


Search “AI training data providers” and the same names stack into one ranked column: Scale AI, Appen, Sama, Bright Data, a rotating cast of synthetic data startups.
A single ranking implies a like-for-like comparison. The market data does not support one.
These vendors sit in four structurally different businesses, and the numbers show the gap between them is widening, not closing.
The figures make the categories concrete. Scale AI carries a valuation reported at roughly $29 billion and holds FedRAMP Moderate authorization, because high-stakes labeling commands a premium SLA tier. Bright Data publicly reports 17 billion-plus structured records across 215-plus pre-built datasets, because raw-feed infrastructure is a volume business.
Gretel was acquired by NVIDIA in March 2025 and folded into the NeMo stack, because synthetic generation is now a platform play. TELUS Digital was placed a Leader in Everest Group’s 2024 Data Annotation PEAK Matrix on 500-plus language coverage.
Four vendors, four cost structures, four buying motions. A flat top-10 averages them into one column and hides the exact distinction a buyer needs.
The single most expensive error in a 2026 training-data evaluation is comparing across categories that should never share a shortlist. A dataset marketplace, a labeling service, a custom sourcing partner, and a synthetic generator each clear a different bottleneck. Treating them as interchangeable is how an evaluation cycle ends in a signed contract that does not match the gap in the training program.
So the data leads, and the providers come first. Below are 19 named vendors, grouped by the four categories that carry the decision, each with a comparison table, a direct read on who it fits, and where the limits sit.
Forage AI sits at the top of the custom sourcing and extraction category because that is where we operate: managed, web-scale, multimodal training-data pipelines, built bespoke and run for the long term. The seven-axis evaluation framework and the IP-cleanliness checklist follow the list, once the names on the table are the right ones.
AI training data providers at a glance
Map your gap to a category, then to a vendor. Here is the full roster with a one-line “best for” each.
Custom data sourcing and extraction
- Forage AI – best for AI teams bottlenecked on getting to the data, not on labeling it. Managed end-to-end, web-scale, multimodal, provenance-tagged, no resell.
- Bright Data – best for buyers who want high-volume raw web feeds and tooling to manage acquisition themselves.
- Oxylabs – best for teams with strong internal data engineering who want managed infrastructure rather than a fully managed outcome.
- Innodata – best for buyers who want a public-company SLA and a vendor spanning data collection plus downstream labeling.
Labeling and annotation services
- Scale AI – best for high-stakes labeling at premium SLAs: autonomous vehicles, defense, frontier LLM alignment.
- Appen – best for language-coverage-heavy projects spanning many dialects.
- Surge AI – best for organizations training or aligning their own LLMs at scale.
- iMerit – best for projects where annotator qualification is the constraint: healthcare, AV, geospatial.
- TELUS Digital – best for global, multimodal labeling at enterprise scale.
- Sama – best for organizations that want a documented, auditable annotation chain, especially in computer vision.
- Cogito Tech – best for mid-tier multimodal labeling with mature compliance documentation.
Dataset marketplaces
- Datarade – best for early-stage scoping when you need to see what is out there before committing.
- Shaip – best for medical AI teams who need both licensed clinical datasets and matching annotations.
- Defined.ai – best for voice-AI and conversational model teams.
Synthetic data generators
- Gretel (NVIDIA) – best for teams already standardized on NVIDIA’s stack who need privacy-preserving synthetic data.
- MOSTLY AI – best for regulated industries needing synthetic versions of production records.
- Tonic.ai – best for teams where speed and developer experience are the priority.
- K2view – best for enterprises where synthetic data needs to feed live operational systems, not just offline training.
- Hazy – best for regulated tabular workloads: banking, insurance, customer records.
| If your gap is… | The category you want | Examples |
|---|---|---|
| Custom web-sourced or document-sourced training data, fully managed end-to-end | Custom data sourcing & extraction | Forage AI, Bright Data (feeds), Oxylabs (platform) |
| Annotating data you already have (bounding boxes, transcripts, preferences, RLHF) | Labeling / annotation | Scale AI, Appen, Surge AI, iMerit, TELUS Digital |
| An off-the-shelf corpus to start training fast | Dataset marketplace | Datarade, Shaip catalog, Defined.ai |
| Privacy-safe, augmented, or rare-event data | Synthetic data generator | Gretel (NVIDIA), MOSTLY AI, Tonic.ai |
Most teams need two of these, sometimes three. Pick the anchor category, the one tied to the biggest gap, and treat the others as supporting buys.

Custom data sourcing and extraction
This is the category most buyers do not register as a distinct discipline. Custom sourcing partners acquire training data at the source: websites, documents, public records, niche corpora. They extract it into structured form, run quality assurance, and deliver it as model-ready datasets.
The work spans crawling infrastructure, document parsing, schema design, and continuous refresh. It is the right category when the AI program is constrained by the data it can access, not by the data it can label.
Forage AI
| Best for | AI teams bottlenecked on getting to the data, not on labeling it |
| Key use cases | Web-scale and document-sourced training data, multimodal corpora, continuous-refresh pipelines |
| Pricing model | Scoped managed program (per-pipeline), not unit-priced per record |
| Licensing / compliance | Sovereign-by-design (no resell, no aggregation, no third-party LLM in the data path); SOC 2, GDPR, CCPA, HIPAA as required; you own the data outright |
| Data types & coverage | Text, images, structured records, documents, multimodal, across language |
| Standout strength | True managed delivery to your warehouse on schedule; QA team sized at ~3x industry average |
| Watch-out | Built for production-grade scope, not small-volume or short engagements |
Forage AI is where we operate, and we sit at the top of this category because the business was built around it. Forage AI is the managed custom AI training data partner: we acquire, extract, structure, and quality-assure web-scale training datasets bespoke to your model. Text, images, structured records, documents, multimodal, across modality and language.
The acquisition layer is our Custom Web Data Extraction service, the document side is our Intelligent Document Processing pipeline, and both feed a multi-layer QA stack.
Biggest strengths. True managed delivery: the data lands in your warehouse on schedule, at agreed quality, without your team touching a scraper, IDP template, or agent prompt. Twelve years of operational history, 500M+ websites crawled, 10M+ documents parsed. QA team sized at roughly 3x the industry average relative to delivery.
Sovereign-by-design contracts: no resell, no aggregation, no third-party LLM in the data path. Compliance posture covers SOC 2, GDPR, CCPA, and HIPAA, as the modality requires. You own the data outright.
Potential cons. Not built for small-volume or short-engagement work; the minimum scope is sized around production-grade pipelines. Higher upfront discovery cost than a per-record subscription, because the engagement is scoped to your specific fields, refresh cadence, and delivery format. If the gap is purely human labeling of an already-collected corpus, a labeling specialist is the better single-vendor fit, and we work alongside them rather than replacing them.
Best for: AI teams whose training program is bottlenecked on getting to the data, not on labeling it. The watch-out: the minimum scope is sized around production-grade pipelines, so a one-off, small-volume pull is the wrong fit.
Bright Data
| Best for | Buyers who want high-volume raw web feeds and tooling to manage acquisition themselves |
| Key use cases | Pre-built web datasets, self-serve web acquisition, large-scale proxy-based collection |
| Pricing model | Self-serve and subscription; scales with volume |
| Licensing / compliance | Public compliance program; procurement sometimes reviews residential proxy supply chain |
| Data types & coverage | 17B+ structured records across 215+ pre-built web datasets |
| Standout strength | One of the largest proxy networks in the market |
| Watch-out | Self-serve model means your team still owns the pipeline |
Bright Data publicly reports 17 billion-plus structured records across more than 215 pre-built web datasets, plus a self-serve acquisition platform. They sit at the infrastructure end of the custom sourcing category: you bring the engineering, they bring the proxies, scrapers, and dataset feeds.
Biggest strengths. One of the largest proxy networks in the market, and a useful reference point if you are comparing the top proxies for AI data extraction. Hundreds of pre-built web datasets for common targets. A self-serve platform that scales fast for engineering-capable teams.
Potential cons. The delivery model leans self-serve, so the in-house team still owns the pipeline. Pricing scales fast at production volume. Procurement and legal sometimes flag the residential proxy supply chain.
Best for: buyers who want high-volume raw web feeds and tooling to manage acquisition themselves. The watch-out: the self-serve model means your team, not the vendor, still owns and maintains the pipeline.
Oxylabs
| Best for | Teams with strong internal data engineering who want managed infrastructure |
| Key use cases | Large-scale web scraping, scraper APIs for high-friction targets, proxy management |
| Pricing model | Subscription and enterprise contracts with SLAs |
| Licensing / compliance | Strong enterprise compliance posture and SLA story |
| Data types & coverage | Web data at scale; 4,000+ listed partners |
| Standout strength | Mature managed proxy infrastructure with scraper APIs out of the box |
| Watch-out | Infrastructure plus tooling, not a fully managed outcome |
Oxylabs publicly lists more than 4,000 partners and operates a web scraping platform and proxy infrastructure for large-scale data extraction. The positioning is closest to Bright Data, infrastructure plus tooling, with a heavier emphasis on enterprise compliance and managed services.
Biggest strengths. Mature managed proxy infrastructure with a strong compliance posture. Scraper APIs cover common high-friction targets out of the box. A solid enterprise SLA story.
Potential cons. Like Bright Data, this sits closer to tools and infrastructure than to “you tell us what you need and we deliver it.” Strong internal data engineering is still required to turn the infrastructure into a training dataset.
Best for: teams with strong internal data engineering who want managed infrastructure rather than a fully managed outcome. The watch-out: it is infrastructure plus tooling, so you still need the engineering bench to turn it into a training dataset.
Innodata
| Best for | Buyers who want a public-company SLA and cross-category coverage |
| Key use cases | Data collection, supervised fine-tuning, red-teaming, annotation |
| Pricing model | Enterprise services contracts |
| Licensing / compliance | NASDAQ-listed (INOD); long history in regulated data environments |
| Data types & coverage | Cross-category: collection plus downstream labeling and alignment |
| Standout strength | Single vendor across multiple categories with a public-company SLA story |
| Watch-out | Pure-play custom sourcing depth varies by engagement; confirm the bench when scoping |
Innodata is a NASDAQ-listed (INOD) AI services company whose work spans data collection, supervised fine-tuning, red-teaming, and annotation. The breadth makes them a candidate for buyers who want a single vendor across multiple categories rather than stitching specialists together.
Biggest strengths. A public-company SLA story reassures procurement. Cross-category coverage: data collection plus downstream labeling and red-teaming. A long history of operating in regulated data environments.
Potential cons. The company is broad. Confirm the data-collection bench specifically when scoping, because pure-play custom sourcing depth varies by engagement. A larger company’s motion can mean slower onboarding than a specialist vendor’s.
Best for: buyers who want a public-company SLA and a vendor that can span data collection plus downstream labeling. The watch-out: pure-play custom sourcing depth varies by engagement, so confirm the data-collection bench before scoping.

Quick summary
Q: What is custom data sourcing and extraction, and when do you need it?
A: Custom data sourcing and extraction acquires training data at the source (websites, documents, public records), structures it to your schema, and delivers it model-ready. It is the right category when the AI program is constrained by the data it can access, not by the data it can label. The four named options split by delivery model: Forage AI runs the full pipeline as a managed outcome, Bright Data and Oxylabs supply infrastructure plus tooling for engineering-capable teams, and Innodata offers a public-company SLA across multiple categories. Match the delivery model to how much of the pipeline you want to own.
Expert insights
“The model and the code are basically a solved problem. Now that the models have advanced to a certain point, we’ve got to make the data work as well.” The data-centric AI movement Andrew Ng popularized holds that holding the model fixed and systematically improving the dataset is the more productive path to performance. For the custom-sourcing buyer, that reframes the spend: the gain is in the acquisition and structuring of the data, not in another round of model tuning.
Source: Andrew Ng, founder of DeepLearning.AI and Landing AI, in remarks on the data-centric AI approach (Scale Events / IEEE Spectrum, 2022).
Labeling and annotation services
Labeling vendors take data you already have and add structure to it. Bounding boxes on images, transcripts on audio, preference rankings on model outputs, span labels on text. RLHF, reinforcement learning from human feedback, is a labeling workflow, even though the deliverable is preference data rather than raw labels.
Labeling vendors fit best when the raw data is already collected and the bottleneck is human judgment at scale. They fit worst when the raw data does not exist yet.
Scale AI
| Best for | High-stakes labeling at premium SLAs |
| Key use cases | Autonomous-vehicle labeling, defense, frontier LLM RLHF and evaluation |
| Pricing model | Premium enterprise contracts |
| Licensing / compliance | FedRAMP Moderate authorization |
| Data types & coverage | Image, video, AV sensor data, text, preference data |
| Standout strength | Top-tier accuracy and SLA on high-stakes labeling |
| Watch-out | Price and contract motion can be heavy for smaller programs |
Scale AI is, per public coverage, valued at around $29 billion and holds FedRAMP Moderate authorization. Strongest in autonomous-vehicle labeling, defense, and frontier LLM workflows, including RLHF and evaluation. This is the premium tier of the labeling market.
Biggest strengths. Top-tier accuracy and SLA on high-stakes labeling. FedRAMP Moderate for federal workloads. A deep bench across frontier LLM evaluation, red-teaming, and RLHF.
Potential cons. The price tier tracks the SLA tier. Enterprise contract motion can be heavy for smaller programs. Less of a fit for low-volume, narrow-scope annotation work.
Best for: high-stakes labeling at premium SLAs, especially for autonomous vehicles, defense, and frontier LLM alignment. The watch-out: price and contract motion are heavy, so smaller or narrow-scope programs will overpay.
Appen
| Best for | Language-coverage-heavy projects spanning many dialects |
| Key use cases | Multilingual data collection and annotation, turnkey datasets, custom labeling |
| Pricing model | Project-based and enterprise contracts |
| Licensing / compliance | Long track record with global enterprise buyers |
| Data types & coverage | 235+ dialects; text, audio, image, multimodal |
| Standout strength | Multilingual breadth, unmatched in the crowdsourced segment |
| Watch-out | Crowdsourced quality variance requires buyer-side QA investment |
Appen runs one of the world’s largest multilingual crowdsourced workforces, publicly stating coverage of more than 235 dialects, and offers both turnkey datasets and custom annotation. The strongest fit when language and locale coverage drive the project.
Biggest strengths. Multilingual breadth is unmatched in the crowdsourced segment. Turnkey datasets sit alongside custom work. A long track record with global enterprise buyers.
Potential cons. The breadth model makes depth in any one vertical harder to validate. Crowdsourced quality variance requires meaningful QA investment on the buyer side. Annotator turnover in some lanes affects consistency.
Best for: language-coverage-heavy projects spanning many dialects. The watch-out: crowdsourced quality variance means you carry the QA investment on the buyer side.
Surge AI
| Best for | Organizations training or aligning their own LLMs at scale |
| Key use cases | Preference rankings, RLHF, red-teaming, frontier-scale evaluation |
| Pricing model | Premium contracts benchmarked to frontier labs |
| Licensing / compliance | Production track record with the most demanding labs |
| Data types & coverage | Text and preference data for alignment |
| Standout strength | Frontier-lab-grade alignment data is the core competency |
| Watch-out | Fit thins outside the LLM alignment lane |
Surge AI publicly lists frontier LLM labs, including OpenAI, Google, Anthropic, and Microsoft, as customers. The specialism is alignment data: preference rankings, RLHF, red-teaming, and evaluation at frontier scale. A focused product for organizations training or aligning their own LLMs.
Biggest strengths. Frontier-lab-grade alignment data is the core competency. Strong QA discipline on preference ranking and red-teaming. A production track record with the labs most demanding on quality.
Potential cons. Outside the LLM alignment lane, the fit thins. Pricing reflects the frontier-lab benchmark. Not a general-purpose annotation vendor for image, video, or AV labeling.
Best for: organizations training or aligning their own LLMs at scale. The watch-out: fit thins fast outside the alignment lane, so it is not a general-purpose image or AV annotation vendor.
iMerit
| Best for | Projects where annotator qualification is the constraint |
| Key use cases | Healthcare, autonomous vehicles, geospatial annotation |
| Pricing model | Credentialed-annotator pricing |
| Licensing / compliance | Strong HIPAA-adjacent posture; auditable annotator-qualification chain |
| Data types & coverage | Image, medical imaging, geospatial, AV sensor data |
| Standout strength | Credentialed annotators (clinicians, radiologists, AV specialists) |
| Watch-out | Longer lead times; less suited to high-volume commodity labeling |
iMerit specializes in regulated-domain annotation, healthcare, autonomous vehicles, geospatial, with credentialed domain specialists rather than a generalist crowd. The strongest fit when annotator qualification is the constraint.
Biggest strengths. Credentialed annotators in regulated fields (clinicians, radiologists, AV specialists). A strong compliance posture across HIPAA-adjacent work. A documented annotator-qualification chain that auditors can verify.
Potential cons. Pricing reflects the credentialed model. Lead times run longer than the generalist crowd. Less suited to commodity bounding-box labeling at high volume.
Best for: projects where annotator qualification is the constraint: healthcare, AV, geospatial. The watch-out: credentialed annotators mean longer lead times and a poor fit for high-volume commodity labeling.
TELUS Digital
| Best for | Global, multimodal labeling at enterprise scale |
| Key use cases | Multilingual annotation across text, image, audio, and video |
| Pricing model | Enterprise contracts |
| Licensing / compliance | Mature compliance posture and procurement story |
| Data types & coverage | 500+ languages, all major modalities |
| Standout strength | Leader in Everest Group’s 2024 Data Annotation PEAK Matrix |
| Watch-out | Enterprise-shaped contracts and longer onboarding for smaller programs |
TELUS Digital (formerly TELUS International AI) publicly reports coverage across more than 500 languages and all major modalities, and was placed a Leader in Everest Group’s 2024 Data Annotation PEAK Matrix. Built for global, multimodal labeling at enterprise scale.
Biggest strengths. Global language coverage at enterprise SLA. Strong on multimodal projects spanning text, image, audio, and video. A mature compliance posture and procurement story.
Potential cons. Enterprise contracts tend to be enterprise-shaped, which runs heavy for smaller programs. Onboarding cycles run longer than smaller specialist vendors.
Best for: global, multimodal labeling at enterprise scale. The watch-out: enterprise-shaped contracts and longer onboarding make it heavy for smaller programs.
Sama
| Best for | Organizations that want a documented, auditable annotation chain |
| Key use cases | Computer-vision labeling, AV, geospatial, ethical-AI contexts |
| Pricing model | Reflects the ethical-sourcing premium |
| Licensing / compliance | Documented ethical-sourcing chain that holds up to procurement review |
| Data types & coverage | Image and video, regulated computer vision |
| Standout strength | Auditable annotation workflow with documented labor practices |
| Watch-out | Capacity varies by modality; lighter on text-only or audio-only work |
Sama is best known for computer-vision labeling in regulated and ethical AI contexts. The ethical-sourcing positioning is a real differentiator for buyers whose procurement and legal teams scrutinize labor practices.
Biggest strengths. A documented ethical-sourcing chain that holds up to procurement review. Strong on computer-vision projects, including AV and geospatial. An auditable annotation workflow.
Potential cons. Capacity varies by modality, so confirm the specific lane before contracting. Less coverage on text-only or audio-only work than the multilingual leaders. Pricing reflects the ethical-sourcing premium.
Best for: organizations that want a documented, auditable annotation chain, especially in computer vision. The watch-out: capacity varies by modality and is lighter on text-only or audio-only work, so confirm the lane first.
Cogito Tech
| Best for | Mid-tier multimodal labeling with mature compliance documentation |
| Key use cases | Multimodal annotation across image, video, text, and audio |
| Pricing model | Mid-tier relative to premium vendors |
| Licensing / compliance | Strong compliance documentation; reference customers in regulated industries |
| Data types & coverage | Image, video, text, audio |
| Standout strength | Quality and compliance without the frontier-lab price tier |
| Watch-out | Less frontier-LLM alignment specialism; smaller public footprint |
Cogito Tech operates in the multimodal labeling space, with strong compliance documentation, and publicly lists clients including AWS, Unilever, and Medtronic. A mid-tier option for buyers who want quality and compliance without the frontier-lab price tier.
Biggest strengths. Solid mid-tier pricing relative to the premium vendors. Multimodal coverage across image, video, text, and audio. Reference customers across regulated industries.
Potential cons. Less frontier-LLM alignment specialism than Surge or Scale. Capacity in any one modality varies, so scope the specific lane carefully. A smaller public footprint than the leaders, which makes procurement reference checks take longer.
Best for: mid-tier multimodal labeling with mature compliance documentation. The watch-out: a smaller public footprint and lighter frontier-alignment specialism mean longer reference checks.
Quick summary
Q: When should you use a labeling and annotation service instead of a sourcing partner?
A: Use a labeling and annotation service when the raw data is already collected and the bottleneck is human judgment at scale: bounding boxes, transcripts, span labels, or RLHF preference rankings. The seven named vendors split by tier and specialism. Scale AI and Surge AI own the premium frontier-LLM lane, Appen and TELUS Digital lead on multilingual breadth (235-plus dialects and 500-plus languages respectively), iMerit and Sama compete on credentialed and auditable annotation, and Cogito Tech holds the mid-tier. The wrong fit is using any of them when the raw data does not yet exist.
Expert insights
Independent analyst coverage backs the tiering in this category. In its 2024 Data Annotation PEAK Matrix Assessment, Everest Group positioned TELUS Digital as a Leader, citing its breadth across modalities and languages and its enterprise delivery maturity. The read for buyers: annotation is no longer a commodity crowd-labor buy. Analyst-recognized delivery maturity and language coverage are the variables that separate the enterprise tier from the long tail.
Source: Everest Group, Data Annotation PEAK Matrix Assessment 2024 (analyst assessment).
Dataset marketplaces
Marketplaces license pre-built datasets you can buy, download, and use. The corpus is standard. The license terms are pre-negotiated. The speed-to-value is fast. Our guide to the best AI dataset marketplaces compares eight of these platforms side by side.
Marketplaces fit best when the training task has a well-known shape, sentiment, common-object detection, or general-purpose dialogue, and the available data is sufficient. They fit worse when you need a dataset shaped exactly to your model’s domain, language, or schema.
Datarade
| Best for | Early-stage scoping when you need to see what is out there |
| Key use cases | Browsing and comparing third-party data products across providers |
| Pricing model | Varies by underlying provider |
| Licensing / compliance | License terms vary from catalog item to catalog item |
| Data types & coverage | Wide catalog spanning many provider types and modalities |
| Standout strength | Standardized browse-and-compare flow across vendors |
| Watch-out | An aggregator, not a partner for ongoing engagement |
Datarade is a meta-marketplace that aggregates third-party data products, including AI training datasets, from many independent providers. A natural starting point when you are still scoping what is available in the market.
Biggest strengths. A wide catalog spanning many provider types and modalities. Useful for early-stage scoping when you need to map the landscape. A standardized browse-and-compare flow across vendors.
Potential cons. As an aggregator, quality consistency depends on each underlying provider. License terms vary from catalog item to catalog item. Not a partner for ongoing engagement; it is a discovery surface.
Best for: early-stage scoping when you need to see what is out there before committing. The watch-out: it is an aggregator, not an ongoing-engagement partner, and quality depends on each underlying provider.
Shaip
| Best for | Medical AI teams needing licensed clinical datasets plus annotations |
| Key use cases | Healthcare AI data catalog combined with annotation services |
| Pricing model | Catalog licensing plus annotation engagements |
| Licensing / compliance | Healthcare-appropriate licensing |
| Data types & coverage | Medical NLP and imaging; clinical datasets |
| Standout strength | Combined catalog-plus-annotation model reduces vendor count |
| Watch-out | Outside healthcare, the catalog narrows substantially |
Shaip runs a healthcare-oriented AI data catalog alongside annotation services. The dual model fits medical AI teams that want both licensed clinical datasets and matching annotations in a single engagement.
Biggest strengths. A healthcare-specific catalog with appropriate licensing. The combined catalog-plus-annotation model reduces vendor count. Domain depth in medical NLP and imaging.
Potential cons. Outside healthcare, the catalog narrows substantially. The domain specialism means less fit for general-purpose training programs.
Best for: medical AI teams who need both licensed clinical datasets and matching annotations. The watch-out: outside healthcare the catalog narrows substantially, so it is a poor general-purpose fit.
Defined.ai
| Best for | Voice-AI and conversational model teams |
| Key use cases | Speech, conversational, and multimodal dataset licensing; custom collection |
| Pricing model | Catalog licensing plus custom collection |
| Licensing / compliance | Mature licensing terms for audio corpora |
| Data types & coverage | Speech, conversational, multimodal |
| Standout strength | Deep specialism in speech and conversational data |
| Watch-out | Coverage uneven for niche languages and domains outside speech |
Defined.ai maintains a marketplace of speech, conversational, and multimodal datasets. The strongest fit when voice and conversational corpora are the bottleneck.
Biggest strengths. Deep specialism in speech and conversational data. Mature licensing terms for audio corpora. Custom collection sits alongside catalog purchases.
Potential cons. Corpus availability for niche languages or domains is uneven. Less coverage outside speech and conversational AI than general-purpose marketplaces.
Best for: voice-AI and conversational model teams. The watch-out: coverage is uneven for niche languages and thin outside speech and conversational data.
Quick summary
Q: When is a dataset marketplace the right choice for AI training data?
A: A dataset marketplace is the right choice when the training task has a well-known shape, the license terms are pre-negotiated, and speed-to-value matters more than a bespoke schema. Datarade fits early-stage scoping across many providers, Shaip fits medical AI teams that want clinical datasets plus matching annotations, and Defined.ai fits voice and conversational model teams. Marketplaces are the wrong choice when you need a corpus shaped exactly to your model’s domain, language, or schema, which is where custom sourcing takes over.
Expert insights
The licensing market behind these catalogs is consolidating fast. More than 20 publishers, among them Axios, The Atlantic, Condé Nast, Hearst, News Corp, and Vox Media, have signed content-licensing deals with OpenAI, per public reporting. The implication for marketplace buyers: a pre-built corpus with documented, pre-negotiated licensing is becoming the defensible option, while undocumented scraped corpora accumulate legal risk that surfaces later in the model’s life.
Source: public reporting on OpenAI publisher licensing agreements (2024–2025).
Synthetic data generators
Synthetic vendors generate artificial training data that mirrors the statistical properties of real data. The use cases are privacy-safe augmentation, rare-event coverage, and bridging gaps where real data is legally or operationally difficult to collect, a response in part to the looming data-scarcity crisis facing model builders.
Synthetic data fits best when you have a real dataset to anchor on and need either more of it or a version your compliance team can sign off on. It fits worse when used alone, because synthetic-only training programs tend to drift.
Gretel (NVIDIA)
| Best for | Teams already standardized on NVIDIA’s stack |
| Key use cases | Privacy-preserving synthetic structured and text data |
| Pricing model | Platform-based, within the NVIDIA NeMo ecosystem |
| Licensing / compliance | Differential privacy and synthetic-record primitives |
| Data types & coverage | Structured and text synthetic data |
| Standout strength | Tight integration with NVIDIA’s NeMo and GPU stack |
| Watch-out | Optimized for NVIDIA-standardized teams; still needs anchor real data |
Gretel was acquired by NVIDIA in March 2025 and integrated into the NeMo ecosystem. The platform generates synthetic structured and text data, with a strong privacy-preservation story.
Biggest strengths. Tight integration with NVIDIA’s NeMo and GPU stack. Mature privacy-preservation primitives (differential privacy, synthetic record generation). Backed by NVIDIA’s roadmap and resources.
Potential cons. Optimized for teams already standardized on NVIDIA. Synthetic-only programs still need real data to anchor, and Gretel does not solve that on its own. The post-acquisition product roadmap is still settling.
Best for: teams already standardized on NVIDIA’s stack who need privacy-preserving synthetic data. The watch-out: it is optimized for NVIDIA-standardized teams and still needs anchor real data to be useful.
MOSTLY AI
| Best for | Regulated industries needing synthetic versions of production records |
| Key use cases | Tabular synthetic data for banking and insurance |
| Pricing model | Enterprise pricing |
| Licensing / compliance | Mature privacy compliance posture |
| Data types & coverage | Tabular synthetic data |
| Standout strength | Deep specialism in tabular synthetic data with production deployments |
| Watch-out | Less fit for image, text, or audio; still needs anchor real data |
MOSTLY AI focuses on enterprise synthetic data for tabular datasets, with a privacy-first generator workflow. A strong fit for regulated industries needing synthetic versions of production records.
Biggest strengths. Deep specialism in tabular synthetic data. A mature privacy compliance posture. Production-grade enterprise deployments in banking and insurance.
Potential cons. The tabular focus means less fit for synthetic generation of images, text, or audio. An enterprise pricing motion. Still requires anchor real data to train the generator.
Best for: regulated industries needing synthetic versions of production records. The watch-out: the tabular focus is a poor fit for image, text, or audio, and the generator still needs anchor real data.
Tonic.ai
| Best for | Teams where speed and developer experience are the priority |
| Key use cases | Synthetic data for software testing and AI development augmentation |
| Pricing model | Platform subscription |
| Licensing / compliance | Standard data-privacy controls |
| Data types & coverage | Realistic synthetic data for test and training pipelines |
| Standout strength | Strong developer experience; fast to integrate into CI/CD and ML pipelines |
| Watch-out | Less specialized in privacy primitives; anchor real data still required |
Tonic.ai generates realistic synthetic data for software testing and AI development. The product emphasis is on developer experience and pipeline speed.
Biggest strengths. Strong developer experience and tooling. Fast to integrate into existing CI/CD and ML pipelines. Useful for both test-data generation and AI training augmentation.
Potential cons. Less specialized in privacy primitives than MOSTLY AI or Gretel. Synthetic-only is still not a complete training program, so anchor real data is required.
Best for: teams where speed and developer experience are the priority. The watch-out: it is lighter on privacy primitives than MOSTLY AI or Gretel, and anchor real data is still required.
K2view
| Best for | Enterprises where synthetic data feeds live operational systems |
| Key use cases | Production-scale synthetic data with live-system integration |
| Pricing model | Enterprise pricing |
| Licensing / compliance | Enterprise integrations into existing operational stacks |
| Data types & coverage | Complex relational data via entity-based architecture |
| Standout strength | Operational deployment posture, including live-system feeds |
| Watch-out | Heavier integration motion than pure-play training generators |
K2view competes in the production-scale synthetic data space, with an emphasis on operational deployment and live-system integration. Suited to use cases where synthetic data feeds production rather than training in isolation.
Biggest strengths. An operational deployment posture, including live-system feeds. An entity-based architecture that handles complex relational data. Enterprise integrations into existing operational stacks.
Potential cons. A heavier integration motion than pure-play training data generators. Less of a fit if synthetic data only needs to feed offline training, not live systems. Enterprise pricing.
Best for: enterprises where synthetic data needs to feed live operational systems, not just offline training. The watch-out: the integration motion is heavier than pure-play training generators and overbuilt for offline-only training.
Hazy
| Best for | Regulated tabular workloads: banking, insurance, customer records |
| Key use cases | Synthetic versions of customer or transaction records |
| Pricing model | Enterprise sales motion |
| Licensing / compliance | Privacy primitives that hold up to regulator scrutiny |
| Data types & coverage | Tabular enterprise data |
| Standout strength | Strong tabular synthetic generation for financial and regulated workloads |
| Watch-out | Tabular focus; less coverage of image, text, or audio |
Hazy focuses on tabular enterprise data, with emphasis on regulated industries that need synthetic versions of customer or transaction records. Closer in posture to MOSTLY AI than to the developer-focused tools.
Biggest strengths. Strong tabular synthetic generation for financial and regulated workloads. Privacy primitives that hold up to regulator scrutiny. An enterprise procurement track record.
Potential cons. A tabular focus, similar to MOSTLY AI, with less coverage of image, text, or audio modalities. The enterprise sales motion runs heavier than developer-tools competitors.
Best for: regulated tabular workloads: banking, insurance, customer records. The watch-out: the tabular focus leaves thin coverage of image, text, or audio modalities.
Synthetic vendors return the most when paired with one of the other three categories. Anchor on real data, then augment with synthetic where the math says it helps.
Quick summary
Q: When does synthetic data belong in an AI training program?
A: Synthetic data belongs in a training program when you already have a real dataset to anchor on and need privacy-safe augmentation, rare-event coverage, or a compliance-cleared version of production records. Gretel fits NVIDIA-standardized teams, MOSTLY AI and Hazy specialize in regulated tabular data, Tonic.ai prioritizes developer experience, and K2view feeds live operational systems. The common watch-out across all five: synthetic data does not stand alone. Anchor on real data and augment with synthetic where the math supports it, because synthetic-only programs tend to drift.
Expert insights
The “synthetic-only drifts” warning is not opinion; it is a peer-reviewed result. In a 2024 Nature paper, Ilia Shumailov and co-authors found that “indiscriminately learning from data produced by other models causes ‘model collapse’,” a degenerative process where models trained recursively on generated content lose the tails of the true distribution and converge on lower-quality output. The buyer’s takeaway: synthetic data is an augmentation layer over a real anchor dataset, not a replacement for it.
Source: Ilia Shumailov et al., “AI models collapse when trained on recursively generated data,” Nature (2024).

How to evaluate an AI training data provider: the seven-axis framework
With the shortlist in hand, run a real evaluation. These are the seven axes that separate viable shortlists from category-confused ones.
1. Modality. Text, image, audio, video, structured tabular, multimodal, document. Most vendors are honest about which modalities they handle deeply. Make them prove it with samples.
2. Scale. Hundreds of examples or hundreds of millions? Static delivery or continuous refresh? Most vendors scale up cleanly only inside their core category.
3. IP cleanliness. Where does the data come from, who licensed it, and can the vendor show the chain? In a year that has the New York Times pursuing summary judgment against OpenAI and Getty pursuing Stability AI across two jurisdictions, provenance is no longer a nice-to-have.
4. Freshness. A snapshot from 2023 will not train a model that needs to know what happened last quarter. Ask explicitly: how often does this data refresh, and what is the SLA?
5. Customisation depth. Can the schema bend to your model’s needs, or do you bend to theirs? Standardised schemas are fast; bespoke schemas are slower but more useful for differentiated AI products.
6. Compliance posture. SOC 2 Type II, ISO 27001, HIPAA for medical, GDPR/CCPA for personal, FedRAMP for federal. Ask for documentation, not a marketing line.
7. Managed vs DIY. Does the vendor run the pipeline for you, or hand you a tool and a login? Both are valid. They carry very different operational costs over a three-year horizon.
A practical decision-criteria table, your axes scored against your three or four finalists, is worth more than any vendor’s pitch deck. Build it before you take a sales call.
Quick summary
Q: How do you evaluate an AI training data provider?
A: Evaluate an AI training data provider against seven axes: modality, scale, IP cleanliness, freshness, customization depth, compliance posture, and managed vs DIY. Score each finalist on every axis in a decision-criteria table before taking a sales call, because most vendors scale and perform cleanly only inside their core category. The two axes buyers most often underweight are IP cleanliness and managed vs DIY, since both surface their real cost later: one as legal exposure, the other as a multi-year operational load.
Expert insights
The seven axes track a broader shift in where model performance is won. As Andrew Ng put it in framing the data-centric AI movement, “the model and the code are basically a solved problem,” and the remaining gain is in systematically engineering data quality. Two of the seven axes (modality fit and customization depth) operationalize exactly that: they test whether the dataset bends to the model’s needs rather than the reverse.
Source: Andrew Ng, founder of DeepLearning.AI and Landing AI, on the data-centric AI approach (Scale Events / IEEE Spectrum, 2022).

IP cleanliness and provenance: the evaluation axis most listicles skip
Most “AI training data providers” articles in 2026 still treat IP cleanliness as a sentence in the conclusion. The legal record of the past 24 months says it belongs near the top of every RFP.
The New York Times’ copyright case against OpenAI and Microsoft, filed in late 2023 and currently moving toward an April 2026 summary judgment hearing per public court reporting, alleges that millions of Times articles were used to train ChatGPT without a license. The Times is seeking statutory damages publicly described as in the billions.
Getty Images’ parallel actions against Stability AI have produced a UK High Court ruling that rejected the secondary copyright claim over Stable Diffusion’s model weights but found limited trademark infringement in the reproduction of watermarks; the US case continues.
Alongside the litigation, more than 20 publishers, including Axios, The Atlantic, Condé Nast, Hearst, News Corp, and Vox Media, have signed licensing deals with OpenAI. A paid-licensing market is forming alongside the lawsuits.
The takeaway for any 2026 RFP: the provenance chain matters. Ask vendors three questions in writing.
- Where did this data originate, and what is the license under which you acquired the right to use it?
- What contractual protections do I have if a third party claims rights to the underlying source?
- Do you resell the data you collect for me to any other party, and if not, will that no-resell commitment appear in the contract?
A vendor that cannot produce documented answers to those three questions does not belong on the shortlist, no matter how strong the rest of the pitch is. For a deeper look at the public-versus-private sourcing distinction in this context, see our public web data vs. private data in the AI training primer, and for the compliance angle specifically, our guide on solving the AI training data crisis with compliant web scraping.
Quick summary
Q: How do you evaluate IP cleanliness and provenance in an AI training data vendor?
A: Evaluate IP cleanliness by putting three questions in writing: where the data originated and under what license, what contractual protection you get if a third party claims rights, and whether the vendor resells data collected on your behalf. The legal context makes this load-bearing: the New York Times case against OpenAI is moving toward an April 2026 summary judgment hearing, Getty’s actions against Stability AI run across two jurisdictions, and 20-plus publishers have signed paid licensing deals. A vendor that hedges on any of the three questions should not advance, regardless of the rest of the pitch.
Expert insights
The provenance question is being decided in court, not in marketing decks. In its complaint against OpenAI and Microsoft, The New York Times alleges the defendants “seek to free-ride on The Times’s massive investment in its journalism” by using its articles to build substitutive products without a license, and is pursuing summary judgment on that basis per public court reporting. For training-data buyers, the signal is direct: undocumented provenance is a liability that can surface years after the dataset ships.
Source: The New York Times Company v. Microsoft and OpenAI, complaint filed December 2023 (public court filing).
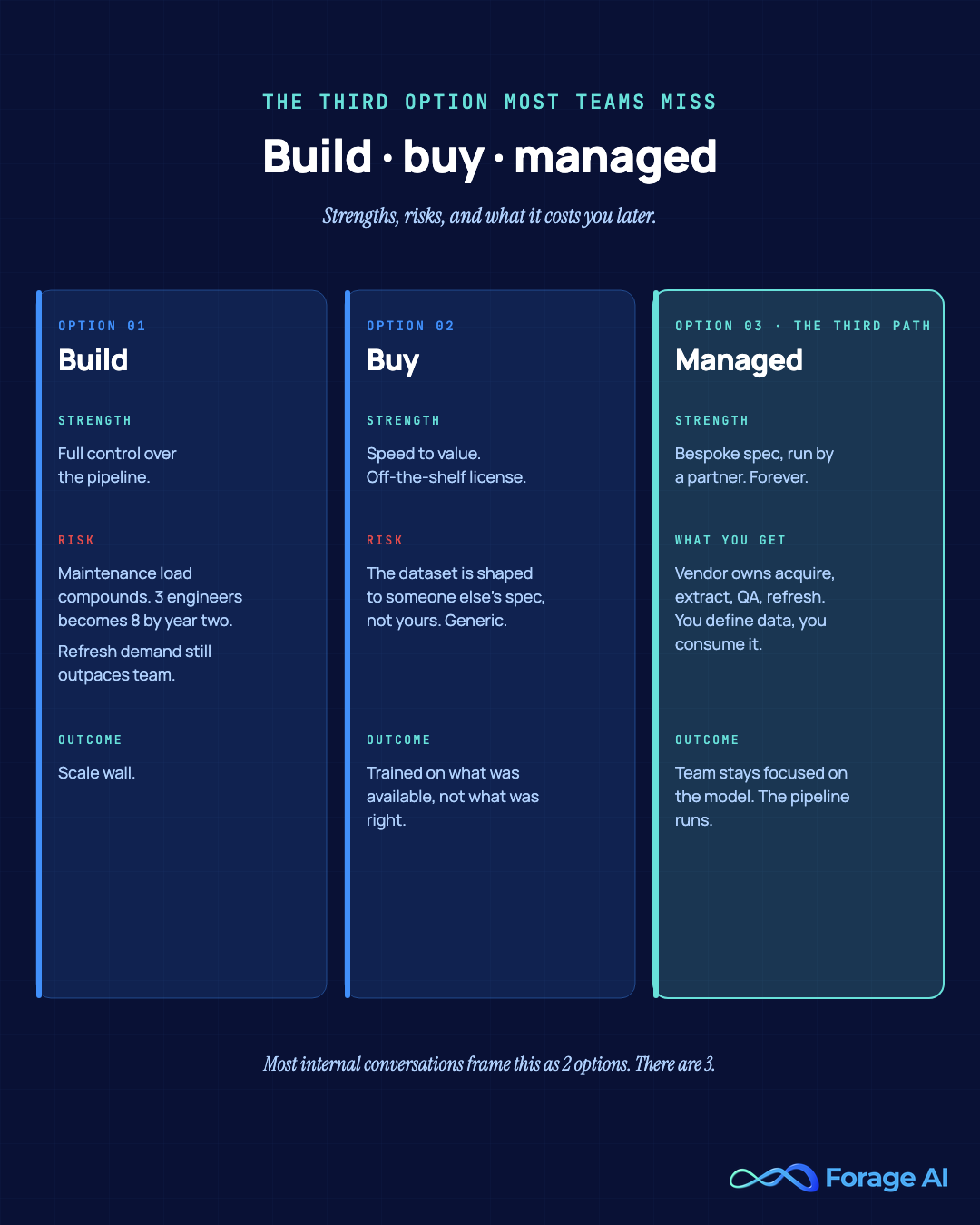
Build vs buy vs managed: the third option most teams miss
Most internal conversations frame this as a two-option decision: build the data acquisition team in-house, or buy datasets off the shelf. Both options carry real costs that show up later.
Build gives you control, but extraction pipelines break when sources change, anti-bot measures evolve, and document layouts shift. The maintenance load compounds. Teams that started with three engineers on training data acquisition often have eight by year two and still cannot keep up with refresh demand. The scale wall is real.
Buy gives you speed, but the dataset is shaped to someone else’s spec. Your model ends up trained on what was available, not on what was right.
The third option is managed: a partner runs the acquisition, extraction, and QA pipeline; you define the data and consume it. This is the category Forage AI sits in. It is not “we sell you a tool”; it is “we run the pipeline, forever, so your team stays focused on the model.” For a deeper build-versus-buy framework adjacent to this decision, see our strategic guide to web data extraction build vs buy, and once you have chosen a partner, the operational playbook for AI training data covering freshness, schema versioning, and vendor handoff.
Quick summary
Q: Should you build, buy, or use a managed partner for AI training data?
A: Build gives control but compounds a maintenance load that pushes a three-engineer team to eight by year two without keeping up with refresh. Buy gives speed but shapes your model to someone else’s spec. The third option, managed, has a partner run acquisition, extraction, and QA while you define and consume the data, which is the category Forage AI operates in. Choose managed when the data is core to a differentiated model but the pipeline is not the business you want to staff and maintain.
Expert insights
The build-vs-buy math turns on where the durable advantage sits. Andrew Ng’s data-centric thesis holds that performance gains now come from systematically improving the data rather than the model, which reframes the in-house build question: the maintenance load on extraction pipelines is recurring engineering cost spent on infrastructure, not on the data quality that actually moves the model. A managed pipeline isolates the team’s effort to the part that compounds, freeing engineers to focus on the practical reality of intelligent automation the data is meant to power rather than the plumbing beneath it.
Source: Andrew Ng, founder of DeepLearning.AI and Landing AI, on the data-centric AI approach (Scale Events / IEEE Spectrum, 2022).
FAQ
What is the difference between an AI training data provider and a data labeling company? A labeling company adds structure (labels, annotations, preferences) to data you already have. An AI training data provider in the broadest sense covers everything from sourcing to labeling, but the strongest ones specialize in one of the four categories described above. Pick the category that matches your gap.
How much does AI training data cost? Publicly reported benchmarks: simple bounding box labeling runs $0.02–$0.09 per object; managed annotation services $6–$12 per hour; expert RLHF and medical annotation $50–$100 per example. Custom sourcing and extraction is typically scoped as a managed program, not unit-priced, because the value sits in the pipeline rather than the line item.
What is the difference between custom data sourcing and synthetic data? Custom sourcing acquires real data from real sources (web, documents, public records) and structures it. Synthetic data generates artificial data that mirrors a real distribution. They solve different problems; many programs use both.
How do I evaluate IP cleanliness in a vendor? Ask for the license chain in writing, ask whether the vendor resells data collected on your behalf, and ask what indemnification you get if a third party claims rights. A vendor that hedges on any of the three should not advance.
Can one vendor cover all my modalities? Sometimes. Multimodal-capable vendors exist in every category, but depth varies. The honest answer is to confirm modality by modality during scoping rather than trust the marketing claim.
Conclusion
The four-category map is the most useful tool you can carry into a 2026 AI training data evaluation. Anchor on the gap, pick the category, run the seven-axis framework against a real shortlist, and put IP cleanliness near the top of the RFP rather than the bottom. If your gap is custom, web-scale, multimodal training data delivered as a managed pipeline, we built Forage AI for exactly that conversation.
Related Articles
- Quality Over Quantity in AI Training Data – why curation beats raw volume.
- A Guide to Modern Data Extraction Services in 2026 – the broader data extraction services guide covering the full landscape.
- Data Extraction Automation: The Complete 2026 Guide – the pillar overview on data extraction automation across the stack.
- Automated Data Collection pillar title – the pillar overview on automated data collection.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




