

As data volume surges alongside rapid AI adoption, real-time decision systems, and enterprise-scale automation, access to high-volume, accurate, mission-critical information is no longer optional. It is infrastructure. In this guide, you will learn how modern data extraction services in 2026 help enterprises build durable data advantage: from choosing the right strategy and architecture to adopting best practices, evaluating providers, and selecting a partner that can deliver enterprise web data feeds with consistency and compliance.
This guide is written for data leaders who are mapping the services landscape, what extraction-as-a-service actually delivers in 2026, how to evaluate providers, and how the managed-vs-in-house decision plays out in practice. For a tools-side breakdown (named software, feature comparisons, software-buyer pricing), see our companion guide on data extraction tools.

What is Modern Data Extraction?
Quick Summary — What are data extraction services?
Data extraction services are managed offerings that collect data from websites, documents, APIs, and other sources, then transform it into structured, dependable datasets for analytics and AI. Unlike data extraction tools (which are software you operate yourself), services are run by a partner end-to-end, including infrastructure, quality assurance, and ongoing maintenance. This guide covers the services category for buyers exploring the landscape; for a tools-side breakdown, see our companion guide on data extraction tools.
Modern data extraction in 2026 refers to structured automated data collection from diverse sources (web, documents, databases, and multimodal formats) and the transformation of that data into downstream-ready datasets for analytics, AI, and enterprise operations.
Unlike earlier “scripts and scrapers,” 2026 extraction is built around reliability, governance, and delivery. The operating environment has changed too: websites now actively defend against automated traffic at a scale that did not exist three years ago, and that reshapes what reliable extraction actually requires as a service. The goal is not just “getting data,” but producing enterprise-grade outputs that support business intelligence, AI training, and RAG systems with repeatable quality and refresh.
Modern teams increasingly rely on:
- Enterprise data extraction services that deliver governed, production-grade pipelines
- Managed data extraction services and web scraping delivered as a fully managed service for scale and continuity
- Custom automated data extraction workflows when schemas, sources, and business rules are unique — the broader frame for this is data extraction automation, where pipelines, orchestration, and monitoring are treated as one operating system rather than a stack of scripts
- Enterprise scraping for AI training data as model development accelerates
- Web data extraction for enterprise intelligence across competitive tracking, risk monitoring, and market intelligence
Businesses extract target data from a wide range of source types, often combining multiple streams into unified custom data feeds:
- Websites — competitive prices, listings, news, public profiles; retail and marketplace teams in particular rely on ecommerce data scraping for catalog, pricing, and assortment intelligence at scale, feeding price intelligence programs and dedicated competitor price tracking workflows for daily pricing signals
- Documents — emails, spreadsheets, PDFs, images
- Databases — relational and non-relational
- Multimedia — visual and audio media
- Custom — APIs, local drives, social media
- Customer data — first-party
- Data vendors — third-party
- Manual data collection — human-gathered
In 2026, the differentiator is not “how many sources you can scrape.” It is whether you can convert these inputs into dependable enterprise web data feeds with SLAs, governance, and change resilience. For a deeper look at extraction techniques and applications, see our techniques explainer.
Expert Insights
- As of March 2025, AI crawlers generate more than 50 billion requests per day on Cloudflare’s network, about 1% of all web traffic, reshaping what reliable extraction looks like as an operating environment. (Cloudflare AI Labyrinth, 2025-03)
- Services have outgrown software in the data extraction category. Managed extraction is projected to grow faster than the extraction software market through the end of the decade, as enterprises increasingly buy outcomes rather than tools.
- For most enterprise buyers, the decision to outsource extraction is now a legal-cover decision as much as a technical one. Compliance teams have moved from influencer to primary trigger-holder.
Evolution of Data Extraction: Traditional to Modern
Quick Summary — How has data extraction evolved into a services category?
Data extraction moved from manual and offshore work in the 2000s, to script-based automation, to ETL/ELT pipelines, and now to AI-assisted extraction delivered as a managed service. The services side of the category is growing faster than the software side because enterprises increasingly want outcomes (usable datasets) rather than tools they have to operate themselves.
Technological advancements have driven the evolution of extraction over the past decade. Recent industry analyses place the data extraction market on a strong upward trajectory through 2030, driven by the same forces (AI adoption, real-time analytics, governed pipelines) that have reshaped how the work gets delivered. The services side is outpacing the software side, which is the structural story behind why managed offerings have become the default for enterprise buyers.
The arc looks roughly like this:
- Manual extraction (2000s) — humans copy-pasting and aggregating; offshore teams scaled the labor. See our manual vs automated breakdown for the operational comparison.
- Early automation (mid-2000s to mid-2010s) — scripts, scrapers, and rule-based parsers. Faster, but brittle.
- ETL → ELT → ELTL — the data-engineering pattern that defined the 2010s. Extract first, then transform; later, transform inside the warehouse.
- Cloud-native extraction (late 2010s onward) — elastic compute and storage opened advanced extraction to more teams. Pipelines that used to require dedicated data centers became achievable for mid-market teams.
- AI-assisted, managed extraction (2024-2026) — the current frontier. Pipelines run as managed services with AI and human oversight; the deliverable is a governed dataset, not a script.
Cloud’s elasticity is what made the leap from “infrastructure project” to “managed service” possible. Once compute and storage stopped being capital constraints, the constraint moved upstream: source discovery, source resilience, governance, and delivery.
Expert Insights
- Services have outgrown software in the data extraction category. Available industry estimates place the managed web scraping services market on a faster growth trajectory than the extraction software market through the end of the decade, reflecting an enterprise preference for outcomes over tools. (Aggregated from third-party market research available to Forage AI at time of writing.)
- Across recent enterprise surveys, a clear majority of organizations report using web scraping in some form for AI and ML projects, a shift that has structurally increased demand for governed, production-grade extraction.
Understanding Modern Data Extraction Technologies
Quick Summary — What technologies power modern data extraction in 2026?
Five technologies power modern extraction: automation, machine learning, NLP, generative AI, and agentic AI. The 2026 frontier is agentic AI, autonomous systems that handle dynamic websites, schema drift, and changing extraction logic without manual reconfiguration. Services use these in layers, not one alone.
Modern data extraction technologies now use unprecedented data storage capacities and computing power to apply transformative strategies:
- Automation — rule-based and scheduled extraction at scale; the workhorse layer.
- Artificial Intelligence (AI) / Machine Learning (ML) — pattern recognition for unstructured documents and adaptive parsers; reduces the manual rule-writing burden.
- Natural Language Processing (NLP) — entity extraction, classification, sentiment, and summarization across text-heavy sources.
- Generative AI — schema inference, field normalization, and augmentation; collapses what used to be multi-step transformation work into a single pass.
- Agentic AI — autonomous, multi-step agents that handle dynamic content, anti-bot variation, and schema drift on their own. The 2026 frontier replacing the older “AGI is theoretical” framing; for a deeper look at how agentic extraction works in production, see our agentic AI explainer.
These layers do not replace each other. Production extraction services use them together. Rule-based automation is still the cheapest way to handle stable sources; ML and NLP handle variability; generative AI handles new formats; agentic AI handles the failure modes that defeated pure rule-based scrapers.
Expert Insights
- Agentic AI has moved from research-stage to production-stage for extraction workflows. Autonomous agents now handle the failure modes (anti-bot variation, schema drift, dynamic content) that defeated pure rule-based scrapers.
- The shift in 2026 is not that AI replaced humans; it is that AI moved from “parsing the data” to “deciding how to extract it.”
How Modern Data Extraction Changed Business Intelligence
Quick Summary — How did modern data extraction change business intelligence?
Modern extraction shifted BI from periodic reports built on stale data to continuous, AI-assisted insight built on live, structured, RAG-ready datasets. The deliverable has changed: where BI teams used to consume CSV exports, they now consume vector-DB-loadable, schema-inferred outputs ready for analytics and AI applications.
Seven shifts changed how BI is delivered:
- AI and NLP — entities, sentiment, and classification are now extracted at source, not post-processed downstream.
- Real-time web data harvesting — what used to be quarterly competitive intelligence is now continuous; decision latency has itself become a competitive variable.
- Intelligent Document Processing (IDP) — financial filings, contracts, invoices, and reports get parsed into structured fields at production scale.
- Generative AI in data augmentation — synthetic enrichment, field normalization, and gap-filling that used to require dedicated engineering effort. This also connects to the broader AI training data conversation.
- Big Data and cloud computing integration — elastic scale moved from premium to baseline.
- Custom large language models (LLMs) — domain-specific models trained on enterprise data extracted from external sources.
- Retrieval-Augmented Generation (RAG) as a delivery format — RAG is not only a downstream consumption pattern. Extraction services now deliver vector-DB-loadable, schema-inferred outputs as a first-class delivery format, not a downstream transformation step. See our RAG pipelines guide for the deeper view on what fails when this is not handled at source.
Taken together, these shifts changed what enterprises ask of extraction. Where BI used to consume CSV exports, it now consumes datasets pre-formatted for the applications that will use them.
Current Industry Challenges in Data Extraction
Quick Summary — What makes data extraction structurally harder in 2026?
Three forces converged: anti-bot defenses escalated and millions of websites now actively block automated traffic; AI-training-data scrutiny tightened, pulling legal teams into the buying decision; and enterprise data sprawl created a separate, expensive integration problem on top of the extraction problem itself. Modern services are built around all three.
Three challenge buckets define how teams think about extraction risk in 2026.
Business Challenges
- Cost management — extraction looks cheap until you price the maintenance.
- Resource allocation — engineering attention is the most expensive line item, not the infrastructure.
- Infrastructure readiness — most teams underestimate what governed, monitored, recoverable extraction actually requires.
- Knowledge gaps — the talent layer (data engineers who understand scraping, document parsing, and ML extraction together) is thin.
- Vendor sprawl — enterprise buyers who source data from specialized vendors (one per data type) commonly arrive at 10-15 vendor relationships within 12-18 months, often with a 30-50 person internal aggregation team consumed by field mapping and deduplication. The sprawl is its own integration problem on top of the extraction problem.
- Decision-making complexity — in-house vs third-party vs hybrid; the right answer depends on the team’s operating model, not just the budget.
Content Challenges
- Unstructured data — most enterprise-relevant data still arrives in formats that resist neat ingestion.
- Data freshness — stale data is worse than no data when it drives automated decisions.
- Ethical and legal considerations — GDPR, CCPA, and emerging frameworks (EU AI Act, India DPDP, evolving state laws) have pulled legal and compliance teams into the buying decision. In 2026, legal teams at enterprise buyers increasingly hold primary trigger-power on extraction decisions, not just review power. See our legal scraping breakdown for the deeper view.
- Data variety and velocity — formats and frequencies multiply faster than rule-based parsers can adapt.
Technical Challenges
- Data quality — accuracy benchmarks are easy to demo and hard to sustain.
- Data volume — at enterprise scale, throughput is a different engineering problem than at pilot scale.
- Scalability — pipelines that work at 100 sources frequently break at 1,000.
- Flexibility — schema drift is a constant; sources change, and rigid pipelines fail silently.
- Integration with existing systems — extracted data has to land in formats and cadences the rest of the stack can actually consume; see our enterprise pipelines breakdown for the failure modes.
- Anti-bot escalation — as of 2025, more than 2.5 million websites actively block AI training crawlers (Cloudflare), and AI-crawler traffic now sits at roughly 1% of all web requests on Cloudflare’s network (Cloudflare AI Labyrinth, 2025-03). Bad-bot traffic (non-AI automated traffic) is widely reported as comprising a significant share of total internet traffic on top of that (Imperva, 2024). Extraction has become a structurally adversarial operating environment, and that reshapes what “reliable” looks like as a service-level commitment.
Given this operating reality, the question is not whether enterprises need help adopting extraction services; it is how to adopt them well.

Adopting Data Extraction Services in 2026
Quick Summary — How should enterprises approach adopting data extraction services in 2026?
Adoption follows a three-step path: identify the business need (what data, what frequency, what governance constraints), choose a delivery model (managed service, custom build, or hybrid), and evaluate providers against extraction-specific criteria, not generic vendor checklists. Compliance is no longer a final step; it is a gate.
In 2026, enterprises want plug-and-play outcomes: usable datasets, delivered reliably, with governance and SLAs. That is why the category has moved toward managed service provider models rather than tool-only adoption.
Identifying your business needs
- Assess what data is essential — start from the decision the data has to drive, not from the source. Sources change; decisions are stickier.
- Determine the frequency, volume, and type of data required — daily competitive prices and quarterly regulatory filings have nothing in common operationally.
Choosing the right solution
- Evaluate delivery models — managed service, custom build, or hybrid. The right answer is rarely “the cheapest”; it is “the one whose operating model fits ours.” See our build vs buy guide for the strategic frame.
- Compare in-house vs outsourced realistically — the next two sections unpack what to score on and how the cost actually breaks down.
Working with best practices
- Compatibility with existing workflows — extraction outputs have to land where the rest of the stack can use them.
- Data quality and accuracy — score the QA model behind the numbers, not just the accuracy demo.
- Scalability and flexibility — pipelines that work at pilot scale frequently break at production scale.
- Data security and compliance — compliance (access policy, consent, data minimization, retention, and auditability) has shifted from a checkbox at the end of vendor evaluation to a gate at the start. Legal teams at enterprise buyers increasingly underwrite the extraction decision, not just review it.
- Continuous improvement — pipelines that do not evolve with sources fail silently; the operating model around the pipeline is what keeps it alive.
With the adoption frame in mind, the next question is what to actually score providers on.
How to Evaluate a Data Extraction Service Provider
Quick Summary — What should I look for in a data extraction service provider?
Score providers on seven extraction-specific criteria: QA team size relative to delivery team, coverage SLA (not just uptime), change-resilience guarantee, on-prem and data-sovereignty options, data ownership clause, schema-drift handling, and partnership vs transactional vendor model. Generic vendor-evaluation rubrics miss the failure modes that matter for extraction.
Generic vendor-evaluation rubrics (the kind used to score software purchases) catch most of what goes wrong with a SaaS buy. They were not built to catch what goes wrong with extraction services. The failure modes are different: schema drift, source-side anti-bot changes, coverage gaps that do not show up in a static accuracy benchmark, and ownership terms that surface only at renewal. The criteria below are what data leaders take into vendor conversations once they have moved past the demo.
The 7 criteria
- QA team size relative to delivery team. Industry baseline sits around 1:3 (one QA reviewer for every three delivery engineers). Best-in-class services run closer to 1:1 or higher. This ratio reflects how much human verification sits behind the automation, and it correlates more strongly with delivered accuracy than any single benchmark number.
- Coverage SLA, not just uptime. Uptime tells you the system is on. Coverage SLA tells you the percentage of the source list that is reliably delivered at the cadence you agreed to. Coverage gaps are where extraction services hide failure.
- Change-resilience guarantee. Sources will change. Anti-bot postures shift, schemas drift, layouts get redesigned. When that happens, what is the time-to-recovery? Automatic recovery? Human review queue? Alert-and-fix SLA? This is more diagnostic than any static accuracy benchmark.
- On-prem and data-sovereignty options. For regulated buyers (BFSI, healthcare, government, EU-regulated industries), on-prem deployment or in-region data residency is a governance gate, not a feature.
- Data ownership clause. Does the vendor retain, aggregate, or resell extracted data? “We never resell client data” has moved from differentiator to baseline expectation in enterprise procurement. If the clause is not explicit, treat it as missing.
- Schema-drift handling. What is the mechanism when a source schema changes? Production-grade services have a specific answer: alert, queue, auto-recover, or all three. Ad-hoc services do not; the script breaks and the team notices in the next downstream report.
- Partnership vs vendor model. Dedicated team and strategic conversations, or support tickets and account-management transactions? The partnership model is the structural difference between “extraction service” and “data automation partner,” and it shows up clearly in renewal economics.
A scorecard built on these seven criteria will look different from a generic procurement rubric. The reason is straightforward: most procurement rubrics were written for products you operate yourself. Extraction services are operated for you, which means the questions worth asking are different.
With the evaluation criteria in mind, the most common 2026 decision is the one the next section covers: managed vs in-house.

Managed Services vs In-House (What 2026 Buyers Actually Decide)
Quick Summary — Managed data extraction services vs in-house — what do 2026 buyers actually decide?
Most enterprise buyers move toward managed services in 2026 because the in-house cost is invisible until it is not: roughly two FTEs locked into scraper maintenance per >100-source pipeline, enterprise scraping platform licenses in the $150K-$200K range that often go underutilized, and offshore extraction-operations costs in the $400K-$500K range for partial coverage. Managed services collapse the operating overhead into a single accountable team.
In 2026, many enterprise teams adopt web scraping as a fully managed service because the maintenance burden of in-house scraping is consistently underestimated. The cost is structural and shows up in three components that are not visible at procurement time:
- The maintenance FTE load. Any in-house scraping pipeline that crosses roughly 100 sources tends to require around two FTE-equivalents on ongoing maintenance, and that is before quality assurance, infrastructure work, and on-call. The number scales roughly linearly with source count and inversely with source stability.
- The “license nobody can run” pattern. Enterprise scraping platforms in the $150K-$200K license range (Mozenda, Blue Prism-style RPA, similar enterprise tooling) are commonly bought and then underutilized. The operating model required to actually run them (engineering attention, QA layer, monitoring discipline) is the more expensive component than the license itself.
- Partial-coverage offshore operations. Many enterprises end up with a hybrid: an offshore extraction-operations team in the $400K-$500K annual range delivering partial coverage of a target source list, with quality and freshness varying by source. The cost is real; the coverage gap is often what triggers the eventual move to a managed provider.

Common reasons enterprise buyers choose managed providers, once those costs are visible:
- Faster time-to-value
- Reduced engineering maintenance burden
- Higher reliability under source change
- Stronger compliance posture
- Clear SLAs and data delivery guarantees
For the deeper TCO model (fully-loaded cost comparison, scenario modeling, and breakeven analysis), see our managed vs in-house analysis. For the strategic build-vs-buy frame, see our build or buy guide. For readers ready to shortlist providers, see our web scraping companies comparison.
Forage AI operates the managed-extraction model end-to-end: dedicated team, full pipeline ownership from source discovery through delivery, no reselling of extracted data, and the QA layer built into the service rather than left to the client.
Forage AI: Your One-Stop Data Automation Partner
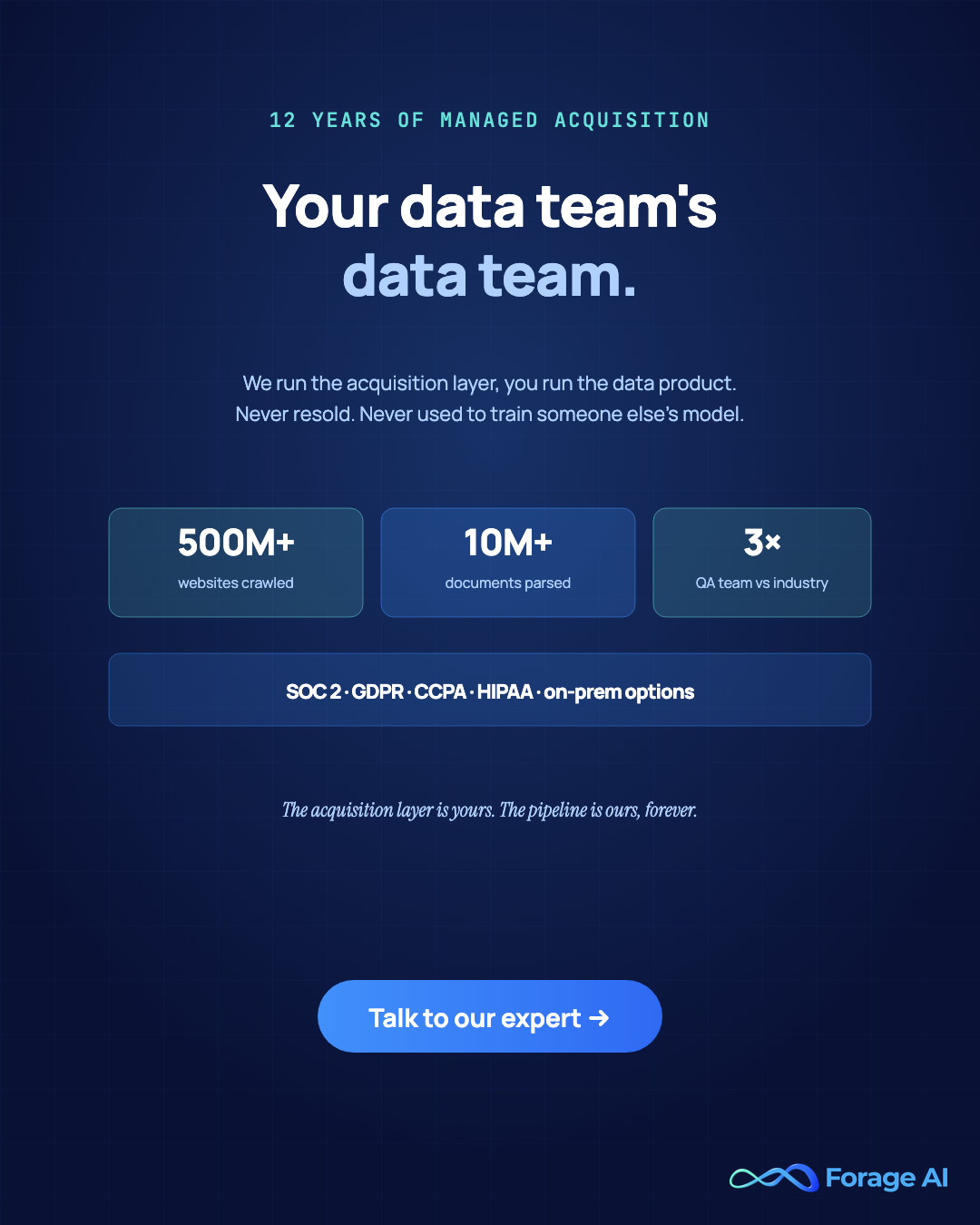
12+ years operating extraction pipelines. 500M+ websites crawled. 10M+ documents parsed across financial filings, legal records, and technical reports. 5M+ professionals monitored. A QA team approximately three times the industry-average size relative to delivery. This is the operating shape behind Forage AI’s managed extraction service.
What Forage delivers:
- Multi-modal data extraction — web, documents, multimedia, and structured sources handled through one pipeline rather than stitched across vendors.
- Change detection and resilience — sources change; pipelines adapt. The change-resilience SLA is the service, not a feature flag.
- Enterprise data governance — no reselling of client data, full ownership clauses, on-premise options for regulated buyers.
- Layered AI: automation + ML + NLP + generative AI + agentic AI — used together, not as separate offerings, because real extraction problems require more than one technique.
- Data delivery assurance — SLAs on coverage, freshness, and accuracy, not just uptime.
- True partnership model — dedicated team, strategic data conversations, source-discovery and pipeline expansion as the relationship grows.
Final Thoughts
The opening framed extraction as infrastructure, not optional. By 2026, that framing is the operating reality. The role of extraction has shifted from “data collection” to data infrastructure, and the arc from manual processes to AI-assisted automation is not just a technology shift; it is a structural shift in how businesses build advantage.
The value of extraction is still proportional to five things:
- Quality
- Freshness
- Coverage completeness
- Governance
- Delivery reliability
The services that score well on all five are the ones enterprises end up with for the long arc. The ones that score on two or three are the ones that get replaced.
Take the Next Step
If you are earlier in the journey, this guide gave you the services landscape: what modern data extraction means in 2026, how the category evolved, what challenges define it, and how managed services compare to in-house. If you are closer to evaluating providers, the 7-criteria scorecard gives you what to actually score on. When you are ready to talk through a data strategy, we are here.
Sources
- Cloudflare, 2025. AI Labyrinth: How Cloudflare uses AI to combat AI crawlers.
- Cloudflare, 2025. Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives.
- Imperva, 2024. Bad Bot Report 2024.




