

A portfolio manager calls down to the data desk with a question that sounds simple: is the quarter tracking ahead of consensus or behind it, and can we know before the print?
The earnings call is three weeks out. The 10-Q is history. Everything in the regulated reporting stack describes a quarter that already closed.
That gap between what is happening and what gets reported is the entire reason alternative data exists. It is the credit card panel that shows last week’s spend, the satellite pass that counts cars in a parking lot today, the job postings that reveal a hiring surge a company has not announced. Information that describes the present, pulled from outside the financial reporting system.
Ten years ago that was a quant-fund specialty. Today it is plumbing. 85% of leading hedge funds run at least two alternative datasets, and the question is no longer whether to use it but how to source it without the program falling over.
This guide is written for the people on both ends of that phone call. It covers what alternative data is, the categories worth knowing, how investment teams actually put it to work, and the part most guides skip: what it takes for a data team to deliver it reliably, run after run. Both sides decide whether a program survives contact with production. Most guides cover one and quietly drop the other.
Quick Digest
- What alternative data is: any information used in investment research that originates outside traditional financial sources like earnings reports, SEC filings, and economic indicators
- Why it matters: traditional data is backward-looking and universally available; alternative data captures present-tense, real-world behavior, and the lag between event and official report is where the edge sits
- The five categories: transaction and consumer data, web and digital data, geolocation and satellite imagery, sentiment and social data, and workforce signals
- It is now standard: 85% of leading hedge funds use at least two alternative datasets. As of 2026, this is infrastructure, not an emerging technique
- How teams use it: to generate alpha before markets move, sharpen earnings predictions, and build macro and sector-level intelligence
- What the data team owns: sourcing alt data reliably is an engineering problem as much as an analytical one, spanning extraction, cleaning, QA, delivery, and maintenance
- Three sourcing paths: buy from a marketplace, build in-house pipelines, or work with a managed data partner, each with real cost and control tradeoffs
- Quality and compliance: data quality and legal review (particularly MNPI, GDPR, and CCPA) are prerequisites, not afterthoughts
What Is Alternative Data?
Alternative data is data used to evaluate a company or investment that does not come from traditional sources such as financial statements, SEC filings, management presentations, or press releases. Put plainly: it is non-traditional data used in the investment process.
That definition comes from Eagle Alpha, one of the recognized authorities on the alternative data industry. We keep coming back to it because it cuts through a lot of noise about what does and does not count.
Traditional vs. Alternative: What Is the Difference?
The cleanest way to see what makes data “alternative” is to start with what traditional financial data actually is.
Traditional financial data is what investment professionals have always worked from: quarterly earnings, balance sheets, income statements, SEC filings, government economic indicators, and analyst research. It is structured, regulated, and universally accessible. Every investor reads the same earnings transcript at the same moment. The data is reliable, and it carries two limitations any team relying on it eventually runs into.
First, it looks backward. It tells you what already happened, usually with a lag of weeks or months between the real-world event and the moment the number is published.
Second, because everyone receives it simultaneously, whatever edge it once carried has been competed away.
Alternative data behaves differently. It comes from outside the reporting system: consumer behavior, physical activity, digital interactions, real-time market signals. A credit card transaction dataset shows what consumers spent on last week, not what a company reported selling last quarter. Satellite imagery of a retailer’s parking lots shows how busy those stores are right now, not how many shoppers turned up during the last reporting period.
The distinction that matters is timing and source. Traditional data reports on the past through regulated channels. Alternative data captures the present through non-traditional, often unstructured sources.

What Alternative Data Is Not
This question surfaces on nearly every program we have worked on, and getting it wrong creates real legal exposure.
Alternative data is not insider information. It is not proprietary company data shared without consent. And it is not a way around securities law.
Legitimate alternative data is derived from publicly observable behavior, properly licensed datasets, or legally collected web and transaction information, with documented compliance frameworks behind it. The line between legal alternative data and illegal insider information sits under active regulatory scrutiny, which the compliance section below covers in detail.
Expert Insights
“98% of investment managers now agree that traditional financial data is too slow to reflect changes in economic activity.”
Source: Coalition Greenwich, 2025
Quick Summary
Q: What makes alternative data different from the data investment teams already use?
A: Alternative data captures real-world behavior in near real-time from sources outside the financial reporting system. Traditional data reports on the past through regulated channels; alternative data reflects the present through consumer transactions, satellite imagery, web activity, and other non-traditional signals. The difference is timing and source, and that gap is where the informational advantage lives.
A Brief History: From Niche Experiment to Industry Standard

Alternative data is not a new idea. What is new is its scale and accessibility.
In the early 2000s, only the most sophisticated quant funds (quantitative hedge funds that lean heavily on data and models to drive decisions) experimented with non-traditional signals. Satellite imagery, shipping data, and credit card panels existed, but they were expensive to acquire, painful to process, and demanded serious data science infrastructure to turn into usable investment inputs. The barrier to entry was high enough that only a handful of well-resourced firms could play.
The 2010s changed that. The explosion of digital data from mobile devices, social platforms, e-commerce, and connected sensors opened up an entirely new universe of sources. At the same time, cloud computing collapsed the cost of storing and processing large datasets, and data marketplaces made it possible to buy alternative data without building the collection infrastructure yourself.
By the mid-2020s the market had transformed. Alternative data spending by investment management firms was projected to top $15.4 billion in 2025, on a path toward nearly $40 billion by 2030, according to Neudata’s 2025 report. As of 2026 that trajectory is holding: 85% of investment managers expect their alternative data budgets to keep rising, and a third forecast substantial growth.
Here is what we tell teams about the shift. The edge is no longer in having alternative data. It is in having the right data, sourced reliably, and folded into decisions more effectively than your competitors manage.
The short version of how we got here:
| Era / milestone | What changed | Why it matters |
|---|---|---|
| Early 2000s: niche experiment | Only sophisticated quant funds tested non-traditional signals; the data was costly and infrastructure-heavy. | The edge belonged to a handful of well-resourced firms. |
| The 2010s: mainstreaming | Mobile, social, e-commerce, and sensors created a data explosion; cloud costs fell and data marketplaces appeared. | Firms could buy datasets instead of building collection. |
| Today: industry standard | Most leading hedge funds run multiple alternative datasets, and budgets keep rising. | The edge moves from having alt data to sourcing the right data reliably. |
Expert Insights
“Alternative data spending by investment management firms could top $15.4 billion in 2025, and could potentially reach nearly $40 billion by 2030.”
Source: Neudata, 2025
Quick Summary
Q: Has alternative data always been this mainstream?
A: No. For most of its history, alternative data was a quant-fund-only capability: expensive, technically demanding, and out of reach for most investment teams. Digital data proliferation and cheaper cloud infrastructure collapsed that barrier across the 2010s. Today it is standard infrastructure, not a competitive edge in itself.
The Main Categories of Alternative Data

Alternative data is not one type of information. It is a broad category spanning dozens of distinct dataset types, each capturing a different dimension of real-world activity. Knowing the main categories is the first step to deciding which ones deserve your team’s attention.
Here is how the main categories line up when we map them for a team.
| Category | What it is | Example data sources | Who uses it / signal it gives |
|---|---|---|---|
| Transaction and consumer data | Card purchases, point-of-sale, mobile payments, and consumer panels showing real spending. | Credit card transaction datasets, consumer panels. | Hedge funds reading near real-time spend before earnings. |
| Web and digital data | Listings, pricing, job posts, company info, reviews, news, and app rankings from the open web. | E-commerce platforms, corporate websites, review sites. | Competitive and pricing intelligence, hiring trends; also feeds the other data types. |
| Geolocation and satellite imagery | Satellite photos and anonymized mobile-location signals tracking physical activity. | Satellite imagery of lots and oil tanks, mobile geolocation providers. | Foot-traffic and supply reads before official inventory reports. |
| Social media and sentiment data | Sentiment from social, news, and earnings transcripts scored into structured signals. | Social posts, financial news, earnings-call transcripts. | Quant funds running event-driven strategies. |
| Workforce and emerging categories | Job postings, app usage, ESG signals, and IoT sensor data. | Job-posting aggregators, app-store data, sensor networks. | Hiring velocity flags growth; app rankings proxy adoption. |
Transaction and Consumer Data
Transaction data, drawn from credit card purchases, point-of-sale systems, mobile payment apps, and consumer panels, is consistently one of the most valuable categories for investment research.
The reason is direct: it reflects what consumers are actually spending, not what a management team says it sells. That gap matters most in the weeks before earnings, when traditional data gives almost no read on the quarter.
During the COVID-19 pandemic, hedge funds tracking credit card transaction data in real time watched the shift in consumer spending toward e-commerce as it happened. They built positions on what consumers were demonstrably doing, weeks before the earnings surge showed up in official reports.
Here is the part a data team has to watch. Transaction panels vary widely in coverage, and that variation is load-bearing. A dataset representing 5% of US credit card transactions tells a very different story about consumer behavior than one covering 40%. Coverage, methodology, and sampling approach are the quality variables to assess before you let a panel touch a position.
Web and Digital Data
Web data plays two roles at once: it is a category of alternative data in its own right, and the primary mechanism for collecting many of the others.
Web data is also how many other categories get sourced. When a firm tracks pricing across hundreds of e-commerce platforms, monitors hiring at thousands of companies, or aggregates news sentiment globally, the underlying method is typically web scraping: the automated extraction of information from websites at scale.
That dual nature changes how you think about quality and freshness. Web-sourced data is only as reliable as the infrastructure that extracts it: a scraper that runs weekly gives you a weekly snapshot, a daily pipeline gives you daily signals, and that cadence gap is the difference between a signal you can trade on and one you cannot.
Geolocation and Satellite Imagery
Satellite imagery and geolocation data give you a view of economic activity that is entirely independent of what companies choose to report.
The best-known examples come from retail and energy. UBS analysts used satellite photographs of Walmart parking lots to estimate customer foot traffic ahead of earnings, gauging revenue performance before the official release. Orbital Insight used satellite imagery to monitor the fill levels of oil storage tanks at facilities worldwide, giving energy-focused teams early intelligence on global supply conditions before official inventory reports landed.
Geolocation data from mobile devices extends this further. By aggregating anonymized location signals from phones, providers estimate foot traffic at retail locations, attendance at industrial facilities, and population movement trends in near real-time.
Be honest about one thing: raw satellite imagery and location signals are not investment-ready when they land. They need a processing and analytics layer to become structured, interpretable signals, and that is a non-trivial engineering problem. The value of this category depends heavily on the quality of that analytics layer, which is where most of the cost and most of the risk actually sit.
Social Media and Sentiment Data
Sentiment data captures how people feel about companies, products, markets, and macro events, drawn from social platforms, news feeds, earnings call transcripts, and online communities.
Providers process thousands of news sources and social posts into structured sentiment scores and event classifications that quant funds feed straight into their models. Instead of reading financial news by hand to gauge market mood, a team gets a continuously updated, numerically structured signal (sentiment polarity, message volume, topic clustering) at per-minute or per-hour granularity.
This category earns its keep on event-driven strategies: catching early signals around product launches, regulatory actions, leadership changes, or reputational events before they are fully reflected in asset prices.
Workforce and Emerging Categories
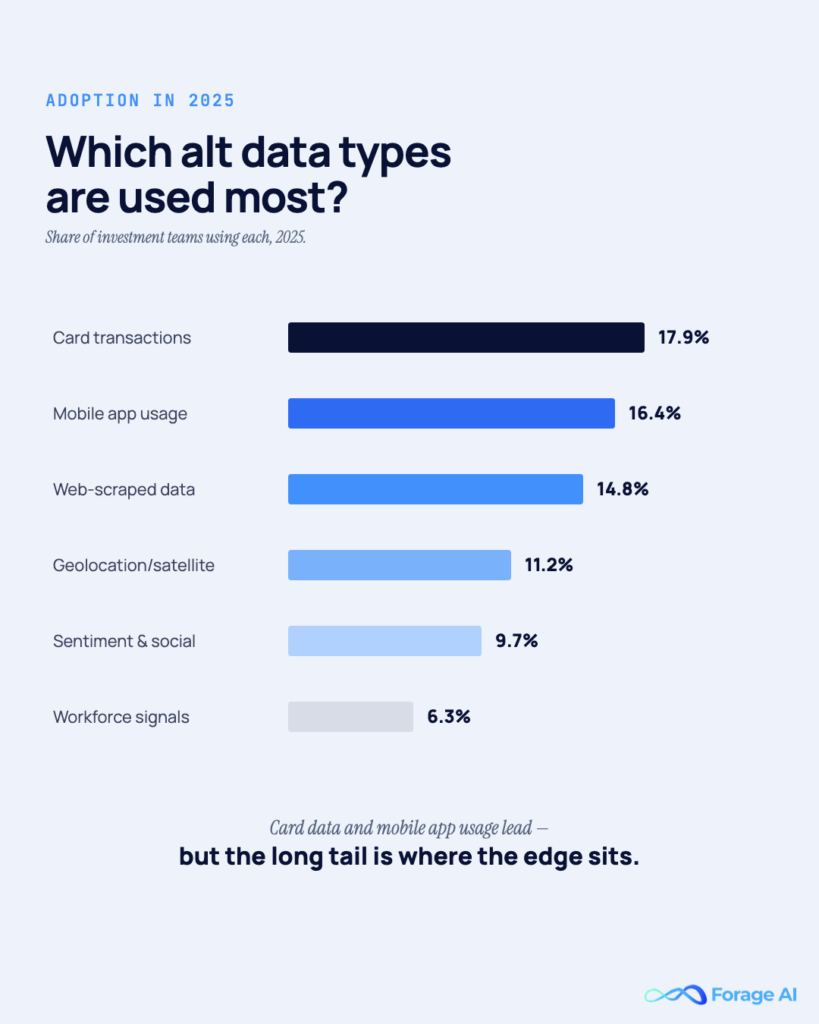
Workforce and hiring data, extracted from job postings at scale, has become a meaningful signal. The volume of a company’s postings, the seniority levels it is hiring for, the specific skills it is chasing, and the velocity at which it is adding headcount all tell a story about growth trajectory and operational health that earnings reports lag behind. A company quietly posting 200 engineering listings in a quarter is signaling something its public communications may not yet reflect.
Beyond hiring, app usage data (mobile download rankings and estimated daily active user counts) has become a proxy for product adoption. ESG and environmental signals from non-traditional sources are increasingly material to institutional mandates. IoT and sensor data from shipping containers, weather stations, and industrial facilities is relevant for commodity and logistics-focused strategies.
Expert Insights
“Credit and debit card transactions lead alternative data usage at 17.9% of data type adoption in 2025; mobile app usage follows at 16.4%; web scraped data at 14.8%.”
Source: Neudata / Funds Europe, 2025
Quick Summary
Q: What are the main types of alternative data?
A: Five core categories: transaction and consumer data, web and digital data, geolocation and satellite imagery, sentiment data, and workforce signals. Transaction data and web data are currently the most widely adopted. Most investment programs run several categories at once. Each captures a different dimension of real-world activity, and they are most powerful in combination.
How Investment Teams Use Alternative Data

We have covered what alternative data is and what the categories look like. The practical question for any team is the next one: what do you actually do with it?
The answer is not one thing. How alternative data gets used depends on the strategy, the data category, and the specific signal you are trying to extract. But three application patterns account for most of the work.
Here is how those three patterns line up at a glance.
| Use case | Data type used | Who | Example outcome |
|---|---|---|---|
| Generating alpha before market moves | Transaction, web, and sentiment data. | Hedge funds and quant funds. | Positions built weeks before earnings; a real share of quant performance credited to alt data. |
| Improving earnings prediction accuracy | Transaction data, web traffic, app usage, hiring signals. | Analysts building earnings models. | A one to two week read that sharpens forecasts before pricing and positioning. |
| Macro and sector-level intelligence | Shipping, satellite-monitored storage, aggregated hiring and spending. | Systematic and macro funds. | Early signals on supply chains, sector shifts, and demand before official figures. |
Generating Alpha Before the Market Moves
The primary use case in investment management is alpha generation: capturing returns not explained by broad market movements, by acting on information before it is priced in.
85% of leading hedge funds now use at least two alternative datasets, and nearly a third of quant funds attribute more than 20% of their performance to alternative data, according to industry research published in 2025.
For more on how AI-powered extraction is changing the way investment firms access market data, see our guide on how AI transforms market data extraction for investment firms.
Improving Earnings Prediction Accuracy
Traditional earnings models lean on analyst estimates derived from management guidance, industry data, and historical trends. Their weakness is that they depend heavily on what the company chooses to disclose and on analyst judgment.
Alternative data adds a real-time empirical layer: consumer spending from transaction data, web traffic trends, app usage metrics, and hiring signals that show how a company’s business is actually running in the weeks before an announcement. Options pricing and portfolio positioning for earnings events typically happen well before the report date, so a timing advantage of even one to two weeks in forming an accurate earnings view can translate into a meaningful edge.
Macro and Sector-Level Intelligence
Alternative data is not only for single-stock analysis. Systematic and macro-oriented funds use it to build intelligence at a market or sector level.
Shipping data and satellite-monitored commodity storage levels give early signals on supply chain conditions and global inventory builds. Hiring trend data aggregated across thousands of companies in a sector shows whether an industry is expanding or contracting before government agencies publish quarterly employment figures. Consumer spending trends across retail categories flag shifts between discretionary and non-discretionary demand ahead of consumer confidence surveys.
Expert Insights
“63% of investors plan to increase their alternative data outlays, driven in part by the growing role of generative AI in investment research and portfolio construction.”
Source: Coalition Greenwich, 2025
Quick Summary
Q: Why do investment teams pay so much for alternative data?
A: Because it buys a timing advantage. Alternative data reveals what is happening in the real world before that signal shows up in regulated financial reports, and the lag between the event and the official release is where the edge lives. Teams that act on accurate, timely signals before they are widely priced in tend to generate better risk-adjusted returns.
What the Data Team Actually Has to Solve

Most writing about alternative data centers on the investment analyst reading the signal. A second question gets far less attention and matters just as much: how does the data actually get there?
Behind every signal that reaches an analyst’s model sits a data operation responsible for getting that data there continuously and at scale. This is the data team’s job, and it is a considerably harder one than it looks from the consumption side.
Alternative data does not arrive pre-packaged. It comes from sources that were never built to be data sources: websites that change without notice, transaction networks with inconsistent formats, satellite imagery that needs computer vision processing, and social platforms behind rate-limited APIs.
Turning raw alternative data into a reliable, queryable dataset comes down to a set of ongoing operational steps:
- Source identification: finding the sources that actually contain the signal you need
- Extraction: collecting data from those sources at the required frequency, often daily or more
- Cleaning and structuring: normalizing inconsistent formats, filling gaps, removing noise
- Quality assurance: validating that what was collected is accurate, complete, and consistent with prior runs
- Delivery: getting structured data into the systems where analysts and models consume it
- Maintenance: keeping the pipeline running when source websites change, APIs deprecate, or data formats shift
Every one of these steps needs dedicated infrastructure, engineering effort, and ongoing operational management. The maintenance burden is the one that catches teams off guard: 10–15% of scrapers require weekly fixes due to website DOM shifts, fingerprinting, or endpoint throttling. We see this play out on nearly every in-house program that scoped the build but not the upkeep.
This operational dimension is why alternative data is both an analytical discipline and an engineering one. How you source and maintain your data matters as much as which data you choose. For a deeper look at what financial data extraction involves at scale, see our guide to financial data extraction for investment teams.
Expert Insights
“10–15% of scrapers need weekly fixes due to DOM shifts, fingerprinting, or endpoint throttling, a maintenance burden most teams significantly underestimate when scoping in-house alternative data programs.”
Source: Web Scraping Industry Report, 2025
Quick Summary
Q: Is getting alternative data as simple as buying a subscription?
A: For off-the-shelf marketplace datasets, the sourcing is handled for you. But continuously updated, custom alternative data needs a sourcing infrastructure: extraction, cleaning, quality assurance, delivery, and ongoing maintenance as sources change. That operational complexity is consistently underestimated by teams scoping their first in-house program.
How to Source Alternative Data


Investment and data teams have three primary paths to acquiring alternative data, each with real tradeoffs between cost, customization, control, and operational burden.
Buying from Data Marketplaces and Providers
The fastest path is buying directly from a vendor or marketplace. Providers sell access to curated datasets (sentiment feeds, consumer transaction panels, satellite imagery analytics, web traffic data) that can often be ingested within days or weeks of contract signature.
What works: Immediate access. No extraction infrastructure to build or maintain. Reputable providers document their data sourcing and consent frameworks, which simplifies compliance reviews.
What to consider: The same dataset is available to every firm that can pay for it, so the signal is not proprietary. Coverage and schema are fixed by the provider, which means you get what they collect, not necessarily what you need. Update frequency is set by the provider’s schedule, which may or may not line up with your model’s requirements.
Marketplace sourcing makes the most sense when speed to market matters more than proprietary edge, or when a standardized dataset from an established data provider is genuinely sufficient for the use case.
Building In-House Extraction Pipelines
For teams that need data not on the market, or that want a proprietary collection advantage, in-house pipelines give full control over what is collected, how often, and in what format, which for teams with specific requirements and engineering capacity can become a real competitive moat.
Be honest about the challenge: maintenance runs heavier than most teams expect. Procurement costs alone run $50,000–$500,000 per data feed. Beyond that, website structures change, anti-bot systems evolve, and the proxy management, browser automation, and extraction logic required to keep a production-grade scraper running reliably demand continuous engineering attention.
In-house is the right call when the data requirement is genuinely proprietary, the team has engineering capacity for ongoing maintenance (not just the initial build), and owning the collection layer justifies the operational cost.
Working with a Managed Data Partner
The third option is a managed data partner, chosen by firms that need custom, continuously updated data without the engineering overhead.
A managed partner takes end-to-end responsibility for the pipeline: the client defines what data they need, and the partner handles source identification, extraction, cleaning, quality assurance, and delivery into the client’s systems.
This model separates the team’s data requirements from the engineering burden of maintaining the infrastructure. It fits teams needing data from sources that change frequently, require high refresh rates, or involve complex extraction across many sources at once.
For programs scaling across categories, geographies, or update frequencies, a managed partner provides operational depth an in-house team cannot match without significant headcount. For a broader look at automating financial data workflows, see our financial data automation guide.
Expert Insights
“66% of investment firms currently use third-party systems to access alternative data, compared to 51% relying on in-house solutions, reflecting a clear industry shift toward outsourced infrastructure as data programs scale in scope and complexity.”
Source: SSC Technologies, 2025
Quick Summary
Q: What’s the best way to get alternative data?
A: It depends on what you need. Marketplace datasets are fast and compliance-documented but not proprietary, so any competitor can buy the same signal. In-house pipelines give full control but carry significant maintenance costs. Managed data partners offer custom, continuously updated data with the operational burden outsourced. Most programs start with marketplace data and move toward custom pipelines as requirements get more specific.
Data Quality and Compliance: What You Need to Know

Alternative data is only valuable if it is accurate and legally obtained. Both dimensions take deliberate investment, and neither happens by default.
This section provides background information on regulatory and legal considerations. It is not legal or compliance advice. Consult qualified legal counsel before making compliance decisions about specific alternative data sources or programs.
Why Data Quality Is a First-Principles Problem
Raw alternative data is rarely investment-ready when it arrives: web data carries inconsistencies and gaps from source changes or extraction failures, transaction panels vary in coverage and sampling that is not always disclosed, and satellite imagery needs significant processing before it yields structured signals.
The quality of the signal you extract depends entirely on the quality of the pipeline behind it. A dataset that looks comprehensive on delivery can hide systematic biases, silent coverage gaps, or stale records that go unnoticed without rigorous validation.
Industry-standard quality assurance for alternative data runs in layers: automated validation (checking for structural consistency, expected field coverage, and anomaly detection), combined with human expert review for complex or high-stakes datasets. Multi-layer validation is the standard for data that influences investment decisions, not a premium feature.
Before integrating any dataset, we tell data teams to ask three questions: How does the provider validate data quality? How are source changes detected and handled? What is the documented error rate, and how are discrepancies resolved when they occur?
Material Non-Public Information (MNPI)
Material Non-Public Information (MNPI) is information that is both not publicly available and material to investment decisions. Trading on MNPI is a violation of securities law, regardless of how the information was obtained.
This matters for alternative data because some sources, even when marketed as “public” or “aggregated,” can carry signals that cross into MNPI territory. Where legal alternative data ends and illegal insider information begins sits under active regulatory scrutiny.
The SEC has explicitly scrutinized alternative data providers and the investment managers who use their products. The SEC’s examination focus includes whether fund managers received MNPI from alt data vendors and whether those managers have and enforce written policies to manage the risk. In practice, “advisers who obtain web scraped data, either directly or via vendors, should conduct additional diligence to confirm the data was obtained in a lawful manner,” per guidance from legal practitioners in this area.
Best practices for investment teams include documented due diligence on every provider’s sourcing methodology, legal review of vendor agreements, and written internal policies for evaluating new data sources before they enter the investment process.
Privacy Regulations: GDPR and CCPA
Alternative data categories that involve individual-level behavioral signals, such as transaction data, geolocation data, and app usage, intersect directly with privacy regulations.
The General Data Protection Regulation (GDPR) governs the collection and use of personal data across the European Union. The California Consumer Privacy Act (CCPA) imposes similar obligations for California residents. Both apply to data about identifiable individuals, which means consumer-level alternative data is not automatically outside their scope, even when purchased from a vendor.
For teams sourcing consumer-level data, the practical implication is that the underlying data must have been collected with appropriate consent, properly anonymized, and governed in line with applicable law. The compliance burden does not sit entirely with the provider. Investment managers carry obligations too.
The simplest risk mitigation is to work with providers who document their consent frameworks, anonymization practices, and third-party compliance audits. If a provider cannot explain how its data was collected and why it complies with privacy law, treat that as a signal worth taking seriously.
Expert Insights
“The SEC’s examination effort focuses on whether a private fund manager received MNPI from an alternative data vendor and whether the manager has and enforces policies and procedures designed to address the MNPI and other risks posed by the use of alternative data.”
Source: SEC / Schulte Roth & Zabel
Quick Summary
Q: What compliance issues do I need to know about before using alternative data?
A: Two main areas. First, MNPI risk: some alt data may carry signals that cross into insider information territory, and the SEC actively scrutinizes how investment managers manage this. Second, privacy law, which applies to consumer-level behavioral data under GDPR and CCPA. Both require documented compliance frameworks before a new data source enters the investment process. This is not a one-time legal review; it is an ongoing operational requirement.
Is Your Team Ready for Alternative Data?
The case for alternative data is compelling, but building a functioning program is not trivial. Before you commit budget and engineering resources, work through a few foundational questions.
What signal are you actually looking for?
The programs that succeed start with a specific investment question, not a general intention to use more data. What market dynamic, company behavior, or consumer pattern are you trying to observe? The clearer the signal, the easier it is to tell which data categories are worth evaluating and which are noise.
Do you have the infrastructure to ingest it?
Alternative data arrives in formats that look nothing like traditional financial data feeds: JSON files, raw HTML, irregular CSVs, and imagery files. If your data environment is built for structured financial data, adding unstructured alternative sources means real integration work that should be scoped before you commit to a purchase.
Have you completed a compliance review for new sources?
New data sources need legal review before they enter the investment process. This matters most for consumer behavioral data, where MNPI and privacy law overlap, and for providers with incomplete or opaque provenance documentation. The review should happen before integration, not after.
Are you buying a dataset or building a continuous pipeline?
These are two different operational commitments. A one-time dataset purchase is a finite project. A continuously updated pipeline is an ongoing capability that needs maintenance, monitoring, and sustained engineering or vendor management. Being clear about which one you need shapes the sourcing decision more than anything else.
For a deeper look at how to build and automate financial data workflows end-to-end, see our financial data automation guide.
Expert Insights
“Alternative data integration requires substantial investment in data science expertise, compliance measures, and analytical tools. Teams that underestimate this tend to see programs stall after the initial proof-of-concept.”
Source: Deloitte
Quick Summary
Q: How do I know if my team is ready to invest in alternative data?
A: Start with the signal question: what specific real-world behavior are you trying to observe, and which data category captures it? If you cannot answer that clearly, more data will not help. Then confirm your data infrastructure, compliance review process, and operational model before committing. The teams that get the most from alternative data tend to start narrow (one signal, one source, validated end-to-end) before scaling.
Frequently Asked Questions
What is alternative data in simple terms?
Alternative data is information used for investment research that comes from outside traditional financial sources. Not from earnings reports, SEC filings, or analyst research, but from sources like credit card transactions, satellite imagery, job postings, web activity, and social media sentiment. It captures real-world behavior in near real-time rather than reporting on what companies officially disclose, which is why investment teams use it to build a timing advantage over markets that are slower to reflect those signals.
What are the most common types of alternative data?
The most widely used categories are credit card and consumer transaction data (17.9% of data type adoption in 2025), mobile app usage data (16.4%), and web scraped data (14.8%), according to Neudata’s 2025 research. Satellite imagery and geolocation data, social media and news sentiment, and workforce and hiring data round out the major categories. Most investment programs run several categories at once rather than relying on a single source.
How do hedge funds use alternative data?
Primarily for three purposes: generating alpha by acting on real-world signals before they appear in official financial reports, improving earnings prediction accuracy using real-time behavioral signals, and building macro and sector-level intelligence. 85% of leading hedge funds now use at least two alternative datasets, and nearly a third of quant funds attribute more than 20% of their performance to alternative data. For a practitioner walkthrough of how funds source and evaluate these datasets, see our guide to alternative data for hedge funds.
Is alternative data legal?
Yes. Legitimate alternative data is derived from publicly observable behavior, properly licensed datasets, or legally collected web and transaction information. The key legal risks are Material Non-Public Information (MNPI), which can constitute a securities law violation, and privacy regulations such as GDPR and CCPA that apply to consumer-level behavioral data. Investment managers have an obligation to assess the legal status of any alternative data source before it enters their investment process. Working with providers that document their data sourcing and consent frameworks significantly reduces both risks.
How much does alternative data cost?
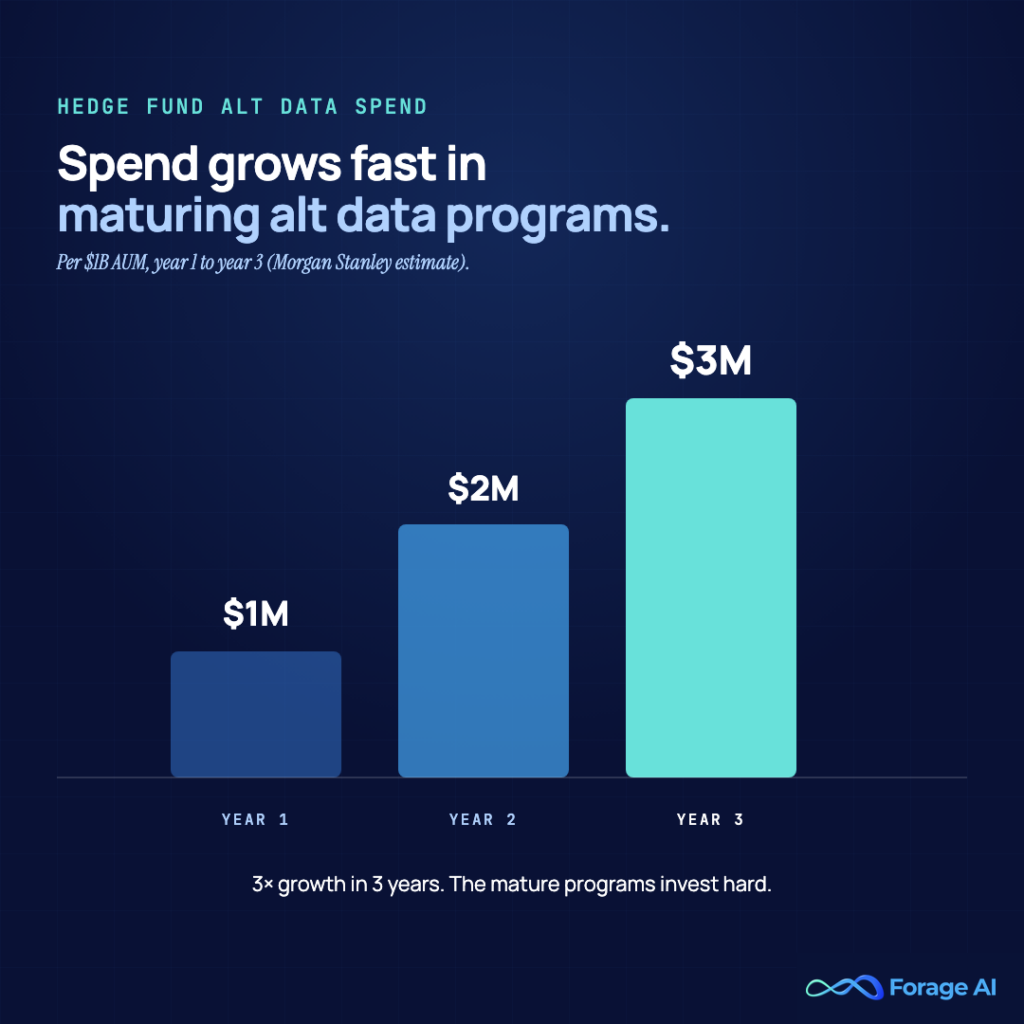
It varies widely by category, provider, and coverage. Individual data feed procurement typically runs $50,000 to $500,000 per feed, according to industry estimates. Morgan Stanley estimates that hedge funds spend approximately $1 million per $1 billion in AUM on alternative data in their first year, rising to $2 million in year two and $3 million in year three. Total alternative data spending across investment management was projected to exceed $15.4 billion in 2025, and continues to climb into 2026.
What is MNPI in the context of alternative data?
MNPI (Material Non-Public Information) is information that is both not publicly available and material to investment decisions. Trading on MNPI is a securities law violation, and the SEC actively scrutinizes whether investment managers who use alternative data have adequate policies to identify and manage MNPI risk. Some alternative data sources, even those marketed as “public” or “aggregated,” can carry signals that cross into MNPI territory. Investment managers should conduct legal due diligence on every new data source before it enters their investment process.
Conclusion
Alternative data has stopped being an edge. It has become infrastructure.
The 85% adoption rate among leading hedge funds is not a story about innovation. It is a story about standardization. As of 2026, the investment teams that are not using alternative data are the outliers.
But adoption is not the same as advantage. The firms generating consistent returns are not simply buying the same datasets as everyone else. They have a specific signal thesis, reliable sourcing infrastructure, and the operational depth to hold that advantage as sources change and programs scale.
For teams building or evaluating a program, the signal question and the sourcing question carry equal weight. What data captures the real-world behavior you are trying to observe? And how do you get it delivered cleanly, reliably, and at the frequency your models require?
That second question, the pipeline question, is where most alternative data programs hit their limits. Building and maintaining extraction infrastructure is an engineering discipline in its own right. For teams that need custom, continuously updated alternative data without that overhead, Forage AI provides fully managed extraction pipelines that handle everything from source identification through to validated, structured delivery, purpose-built for financial and investment data programs at scale.
Related Articles
- AI Financial Solutions: Build Complete Intelligence. Overview of AI-powered financial data solutions and market intelligence extraction
- What Is Data for AI?. Foundational guide to what constitutes data for AI systems and how different data types are used
─────────────────────────────────
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




