources
- Establish clear KPIs: target success rates, data freshness requirements
- Map integration requirements with existing data systems
- Define compliance and governance standards
Phase 2: Pilot (Weeks 3-6)
Prove value with controlled deployment
- Deploy extraction for 10-20 highest-priority sources
- Implement real-time monitoring and quality alerts
- Validate data accuracy and integration workflows
- Refine processes based on initial performance data
Phase 3: Scale (Weeks 7-12)
Expand systematically while maintaining quality
- Onboard remaining sources in managed batches
- Optimize extraction schedules based on business priority
- Implement automated quality gates and anomaly detection
- Establish operational procedures and escalation protocols
Phase 4: Production (Ongoing)
Transform into a business-critical utility
- Continuous optimization based on performance analytics
- Regular compliance audits and governance reviews
- Advanced reporting and strategic value assessment
- Quarterly business reviews for ongoing improvement
This streamlined approach ensures methodical scaling while maintaining data quality and alignment with business objectives at each stage.
Success Metrics Framework: Measuring What Matters
To ensure your data extraction pipeline delivers tangible business value, track these core metrics that connect technical performance to business outcomes.
Track the metrics that make sense for your data extraction. For example, QA time might be more crucial for complex data extraction, whereas data freshness might be less relevant if the data you extract rarely changes.
| Metric | Target | Why It Matters | Business Impact |
| Data Freshness | <15 minutes for priority sources | Critical for time-sensitive decisions in price monitoring and market intelligence. | Enables rapid response to market changes and competitor movements. |
| Extraction Success Rate | >99.5% | Measures end-to-end pipeline reliability and ensures consistent data coverage. | Reduces data gaps that could lead to flawed analytics and missed opportunities. |
| Cost Per Accurate Record | Progressive Reduction | Tracks the operational efficiency and ROI of your data extraction initiatives. | Justifies investment in data infrastructure by highlighting clear efficiency gains over manual methods. |
| Maintenance Time Reduction | >70% | Quantifies engineering time saved from manual fixes, scaling, and pipeline upkeep. | Frees up technical resources for innovation and analysis rather than constant firefighting. |
Important Implementation Notes:
- Calibrate to Your Use Case: These benchmarks are a starting point. Define what success would mean for your project. Financial trading data may require sub-minute freshness, while market research might tolerate daily updates.
- Review and Evolve: Hold regular reviews to ensure these metrics continue to align with evolving business objectives as your data strategy matures.
- Start Conservatively: Begin with achievable targets and progressively optimize as your pipeline stabilizes and processes improve.
This comprehensive framework ensures all stakeholders, from engineering to leadership, understand how success is measured, creating alignment between technical execution and business value creation.
Conclusion
Moving from fragile data collection to reliable, automated extraction is no longer an IT project—it’s a competitive necessity that directly impacts your bottom line.
The challenges of scale, anti-blocking, and constant website changes make DIY approaches unsustainable for mission-critical operations. By implementing a solution built on the core pillars of reliability anti-block resilience, adaptive change management, guaranteed data quality, and built-in compliance—you transform web data from a sporadic insight into a strategic asset.
This isn’t about “enterprise-grade” buzzwords. It’s about achieving:
- Faster decision-making with continuous, high-quality data feeds.
- Reduced operational risk through automated monitoring and recovery.
- Lower total cost of ownership by eliminating constant maintenance.
- Confident compliance with governance frameworks that protect your organization.
The future belongs to organizations that can leverage public web data with the same reliability as their internal data sources.
Ready to transform web data into a competitive advantage? Speak with our data engineering experts to design a pilot that demonstrates how Forage AI can deliver high-quality, compliant data at scale for your specific use case.




