

The dashboard was green. The data was three days stale.
We have watched this play out on more than one data team: a vendor feed quietly stopped refreshing, every job reported “success,” and nobody noticed until a downstream revenue number came back wrong in a Monday review. The pipeline ran. The source had not. That is the trap with data observability tools when the data is external: you own the consequences of a broken feed, but not the source that broke it. And the cost of missing it is not abstract. Gartner puts poor data quality at an average of $12.9 million per organization per year, and data teams routinely lose close to 40% of their time firefighting issues they did not create.
External data breaks differently than your own. When a warehouse table goes wrong, you read the code, find the bug, and ship a fix. When a partner API renames a field, a scraped page changes its layout, or a licensed feed silently halves its rows, the cause sits upstream where you have no write access. A tool can tell you the table looks off. It cannot reach into someone else’s pipeline and repair it. That single difference is the lens this guide judges every tool on.
So this is a categorized tour of the tools that watch your data for you, scored on the one axis most roundups skip: how well each handles data you do not control. We will not re-explain the fundamentals here; for those, see what data observability means for third-party datasets. In one line, data observability is the practice of continuously monitoring data health across freshness, volume, schema, distribution, and lineage, so you catch a break before a stakeholder does. By the end you will know which data observability tool fits which external-data failure mode, and when the right answer is a partner who owns the source.
Quick Digest
- The external-data trap: you own the consequences of a broken vendor feed but not the source, so a tool can alert you that it broke and still cannot fix it upstream.
- The five pillars, reframed: freshness, volume, schema, distribution, and lineage, each re-expressed for sources you do not control (the vendor’s cadence, a silently halved scrape, a payload that changed shape).
- Six categories, seventeen entries: general platforms, dbt-native, open-source/dev-first, pipeline/ingest/cost, catalog/lineage, and a managed external-data partner at the bottom.
- General platforms: Monte Carlo, Bigeye, Anomalo, Sifflet, Acceldata, Validio, Telmai. Telmai and Validio fit live external feeds best; Monte Carlo is the broadest but warehouse-centric.
- Open-source wins at ingest: Great Expectations and Soda Core let you assert a raw third-party payload’s schema and ranges before you ever trust it; dbt tests are a first guardrail, not full observability.
- The roster is current as of June 2026: Metaplane is now Metaplane by Datadog (Apr 2025), and SYNQ is now Coalesce Quality (Mar 2026).
- When to go managed: when the recurring pain is the source itself and you want someone accountable for re-extracting and fixing it, not just an alert.
How We Judged: the Five Pillars Through an External-Data Lens
Most roundups rank these tools on warehouse and dbt fit. We judged them on something narrower and harder: how each one performs against data you do not control. No vendor paid for placement, ratings are point-in-time public signals as of June 2026, and pricing is described as a model because hard dollar figures from comparison sites are guesses.
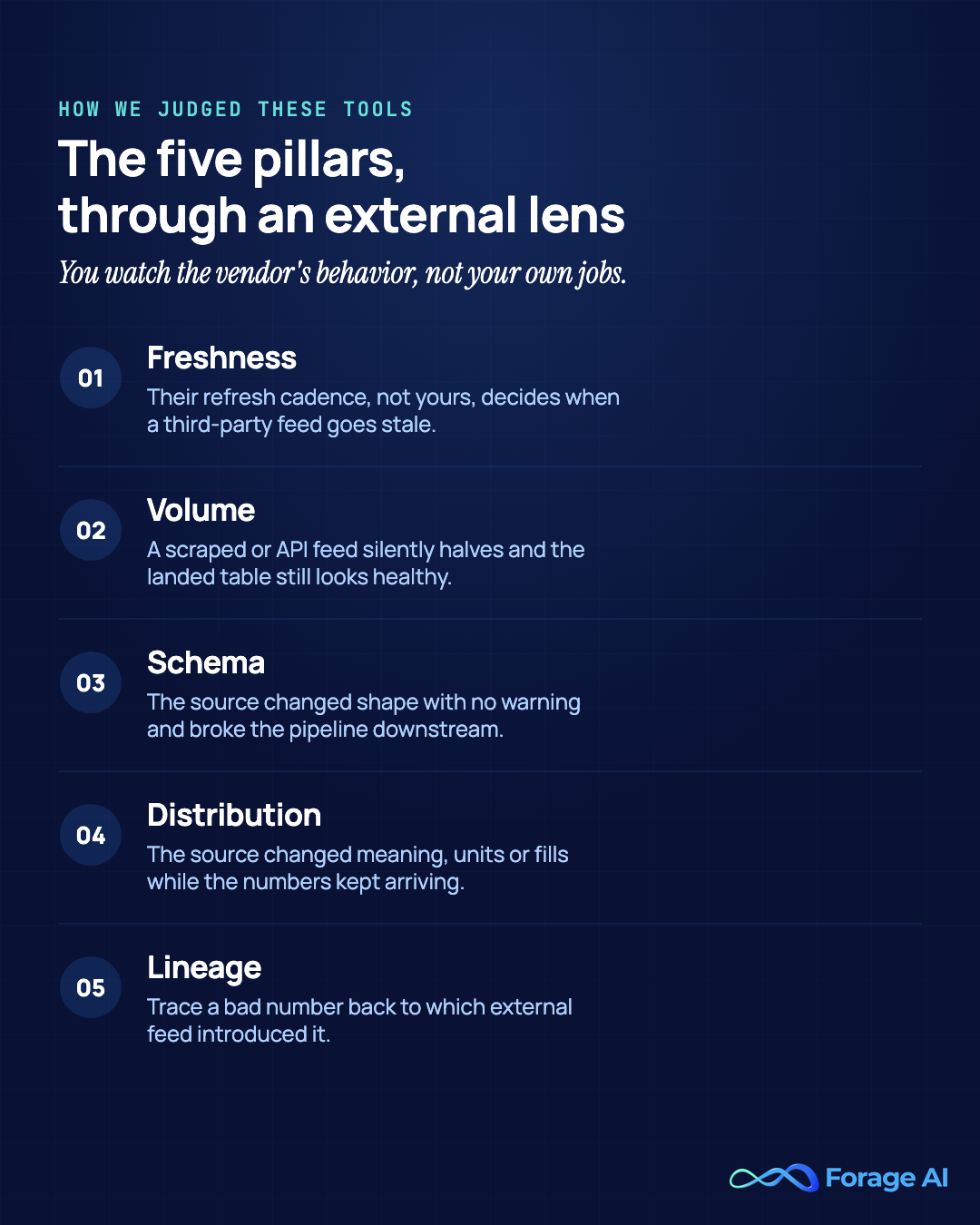
The five pillars are the rubric, not the article. The framework comes from Barr Moses, co-founder and CEO of Monte Carlo, who coined the term and defined data observability as an organization’s ability to fully understand the health of the data in their systems by applying DevOps observability practices to data pipelines. The pillars are table stakes. What changes for external data is what each one is actually tracking.
| Pillar | Standard definition | External-data reframe |
|---|---|---|
| Freshness | Is the table up to date; expected update cadence. | The vendor refreshes on their cadence, not yours; the freshness SLA tracks their promised refresh and fires when a third-party feed goes stale or arrives late. |
| Volume | Is row count within expected bounds. | A scraped or API feed that silently halves (a blocked crawler, a rate limit, a dropped region) surfaces as a volume anomaly before anyone notices missing records downstream. |
| Schema | Detect added, dropped, renamed, or retyped columns. | The source site or API changed its structure with no warning; schema-drift alerts catch the upstream change you were never told about. |
| Distribution | Statistical shape of field values. | A source quietly changes how it reports a value (currency, units, default fills, category labels); distribution checks catch the meaning-shift on data you cannot QA at the source. |
| Lineage | Trace origin and transformations to find where an error entered. | Lineage across vendors, so you can trace a bad downstream number back to which external feed introduced it and know which third party to chase. |
Five capabilities separate a strong external-data fit from a warehouse-only one. Source-change detection that watches the raw source, not just your landed table. Schema-drift alerts that fire at ingest, before drift propagates into clean tables. Freshness SLAs modeled on the vendor’s promise, distinct from “your job ran.” Validation and QA at ingest that assert the raw payload before it is trusted. And lineage across vendors, to localize blame to a feed.
If your warehouse table looks fine, your external data is not necessarily fine. A landed table can look perfectly healthy while the source silently changed meaning (a distribution shift) or dropped a region (a volume drop you mistook for a slow week). The table passed because it never knew what it should have contained.
One more distinction worth holding onto, because the rest of this guide depends on it. Observability is continuous, baseline-aware monitoring across the pillars. Data quality testing is the broader discipline. A dbt test or a one-off assertion is a point-in-time check you wrote by hand. They overlap, but they are not the same, and the gap matters most on data you did not author. Schema changes, by Monte Carlo’s own framing, are among the most common culprits of data downtime, and on an external source you do not even get a heads-up.
The category is growing for a reason. The data observability market sits at $3.51 billion in 2026 and is projected to reach $6.03 billion by 2031, an 11.42 percent CAGR. Poor data quality, separately, costs organizations an average of $12.9 million a year per Gartner. The structural limit underneath all of it: every tool here watches the table after the data lands. The cause of an external break sits upstream, where you have no write access. For the freshness argument behind why static feeds decay, see why real-time extraction beats static, decaying databases, and for the validation gates themselves, reliable automated data-collection pipelines.
Quick Summary
Q: What are the five pillars of data observability, and what changes for external data?
A: Freshness, volume, schema, distribution, and lineage. For sources you do not control, each pillar tracks the vendor’s behavior (their refresh cadence, their payload shape, their record counts) rather than your own jobs, because you own the consequences but not the source.
The Categories of Data Observability Tools
The fastest way to get lost in this market is to compare a catalog against an open-source assertion library against a managed service as if they were the same kind of thing. They are not. They sit at different points in the pipeline and answer different questions.

There are six categories worth knowing. General platforms watch everything with ML. dbt-native tools live inside the modern data stack. Open-source and dev-first tools put checks in your code. Pipeline and cost tools watch the runs and the bill. Catalog and lineage tools map where data flows. And a managed partner owns the source side end to end. Each section below opens with a comparison table across the same columns, then goes tool by tool.
Quick Summary
Q: What are the categories of data observability tools?
A: Six: general ML platforms, dbt-native tools, open-source and developer-first checks, pipeline and cost monitors, catalog and lineage tools, and a managed external-data partner. They sit at different points in the pipeline and answer different questions, so the right pick depends on where your external-data risk lives.
General Data Observability Platforms
These are the ML-driven, enterprise-scale platforms that monitor all five pillars across your stack, and they are where most “best data observability tools” searches land first.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Monte Carlo | Broadest mature coverage plus lineage | Contact-sales, volume/asset-based | 4.3 on G2 (~489) | Strong after land, but treats an external feed as just another warehouse table | Price and per-connector add-ons; opaque pricing |
| Bigeye | SLA-driven, configurable metric checks | Contact-sales, tiered | 4.1 on G2 (~22) | Good metric/SLA granularity for vendor-feed SLAs; still warehouse-centric | Smaller community; setup effort |
| Anomalo | No-rules ML anomaly detection | Contact-sales | 4.4 on G2 (~41) | ML catch is useful on noisy external data you cannot pre-rule | Alert noise; opaque pricing |
| Sifflet | Business-context-aware triage | Contact-sales, usage-based | 4.6 on G2 (~45) | Lineage and business-risk help triage which external breakages matter | Younger platform; modest review base |
| Acceldata | One platform across quality, infra, and cost | Volume/credit-based, contact-sales | 4.5 on G2 (~56) | Reconciliation helps compare external-source vs internal record counts | Breadth means complexity; enterprise weight |
| Validio | Deep, segmented, real-time anomaly detection | Contact-sales | 5.0 on G2 (~16) | Data-in-motion and real-time alerting fit live external feeds | Small review base; enterprise-oriented |
| Telmai | Semi-structured external data, pre-land | Contact-sales / marketplace | Listed on G2/Capterra; rating not independently verified | Strong: validates raw in-flight JSON/Parquet, not just warehouse tables | Limited public review signal |
Monte Carlo
| Field | Detail |
|---|---|
| Tool | Monte Carlo |
| Model | Platform |
| External-data fit | Mature on freshness/schema/lineage after land; treats an external feed as just another monitored table |
| Pricing model | Contact-sales; volume and asset-based (enterprise) |
| Rating / Reviews | 4.3 on G2 (~489 reviews), as of June 2026 |
| Best for | Large teams wanting the category leader and broadest coverage |
| Watch-out | Price plus per-connector add-ons; opaque pricing |
Monte Carlo is the category creator and still the broadest option. ML auto-monitors all five pillars end to end, and reviewers rate the lineage and coverage as the strongest in the field, the reason it lands at the top of nearly every roundup. The honest external-data caveat is that it watches the warehouse, so a vendor feed is just another table to it; it will tell you the table changed, not that the source upstream did. For the failure modes it catches downstream, see silent failures and schema drift in data pipelines.
Who it’s for: large data teams that want the most mature, broadest end-to-end coverage and have the budget for it.
Watch-out: the price plus per-connector add-ons and the opaque, contact-sales pricing make adoption a real budget decision.
Bigeye
| Field | Detail |
|---|---|
| Tool | Bigeye |
| Model | Platform |
| External-data fit | Granular metric and SLA monitoring useful for vendor-feed SLAs; warehouse-centric |
| Pricing model | Contact-sales; tiered |
| Rating / Reviews | 4.1 on G2 (~22 reviews), as of June 2026 |
| Best for | Teams wanting SLA-driven, configurable checks |
| Watch-out | Smaller review base; setup effort for advanced metrics |
Bigeye is the SLA and metric-native pick. It exposes everything as queryable metadata and lets you define deep, metric-level monitoring with autometrics, which teams that think in SLAs value for vendor-feed freshness and volume guarantees. The trade-off reviewers note is a heavier configuration effort than the dbt-native tools and a smaller community to lean on.
Who it’s for: teams that want to define granular, SQL- and SLA-driven checks rather than rely on out-of-the-box ML.
Watch-out: the review base is small and advanced metrics take setup work, so budget for the ramp.
Anomalo
| Field | Detail |
|---|---|
| Tool | Anomalo |
| Model | Platform |
| External-data fit | Unsupervised ML catches anomalies on noisy external tables you cannot pre-rule |
| Pricing model | Contact-sales |
| Rating / Reviews | 4.4 on G2 (~41 reviews), as of June 2026 |
| Best for | Teams wanting auto-detection without writing rules |
| Watch-out | Alert noise; opaque pricing |
Anomalo is the no-config ML anomaly pick. Its baseline learning surfaces anomalies you did not think to write a rule for, which is genuinely useful on noisy external data where you cannot anticipate every failure, and reviewers praise the easy setup. The recurring complaint is alert volume: an ML baseline that flags too much trains people to ignore it.
Who it’s for: teams that want unsupervised anomaly detection on landed tables without authoring checks by hand.
Watch-out: alert noise and non-transparent pricing, so tune the thresholds early or the signal drowns.
Sifflet
| Field | Detail |
|---|---|
| Tool | Sifflet |
| Model | Platform |
| External-data fit | Lineage plus business-risk context helps triage which external-feed breakages actually matter |
| Pricing model | Contact-sales; usage-based by assets monitored |
| Rating / Reviews | 4.6 on G2 (~45 reviews), G2 Spring 2026 Leader/Momentum badges, as of June 2026 |
| Best for | Teams bridging data and business stakeholders |
| Watch-out | Younger platform; review base still maturing |
Sifflet is the business-aware, catalog-centric option. It pairs auto-coverage and lineage with business context, and its AI agents diagnose root cause and suggest fixes, which G2 reviewers tie to fast implementation and strong estimated ROI. For external data, that business-risk framing helps you triage which broken feed actually threatens a downstream metric versus which is noise.
Who it’s for: teams that need health surfaced next to the catalog and business context, not just raw alerts.
Watch-out: it is a younger platform with a modest review base, so depth on edge cases is still maturing versus the incumbents.
Acceldata
| Field | Detail |
|---|---|
| Tool | Acceldata |
| Model | Platform |
| External-data fit | Reconciliation across sources helps compare external-feed counts against internal records |
| Pricing model | Volume/credit-based; contact-sales |
| Rating / Reviews | 4.5 on G2 (~56 reviews), as of June 2026 |
| Best for | Enterprises wanting quality, infra, and cost in one platform |
| Watch-out | Breadth equals complexity; enterprise pricing |
Acceldata is the broad “data plus compute” enterprise platform. It unifies data quality, schema-drift detection, reconciliation, pipeline monitoring, infrastructure, and FinOps, and reviewers single out the support and the breadth. The reconciliation piece is the external-data angle worth noting: comparing what an external source sent against what your internal records expect catches silent gaps.
Who it’s for: large enterprises that want one platform spanning quality, reliability, and cost across a multi-source estate.
Watch-out: that breadth makes it heavier to operate and enterprise-priced, so it can be more than a quality-only team needs.
Validio
| Field | Detail |
|---|---|
| Tool | Validio |
| Model | Platform |
| External-data fit | Data-in-motion and real-time alerting fit live external and streaming feeds |
| Pricing model | Contact-sales |
| Rating / Reviews | 5.0 on G2 (~16 reviews), as of June 2026 |
| Best for | Teams with live feeds and critical real-time flows |
| Watch-out | Few reviews; enterprise-focused |
Validio is the real-time and segmented-anomaly pick. It monitors data at rest and in motion, with segment-level outlier and threshold alerting, and reviewers call out the easy setup and helpful support despite the small review base. The data-in-motion capability is what makes it fit live external feeds and streaming third-party data better than warehouse-only tools that only see data after it settles.
Who it’s for: product and data teams running live feeds or critical real-time flows where catching drift in motion matters.
Watch-out: the review base is small (sixteen) and the orientation is enterprise, so validate it against your own feed shape.
Telmai
| Field | Detail |
|---|---|
| Tool | Telmai |
| Model | Platform |
| External-data fit | Strong: monitors raw, in-flight semi-structured JSON/Parquet before it lands, no sampling |
| Pricing model | Contact-sales / AWS Marketplace |
| Rating / Reviews | Listed on G2/Capterra; rating not independently verified |
| Best for | Teams ingesting semi-structured external data across ingestion to prod |
| Watch-out | Less dbt/MDS-native polish; limited public review signal |
Telmai has the strongest external-data fit in this category. It is open-architecture and no-code, and it monitors data in flight across lakes, streams, and APIs before it lands, with no sampling, detecting drift in the semi-structured JSON and Parquet that scrapes and APIs actually emit. That pre-land position is exactly where an uncontrolled source change first shows up, which most warehouse-centric tools miss until later.
Who it’s for: teams ingesting semi-structured external data who want to catch problems at the boundary, not after the table lands.
Watch-out: it has less dbt and modern-data-stack polish than the mid-market tools, and the public review signal is thin.

Quick Summary
Q: Which general data observability platform is best for external data?
A: For data you do not control, Telmai (in-flight, semi-structured JSON/Parquet, no sampling) and Validio (real-time, data-in-motion) fit live external feeds best, while Monte Carlo offers the broadest mature coverage but treats an external feed as just another warehouse table.
dbt-Native and Modern-Data-Stack Observability
If your external data already lands in a dbt project on Snowflake or BigQuery, these tools give you fast, native observability, with the caveat that they only see the source as far as dbt does.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Metaplane (by Datadog) | Mid-market dbt shops and Datadog customers | Datadog packaging; historically per-table | 4.8 on G2 (~65) | Warehouse/dbt-centric; sees data after it lands | Per-table cost at scale; acquisition-era roadmap |
| Elementary | dbt teams wanting cheap, native observability | OSS free; Cloud paid | ~2.4k GitHub stars | dbt-source freshness, only as far as dbt sees the source | dbt-bound; OSS vs Cloud feature gap |
Metaplane (by Datadog)
| Field | Detail |
|---|---|
| Tool | Metaplane (by Datadog) |
| Model | Platform |
| External-data fit | Quick freshness and volume on tables; warehouse-side, sees data after it lands |
| Pricing model | Now Datadog packaging; historically per-monitored-table (Pro) |
| Rating / Reviews | 4.8 on G2 (~65 reviews), as of June 2026 |
| Best for | Mid-market dbt shops wanting fastest time-to-value |
| Watch-out | Per-table cost at scale; now Datadog-owned (roadmap shifts) |
Metaplane is the fast-time-to-value mid-market pick, now owned by Datadog. Datadog acquired it on April 23, 2025, so it is “Metaplane by Datadog,” a detail many older rosters still miss. It delivers ML monitoring and column-level lineage with the highest satisfaction in the category, and reviewers love the quick setup. The per-table pricing model is the external-data watch-out: a sprawling third-party dataset can get expensive fast.
Who it’s for: mid-market dbt teams and existing Datadog customers who want native, fast-to-deploy monitoring.
Watch-out: per-table cost scales badly for large external datasets, and the post-acquisition roadmap adds some uncertainty.
Elementary
| Field | Detail |
|---|---|
| Tool | Elementary |
| Model | Open source |
| External-data fit | dbt-source freshness only as far as dbt sees the source; tests run as native dbt tests |
| Pricing model | OSS free; Elementary Cloud paid |
| Rating / Reviews | ~2.4k GitHub stars; no major G2 presence |
| Best for | dbt-centric analytics-engineering teams |
| Watch-out | Bound to the dbt/warehouse world; OSS vs Cloud feature gap |
Elementary is the dbt-native open-source option. It runs as a dbt package plus CLI with an optional cloud tier, adding anomaly detection and metadata on top of dbt with almost no extra infrastructure, which dbt teams value for getting observability in minutes. The external-data limit is structural: it sees the source only as far as your dbt project does, so it catches the problem after the data has already landed and been modeled.
Who it’s for: dbt-centric teams that want cheap, native observability inside the workflow they already run.
Watch-out: it is bound to dbt and the warehouse, and the open-source tier trails the cloud product on depth.
A note on the consolidation trend: in March 2026, Coalesce acquired SYNQ and rebranded it Coalesce Quality, part of a broader pattern of observability folding into transformation, APM (Datadog), and governance platforms rather than standing alone.

Quick Summary
Q: Are dbt-native observability tools enough for external data?
A: They are excellent inside a dbt and warehouse world but only see your external source as far as dbt does, after it lands, so they catch a problem downstream rather than at the boundary where an uncontrolled source actually changes.
Open-Source and Developer-First Data Quality Tools
This is the category with the best external-data fit at the lowest cost, because checks-as-code let you assert a raw third-party payload at ingest, before anything bad is ever trusted.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Great Expectations | Free, code-first validation at ingest | OSS free; GX Cloud paid | ~11.6k GitHub stars | Strong: pin expected schema and distributions on raw external payloads | Setup complexity; you host and maintain |
| Soda / Soda Core | Declarative checks plus an optional cloud layer | OSS free; Cloud paid | G2 Leader; rating not independently verified | Strong: lightweight SodaCL checks across many sources at ingest | Checks are only as good as you author them |
| dbt tests | A free first guardrail in an existing dbt run | Free (dbt Core) | Widely adopted; no standalone G2 | Source-freshness on declared dbt sources only | Point-in-time, not full observability alone |
Great Expectations (GX Core)
| Field | Detail |
|---|---|
| Tool | Great Expectations (GX Core) |
| Model | Open source |
| External-data fit | Strong at ingest: assert raw external payload schema, types, and ranges before trust |
| Pricing model | OSS free (GX Core); GX Cloud is the commercial tier |
| Rating / Reviews | ~11.6k GitHub stars; no major G2 presence |
| Best for | Engineering teams wanting free, versioned, code-defined checks |
| Watch-out | Setup complexity; you host and maintain it |
Great Expectations is the validation-as-code standard for ingest. You define declarative “expectations” in Python or YAML, run them in CI, and get auto-profiling and Data Docs, backed by an 11.6k-star community. For external data this is the right place to pin an expected schema and distribution on a raw payload, so a third-party change fails the check at the boundary instead of propagating into clean tables. Reviewers warn that the initial setup is steep and creates a sprawl of config files.
Who it’s for: engineering teams that want free, version-controlled, code-first validation they fully own.
Watch-out: you host and maintain it, and the learning curve is real, so it is not a click-and-go option.
Soda / Soda Core
| Field | Detail |
|---|---|
| Tool | Soda / Soda Core |
| Model | Open source |
| External-data fit | Strong at ingest: human-readable SodaCL checks across many sources, including external |
| Pricing model | OSS free (Soda Core CLI); Soda Cloud is the paid tier |
| Rating / Reviews | Listed on G2/Capterra as a G2 Leader; rating not independently verified |
| Best for | Teams wanting declarative checks-as-code plus an optional managed layer |
| Watch-out | Cloud upsell; hosting and scheduling are on you for the OSS core |
Soda is the declarative checks-as-code pick with a clean path to managed. SodaCL is human-readable YAML that compiles to SQL, the OSS Soda Core runs free from the CLI, and Soda Cloud adds collaboration, scheduling, and a strong data-contracts direction. The contracts angle maps well to external data: a contract is exactly how you declare what a vendor payload must contain and alert when it does not. Reviewers note the OSS tier lacks the cloud features and end-to-end depth of enterprise incumbents.
Who it’s for: engineering teams that want code-first checks now and the option of a managed cloud layer later.
Watch-out: hosting and scheduling fall on you for the free core, and the full feature set lives behind the paid cloud.
Here is what an external-feed check looks like in practice. This SodaCL block validates a third-party API payload at ingest, asserting it actually refreshed, returned enough rows, kept the schema you depend on, and did not start sending nulls.
# SodaCL: validate an external vendor feed at ingest, before you trust it
checks for vendor_api_ingest:
# Freshness: the vendor promised a daily refresh; alert if the feed is stale
- freshness(loaded_at) < 26h
# Volume: a silent halving usually means a blocked crawler or dropped region
- row_count > 10000
# Schema: fail if the source renamed or dropped a field you depend on
- schema:
fail:
when required column missing: [company_id, country, revenue]
when wrong column type:
revenue: decimal
# Distribution: catch an upstream source that started sending placeholder nulls
- missing_percent(revenue) < 5%dbt tests (incl. dbt-expectations)
| Field | Detail |
|---|---|
| Tool | dbt tests (incl. dbt-expectations) |
| Model | Open source |
| External-data fit | Source-freshness and assertions on data already modeled in dbt; a baseline guardrail |
| Pricing model | Free (part of dbt Core) |
| Rating / Reviews | No standalone G2 rating; dbt widely adopted |
| Best for | dbt-first teams wanting a free first line of defense |
| Watch-out | Point-in-time assertions, not a full observability layer alone |
dbt tests are the free first guardrail every dbt team already has. Native assertions plus `source freshness`, extended by the dbt-expectations package that ports Great Expectations-style checks, run inside your existing dbt jobs with zero extra infrastructure. For external data already declared as a dbt source, they catch staleness and broken assumptions cheaply.
dbt tests and one-off checks are point-in-time assertions, not continuous, baseline-aware observability. They catch what you thought to assert. They do not catch the anomaly you never anticipated, which is precisely the failure mode an uncontrolled source specializes in.
Who it’s for: teams already on dbt that want a free first line of defense before investing in a dedicated layer.
Watch-out: on their own they are not real observability, with no anomaly detection or lineage, so treat them as a floor, not a ceiling.

Quick Summary
Q: What are the best open-source data observability tools for external data?
A: Great Expectations and Soda Core are the strongest free options for external data because they let you assert a raw payload’s schema, freshness, and ranges at ingest, before bad third-party data is ever trusted; dbt tests are a useful first guardrail but not continuous observability on their own.
Pipeline, Ingest, and Cost Observability Tools
These tools watch the pipeline rather than the data itself, the runs, the regressions, and the bill, which is a different question from whether the third-party data flowing through is correct.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Datafold | Pre-prod data-diff and CI for pipeline changes | Contact-sales / tiered | Listed on G2/Capterra; rating not independently verified | Catches when your code change shifts data; less about uncontrolled-source drift | Learning curve; integration limits |
| IBM Databand | Pipeline-incident management in IBM/Airflow shops | Contact-sales (IBM) | 4.3 on G2 (~66) | Run-level (did the ingest job finish), not field-level correctness | Onboarding curve; enterprise price |
| Unravel | Big-data platform cost and performance | Contact-sales | Listed on G2/Capterra; rating not independently verified | Infra and cost lens; thin on external-source data quality | Not a data-quality-first tool |
Datafold
| Field | Detail |
|---|---|
| Tool | Datafold |
| Model | Platform |
| External-data fit | Data-diff catches when your code change shifts downstream data; less about uncontrolled-source drift |
| Pricing model | Contact-sales; commercial subscription |
| Rating / Reviews | Listed on G2/Capterra; rating not independently verified |
| Best for | Teams gating pipeline and PR changes with data-diff |
| Watch-out | Learning curve; limited integrations |
Datafold is the data-diff and regression-testing pick. Column-level diffing shows exactly how a code change moves your data before it hits production, which reviewers value for catching breakages in CI with a clean UI. The external-data nuance is that it is built around changes you make, so it shines when you change code, not when an uncontrolled source changes shape on you.
Who it’s for: teams that want to gate pipeline and pull-request changes with data-diff before deploy.
Watch-out: reviewers cite a learning curve and integration limits, and it is diff-focused rather than continuous anomaly monitoring.
IBM Databand
| Field | Detail |
|---|---|
| Tool | IBM Databand |
| Model | Platform |
| External-data fit | Pipeline-run-level monitoring (did the external-feed ingest job run and finish), not field-level |
| Pricing model | Contact-sales (IBM, enterprise) |
| Rating / Reviews | 4.3 on G2 (~66 reviews), as of June 2026 |
| Best for | Orchestration-heavy enterprises running IBM and Airflow |
| Watch-out | Steep onboarding; enterprise price |
IBM Databand is the orchestration-layer pipeline-observability pick. It centralizes pipeline-incident alerting and real-time run visibility, which Airflow-heavy and IBM-centric shops value for knowing the moment a job fails. For external data, it answers a real but narrow question: did the ingest job for the feed actually run and finish, rather than whether the data inside it is correct.
Who it’s for: enterprises with heavy orchestration that want pipeline-incident management, especially inside IBM.
Watch-out: onboarding is steep and pricing runs enterprise, with less field-level data-quality depth than the dedicated tools.
Unravel
| Field | Detail |
|---|---|
| Tool | Unravel |
| Model | Platform |
| External-data fit | Performance and cost lens; tangential to external-source data quality |
| Pricing model | Contact-sales (enterprise) |
| Rating / Reviews | Listed on G2/Capterra; rating not independently verified |
| Best for | Teams optimizing big-data platform cost and performance |
| Watch-out | Not a data-quality-first tool |
Unravel is the performance-and-cost (FinOps) observability pick. It brings AI-driven performance, reliability, and cost insight to Databricks, Snowflake, and BigQuery, which platform teams value for managing spend and tuning Spark-heavy workloads. It is the most tangential entry here for external-data quality: it watches what the pipeline costs and how it performs, not whether the third-party data is right. For how stale, drifting source data breaks downstream systems, see why RAG pipelines fail in production.
Who it’s for: teams whose priority is big-data platform cost and performance optimization.
Watch-out: it is not a data-quality-first tool, so do not buy it to monitor external-data correctness.

Quick Summary
Q: Do pipeline-monitoring tools help with external data quality?
A: Partly. They tell you whether the ingest job ran (Databand), whether a code change shifted your data (Datafold), or what the pipeline costs (Unravel), but they watch the pipeline more than the correctness of the third-party data flowing through it.
Catalog and Lineage Tools With Observability
These are the governance and catalog control planes that map where data flows and increasingly fold in quality signals, which makes them strong on the lineage pillar and weaker as active detectors.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Atlan | Governance and lineage across the stack | Contact-sales | Lineage 9.1 / support 9.5 on G2 | Maps where an external source flows; aggregates, does not detect | Catalog-first; pairs with, does not replace, a detector |
| Collibra | Governance-first regulated enterprises | Contact-sales (enterprise) | 4.2 on G2 (~102) | Governance with an observability module; quality is secondary | Heavyweight; quality secondary to governance |
Atlan
| Field | Detail |
|---|---|
| Tool | Atlan |
| Model | Platform |
| External-data fit | Deep lineage maps where an external source flows downstream; aggregates quality signals rather than detecting itself |
| Pricing model | Contact-sales; enterprise |
| Rating / Reviews | 4.6 on G2 (~131 reviews), with a lineage score of 9.1 and support 9.5, as of June 2026 |
| Best for | Teams centralizing governance and lineage across the stack |
| Watch-out | Catalog-first; it pairs with, rather than replaces, an active detector |
Atlan is the governance and lineage control plane. It offers deep column- and table-level lineage with auto-updates and an open lineage API, and it aggregates quality signals from tools like Monte Carlo, Great Expectations, and Soda rather than detecting on its own. For external data, lineage across vendors is exactly the pillar it serves: trace a bad number back to which feed introduced it. Reviewers note the feature set can overwhelm new users.
Who it’s for: teams centralizing governance and lineage and aggregating quality signals across a broad stack.
Watch-out: it is catalog-first, so it answers where data broke, not whether it broke; pair it with a detector.
Collibra
| Field | Detail |
|---|---|
| Tool | Collibra |
| Model | Platform |
| External-data fit | Governance-first, with observability as a module; quality is secondary to governance |
| Pricing model | Contact-sales (enterprise) |
| Rating / Reviews | 4.2 on G2 (~102 reviews), as of June 2026 |
| Best for | Large, regulated enterprises that lead with governance |
| Watch-out | Heavyweight; observability is a module, not the core |
Collibra is the enterprise governance suite with an observability module. It is built for large, regulated organizations that need cataloging, policy, and stewardship first, with data quality and observability bolted on as a capability. For external data it can govern where third-party feeds are used and apply policy, but detection is not its center of gravity.
Who it’s for: large regulated enterprises whose primary need is governance, with observability as a secondary requirement.
Watch-out: it is heavyweight and observability sits as a module, so quality is secondary to governance in practice.
A catalog or lineage tool maps where external data flows but does not itself detect that a source broke. It answers “where did it break,” not “did it break.” That is a complement to an observability detector, not a substitute for one.

Quick Summary
Q: Can a data catalog replace a data observability tool for external data?
A: No. Catalog and lineage tools like Atlan and Collibra are excellent at tracing which external feed flows where (the lineage pillar), but they answer “where did it break” rather than detecting that an uncontrolled source broke in the first place.
When Should You Hand External-Data Quality to a Managed Partner?
Here is the structural limit every tool above shares: each one alerts you that an uncontrolled source broke. None of them fixes the source. You still own the consequences but not the cause, and at some point the recurring answer to “the feed broke again” is not another dashboard.
| Tool | Best for | Pricing model | Rating | External-data fit | Watch-out |
|---|---|---|---|---|---|
| Forage AI | Teams whose pain is the external source itself | Custom managed engagement | No public review base (managed service) | Owns the source side: detects and fixes source/schema changes via re-extraction; freshness SLAs on third-party feeds | Not a self-serve dashboard; a partnership model |
Forage AI
| Field | Detail |
|---|---|
| Tool | Forage AI |
| Model | Managed |
| External-data fit | The only entry that owns the source side: detects and fixes source and schema changes via re-extraction, with multi-layer QA and freshness SLAs on third-party feeds |
| Pricing model | Custom managed-service engagement (onboarding measured in weeks) |
| Rating / Reviews | No major public G2/Capterra presence (managed-service partner, not self-serve software) |
| Best for | Teams who need someone to own external-data quality end to end, not just be alerted |
| Watch-out | Not a self-serve tool you operate; it is a partner you hand the problem to |
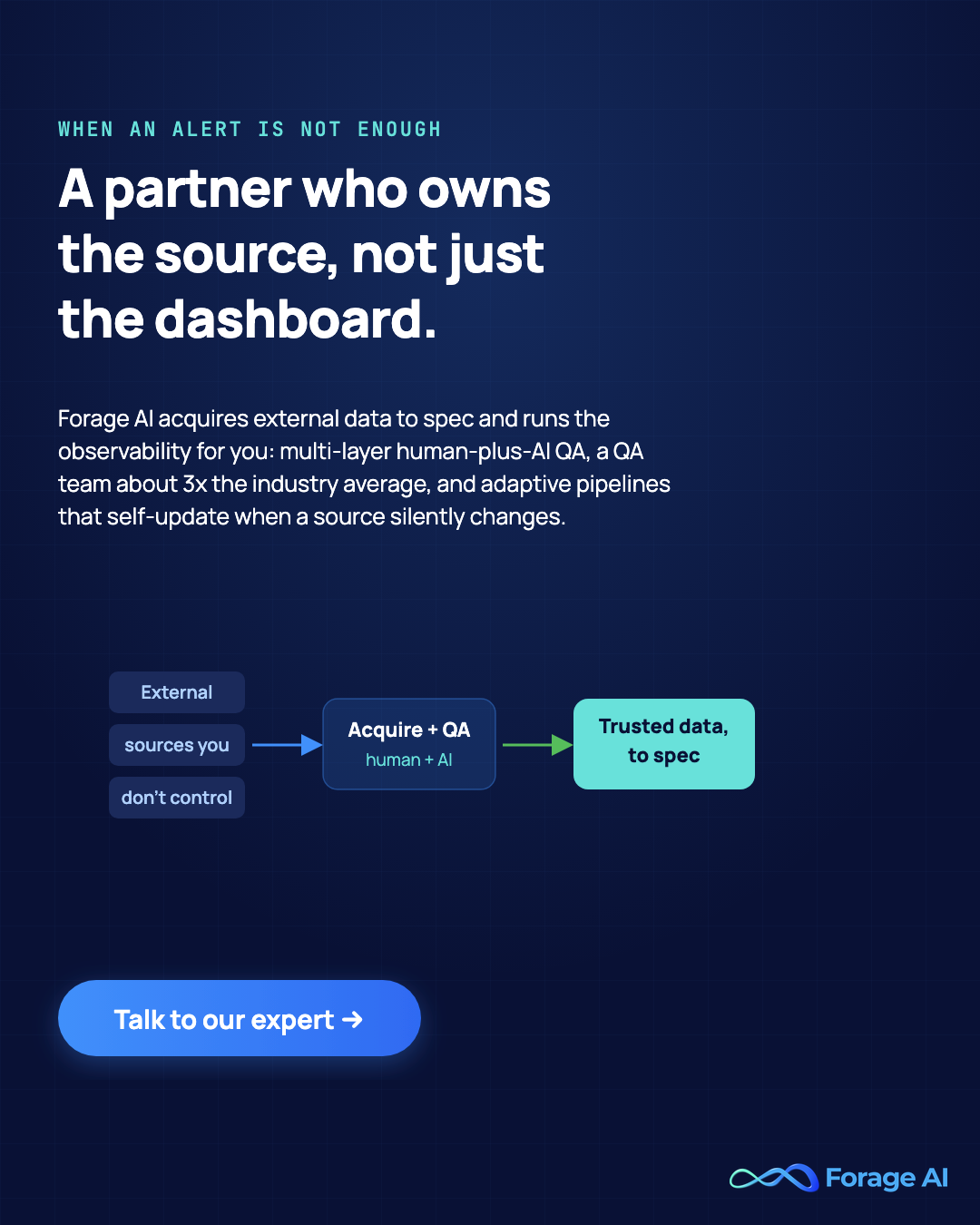
Forage AI is a managed external-data partner, not a tool you operate. Where every entry above watches the table after the data lands, Forage owns the source side: source discovery, extraction, multi-layer QA combining automated and human review, pipeline monitoring and maintenance, and adaptive pipelines that update when a source changes shape. The difference is detection versus ownership. A tool tells you a vendor feed broke. A partner re-extracts, re-maps, and delivers the fixed data, closing the gap the five pillars expose but cannot repair. For the underlying model, see resilient managed extraction pipelines and buying data as a managed service.
The honest framing: this is a partnership, not a SaaS dashboard. When a vendor or source change breaks a feed, the work is to catch it in QA and repair it before the data reaches you, rather than surface an alert and leave the re-extraction to your team.
Who it’s for: teams whose recurring pain is external, third-party, or web-extracted data, and who would rather own outcomes than operate yet another tool.
Watch-out: it is a managed model, not self-serve, so it is the right fit only when you want someone accountable for the fix, not just the alert.
Quick Summary
Q: When should you hand external-data quality to a managed partner instead of buying an observability tool?
A: When the recurring pain is the source itself (vendor feeds, partner APIs, or web-extracted data that keep breaking) and you want someone accountable for re-extracting and fixing it, not just an alert telling you it broke.
Data Observability Tools Compared
Here is every tool in this guide on the same decisive columns, so you can scan the whole field at once before going deeper on the two or three that fit your external-data failure mode.
| Tool | Category | Model | External-data fit | Pricing model | Rating / Reviews | Best for | Watch-out |
|---|---|---|---|---|---|---|---|
| Monte Carlo | General platform | Platform | Broad after land; warehouse-centric | Contact-sales, volume/asset | 4.3 (G2, ~489) | Broadest mature coverage | Price; opaque pricing |
| Bigeye | General platform | Platform | Metric/SLA granularity; warehouse-centric | Contact-sales, tiered | 4.1 (G2, ~22) | SLA-driven checks | Small community; setup |
| Anomalo | General platform | Platform | ML catch on noisy external tables | Contact-sales | 4.4 (G2, ~41) | No-rules ML detection | Alert noise; opaque pricing |
| Sifflet | General platform | Platform | Lineage + business-risk triage | Contact-sales, usage | 4.6 (G2, ~45) | Business-context triage | Younger platform |
| Acceldata | General platform | Platform | Reconciliation across sources | Volume/credit, contact-sales | 4.5 (G2, ~56) | Quality + infra + cost | Complexity; enterprise price |
| Validio | General platform | Platform | Real-time, data-in-motion | Contact-sales | 5.0 (G2, ~16) | Live feeds, real-time | Few reviews |
| Telmai | General platform | Platform | Strong: in-flight JSON/Parquet, pre-land | Contact-sales / marketplace | Listed; rating not verified | Semi-structured external data | Thin review signal |
| Metaplane (by Datadog) | dbt-native | Platform | Warehouse/dbt-centric, after land | Datadog packaging; historically per-table | 4.8 (G2, ~65) | Mid-market dbt shops | Per-table cost at scale |
| Elementary | dbt-native | Open source | dbt-source freshness, as far as dbt sees | OSS free; Cloud paid | ~2.4k GitHub stars | Cheap dbt-native observability | dbt-bound |
| Great Expectations | Open-source | Open source | Strong: assert raw payloads at ingest | OSS free; GX Cloud paid | ~11.6k GitHub stars | Code-first validation | Setup complexity |
| Soda / Soda Core | Open-source | Open source | Strong: SodaCL checks at ingest | OSS free; Soda Cloud paid | G2 Leader; rating not verified | Declarative checks + cloud | Cloud upsell |
| dbt tests | Open-source | Open source | Source-freshness on dbt sources only | Free (dbt Core) | Widely adopted | A free first guardrail | Point-in-time, not observability |
| Datafold | Pipeline/ingest | Platform | Catches your code changes, not source drift | Contact-sales / tiered | Listed; rating not verified | Pre-prod data-diff/CI | Learning curve |
| IBM Databand | Pipeline/ingest | Platform | Run-level (did the job finish) | Contact-sales (IBM) | 4.3 (G2, ~66) | IBM/Airflow shops | Onboarding; enterprise price |
| Unravel | Pipeline/ingest | Platform | Infra/cost lens, not data quality | Contact-sales | Listed; rating not verified | Platform cost + performance | Not quality-first |
| Atlan | Catalog/lineage | Platform | Maps where it flows; aggregates, not detects | Contact-sales | 4.6 (G2, ~131) | Governance + lineage | Catalog-first |
| Collibra | Catalog/lineage | Platform | Governance-first; observability a module | Contact-sales (enterprise) | 4.2 (G2, ~102) | Regulated enterprises | Heavyweight |
| Forage AI | Managed external-data | Managed | Owns the source: detects and fixes | Custom managed engagement | No public review base | Owning external-data quality end to end | Partnership, not self-serve |
Quick Summary
Q: Which data observability tool fits external data best?
A: It depends on the failure mode. Telmai and Validio fit live external feeds, Great Expectations and Soda Core validate raw payloads at ingest, Atlan and Collibra map lineage across vendors, and a managed partner like Forage AI owns the source side when the recurring pain is the source itself rather than the alert.
How to Choose a Data Observability Tool for External Data
Now that the field is in front of you, here is the repeatable method to narrow it. The mistake to avoid is buying the category leader by default; the right tool depends on whether you control the source and which pillar fails most.

Gate one: do you control the source? If the data is your own warehouse and dbt models, almost any tool here works and you optimize for fit and price. If it is a vendor feed, partner API, or web-extracted source, prioritize tools that validate at ingest and model freshness against the vendor’s cadence, because the cause of a break sits where you cannot reach it.
Gate two: which pillar fails most? Be honest about your dominant failure mode. Freshness, when a feed silently stops refreshing. Volume, when a scrape halves. Schema, when a source changes shape. Distribution, when values quietly change meaning. Lineage, when you cannot trace a bad number to its feed. The pillar that hurts most points to the category.
Gate three: detection only, or detection plus the fix? A tool detects. It hands you an alert and a human still re-extracts or chases the vendor. Decide whether an alert is enough or whether you need someone accountable for the repair, because that single question separates a tool purchase from a partnership.
Gate four: build, buy, or partner? Map your answers to the categories. A dbt shop wanting native speed goes to the dbt-native tools. A team needing ML anomaly detection on noisy external data goes to Anomalo, Telmai, or Validio. A team wanting free, code-first ingest checks goes to Great Expectations or Soda Core. A team needing lineage and governance goes to Atlan. And a team that needs someone to own the fix goes managed. For the broader trade-off, see tools versus managed providers and buying data as a managed service.
This matters because the cost of getting it wrong is not abstract. Industry surveys have long reported that data teams spend a large share of their time firefighting bad data and maintaining pipelines, and schema drift on upstream sources is a recurring driver of that load. A method beats reacting to the next broken feed.
Quick Summary
Q: How do you choose a data observability tool for data you don’t control?
A: Start from the source. If you do not own it, prioritize tools that validate at ingest and model freshness against the vendor’s cadence, pick by which pillar fails most, then decide whether you need detection only (a tool) or detection plus the fix (a managed partner).
FAQ
What is the difference between data observability and data quality? Data quality is the broad discipline of making data fit for use, including the standards, rules, and remediation behind it. Data observability is the continuous, baseline-aware monitoring that tells you the health of your data across freshness, volume, schema, distribution, and lineage, so you catch a break early. Observability is how you watch quality over time, and a one-off data test is narrower still: a point-in-time assertion you wrote, not continuous monitoring.
What are the best open-source data observability tools? Great Expectations and Soda Core lead for external data because they validate raw payloads as code at ingest, before anything is trusted. Elementary is the strongest dbt-native open-source option, and dbt tests (extended by dbt-expectations) are a free first guardrail every dbt team already has. The external-data caveat is the same across all of them: assert the third-party payload at the boundary, not after it has landed.
What are the best Monte Carlo alternatives? It depends on the gap you are filling. For broad enterprise coverage, Acceldata and Bigeye compete directly. For no-config ML anomaly detection, Anomalo. For real-time and data-in-motion on live feeds, Validio. For semi-structured external data before it lands, Telmai. For fast dbt-native monitoring, Metaplane by Datadog. Choose by the failure mode that hurts most, not by brand prestige.
How do I monitor data freshness for a third-party or external source? Model the vendor’s promised refresh cadence as a freshness SLA and alert when the feed breaches it, which is a different check from “your job ran.” If the source promises a daily refresh, the SLA should fire when the data is older than that window, regardless of whether your pipeline executed successfully. Tools with strong freshness handling and ingest validation, like Telmai, Soda, or Great Expectations, fit this best.
What are the best data observability tools for Snowflake? Most platforms here connect to Snowflake, but the dbt-native and modern-data-stack tools are built for it: Metaplane by Datadog and Elementary give fast, native coverage if your external data already lands in Snowflake through dbt. For broader ML monitoring across a Snowflake estate, Monte Carlo, Anomalo, and Acceldata all fit, and Unravel adds the cost and performance lens.
How do you choose a data observability tool? Start with whether you control the source, identify which of the five pillars fails most often, and decide whether you need detection only or detection plus the fix. Then map those answers to a category: open-source checks for code-first ingest validation, a general platform for ML anomaly detection, dbt-native for a modern data stack, catalog and lineage for governance, and a managed partner when the source itself is the recurring problem.
Conclusion
Every tool in this guide is good at the same thing and limited in the same way: it watches the data after it lands and tells you when something looks wrong. That is genuinely valuable, and for data you own, it plus a fix loop is the whole answer. The limit only bites on data you do not control, where the alert arrives but the cause sits upstream beyond your reach.
So the choice gets simpler once you frame it right. Pick the tool that fits your dominant external-data failure mode, validate raw payloads at ingest rather than trusting them, and model freshness against the vendor’s cadence instead of your own jobs. And when the recurring problem is the source itself, the honest move is to stop buying another dashboard and have someone own the source side, the extraction, the QA, and the fix, so a broken feed becomes their problem to repair rather than yours to keep discovering.
Related Articles
- Data Observability for Third-Party Datasets: What You Need to Know: The concept and practices behind monitoring external data, the foundation this tools guide builds on.
- Why RAG Pipelines Fail in Production: A Data-Quality Diagnosis: How stale, drifting source data breaks downstream systems.
- Data Extraction Automation: From Fragile Scripts to Resilient Managed Pipelines: The managed-pipeline model behind owning the source side.
- What Is Data as a Service (DaaS)? A Practical Guide for Buyers: When buying data as a managed service beats operating tools.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




