

If you’ve ever bought a packaged dataset, plugged it into your product, and discovered that the fields you actually needed (the ones that would have made your product different from the next one) weren’t in there, you’ve already met the wall most Data as a Service buyers hit.
It’s a quiet kind of disappointment. The vendor demo went well. The schema looked complete. The contract got signed. Then your team started building, and the gap emerged: the field you needed for the differentiating use case was either missing, sparse, or defined differently. So you bought a second dataset. Then a third. Now your data team spends Monday mornings reconciling exports from vendors who don’t agree on what a “company” is.
This article is about why that pattern keeps repeating, and what most introductory writing on data as a service gets wrong by treating it as a single category. It isn’t one thing. It’s two, and the difference between them is the difference between “we’re a subscriber” and “we own our data acquisition layer.”
Quick Digest — What You’ll Learn
- DaaS = on-demand external-data delivery, packaged or custom. One label, two delivery models.
- Packaged DaaS (ZoomInfo, Crunchbase, D&B, Equifax-class) gives you the same schema and refresh cadence as everyone else.
- Custom DaaS gives you your fields, your business rules, your refresh cadence, and your delivery format, built around your product instead of the vendor’s.
- The “wrong 60%” — pre-built datasets typically cover the median 60% of the fields enterprises need. The differentiating 40% is where most buyers get stuck.
- A four-question test at the end of the article will tell you which side of the packaged-vs-custom line your use case sits on.
What Data as a Service Actually Means
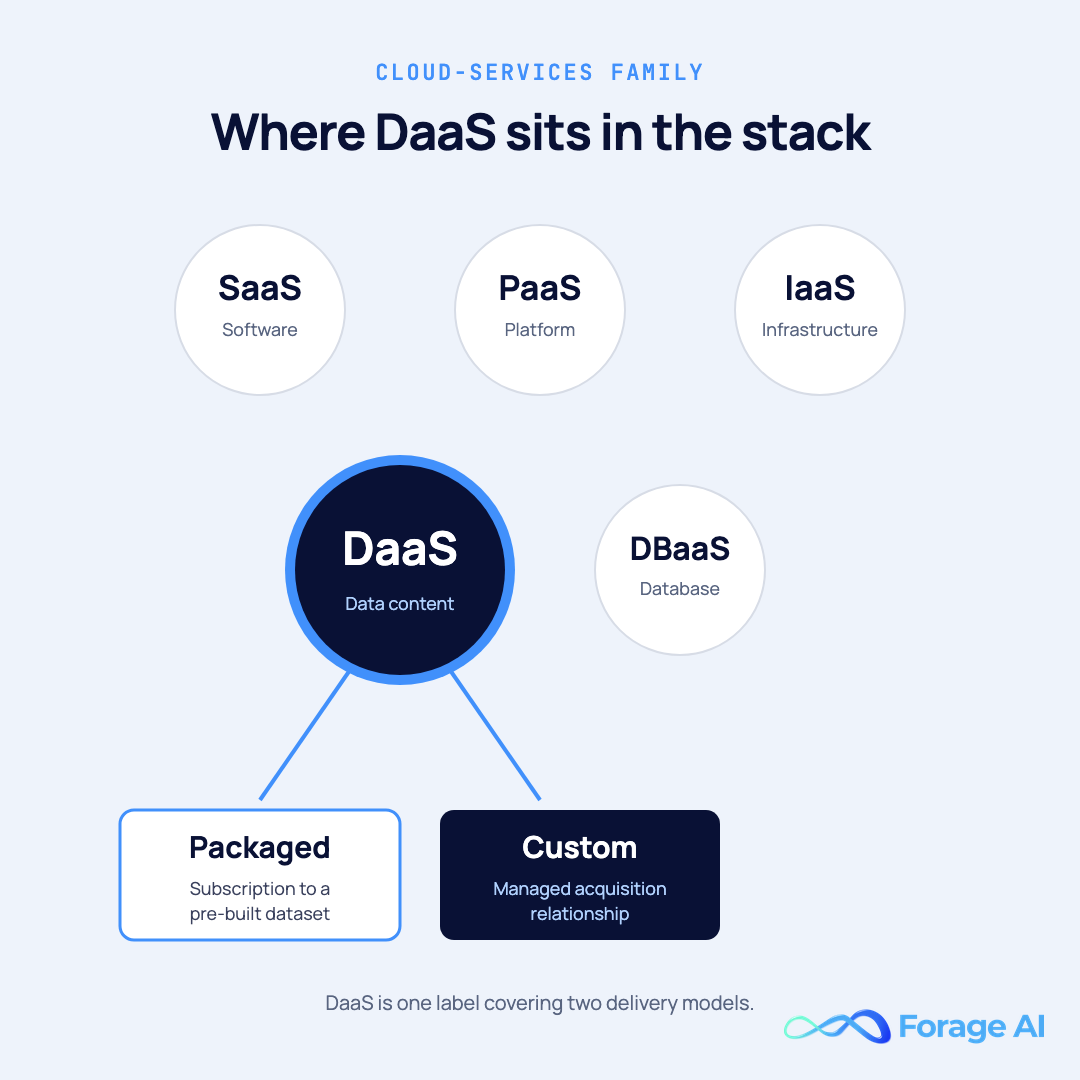
Data as a Service is the practice of delivering external data to a buyer on demand, over the internet, as a subscription or managed engagement, without that buyer having to acquire, clean, normalize, or maintain the data themselves. It sits in the same family as Software as a Service (SaaS), Infrastructure as a Service (IaaS), and Platform as a Service (PaaS): someone else owns the operational layer, and you pay to consume the output.
That’s the simple definition. Here’s the complication every introductory article on DaaS skips: the term covers two very different delivery models, and the buying decision lives in the difference between them.
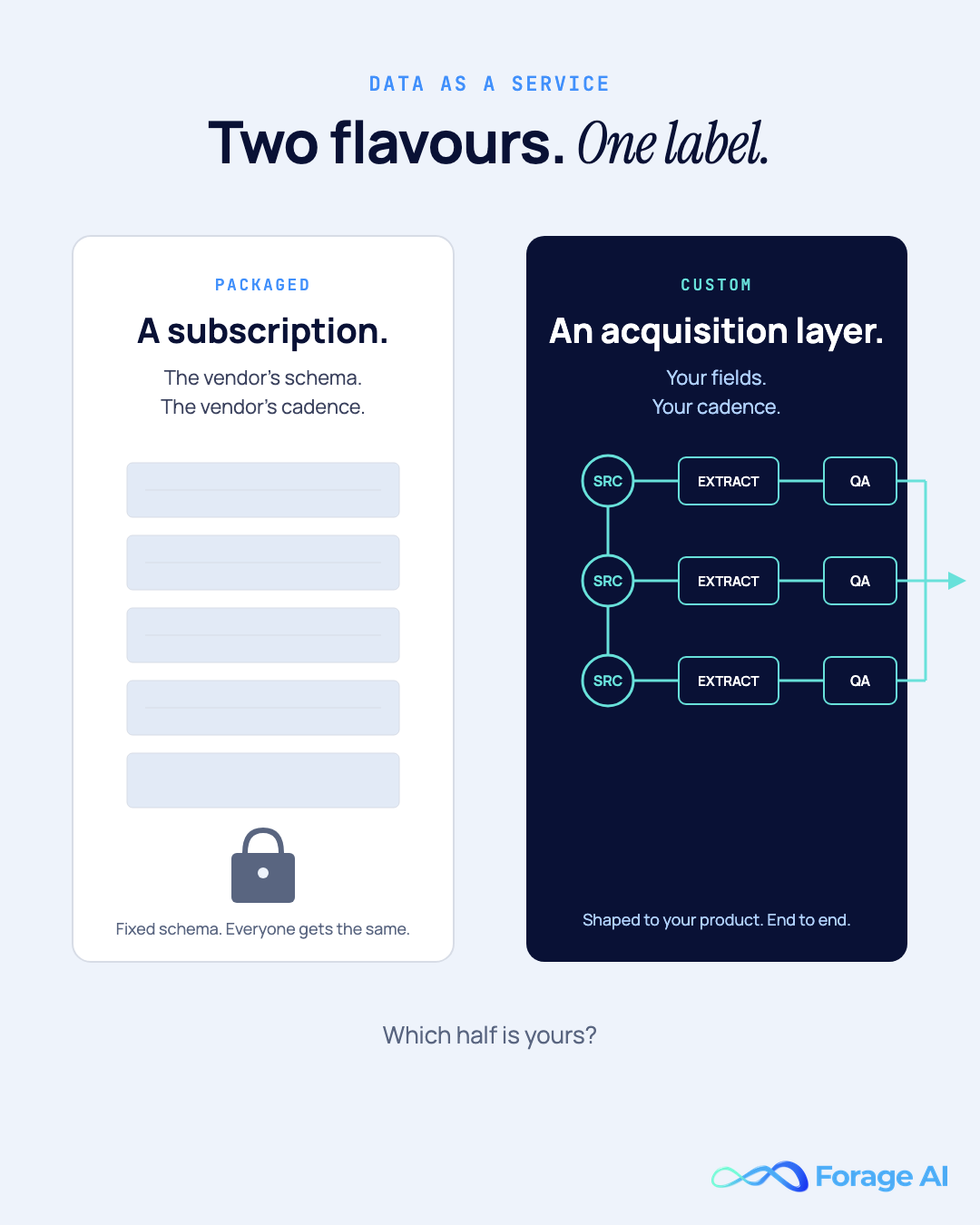
The first is packaged DaaS, a subscription to a pre-built dataset. The vendor decides which fields the dataset contains, which taxonomy to use, how often it refreshes, and how it’s delivered. You subscribe, you query, you accept the shape of what comes back. Crunchbase for startup and funding data, ZoomInfo for B2B contact and firmographic data, Dun & Bradstreet for company records, Equifax for credit data: all packaged DaaS.
The second is custom DaaS, a managed acquisition relationship. The vendor doesn’t sell you a dataset. They build and run an acquisition pipeline around the specific fields, business rules, refresh cadence, and delivery format your product needs. You own the schema. The vendor owns the acquisition layer behind it.
The reason this split matters is that search engines and most explanatory content treat DaaS as a single category, which obscures the buying decision. The right question isn’t “should we use DaaS?” It’s “which kind of DaaS does our use case need?”, and that question has a structured answer.
The demand for both flavors is growing fast. IDC estimates that 78% of stored enterprise data is now unstructured, with global data volume forecast to grow from 5.5 zettabytes in 2024 to 10.5 zettabytes by 2028, a 16% annual growth rate. And Gartner’s 2026 Data & Analytics Predictions anchor the next several years in a unified data fabric and AI-ready data, both of which depend on a reliable partner to handle external data acquisition.
Quick Summary — Why does the packaged-vs-custom distinction matter? Because every other introductory piece on DaaS pretends it’s one category. The actual buying decision lies within the split, and getting it wrong can cost you years of vendor sprawl before you correct it.
Expert Insights — Per IDC’s 2024 data forecast, the unstructured-data share of enterprise storage is set to keep growing at a 16% CAGR through 2028. That’s the underlying pressure pushing data programs toward outsourced acquisition: nobody’s in-house team scales linearly with that curve.
The DaaS Family Tree: DaaS vs DBaaS vs Data-as-a-Product vs Data Marketplaces
Now that we’ve established what DaaS is, it helps to draw a line around what it isn’t. Four cloud-data terms get conflated constantly, and the distinction matters when you’re scoping a procurement.
- Data as a Service (DaaS) delivers curated, ready-to-use data content on demand. You don’t run the database. You consume the data.
- Database as a Service (DBaaS) delivers managed database infrastructure (Amazon RDS, Google Cloud SQL, MongoDB Atlas). You bring your own data and run your own queries. The vendor handles uptime, backups, and scaling.
- Data as a Product (DaaP) is an internal team philosophy in which each domain within a company owns and publishes its data as a product to other internal teams. The “customer” is another team, not an external buyer.
- Data Marketplace is a discovery and procurement layer where multiple data providers list datasets for sale (think of catalog-style platforms operated by major cloud providers). The marketplace itself doesn’t produce the data; it shelves it.
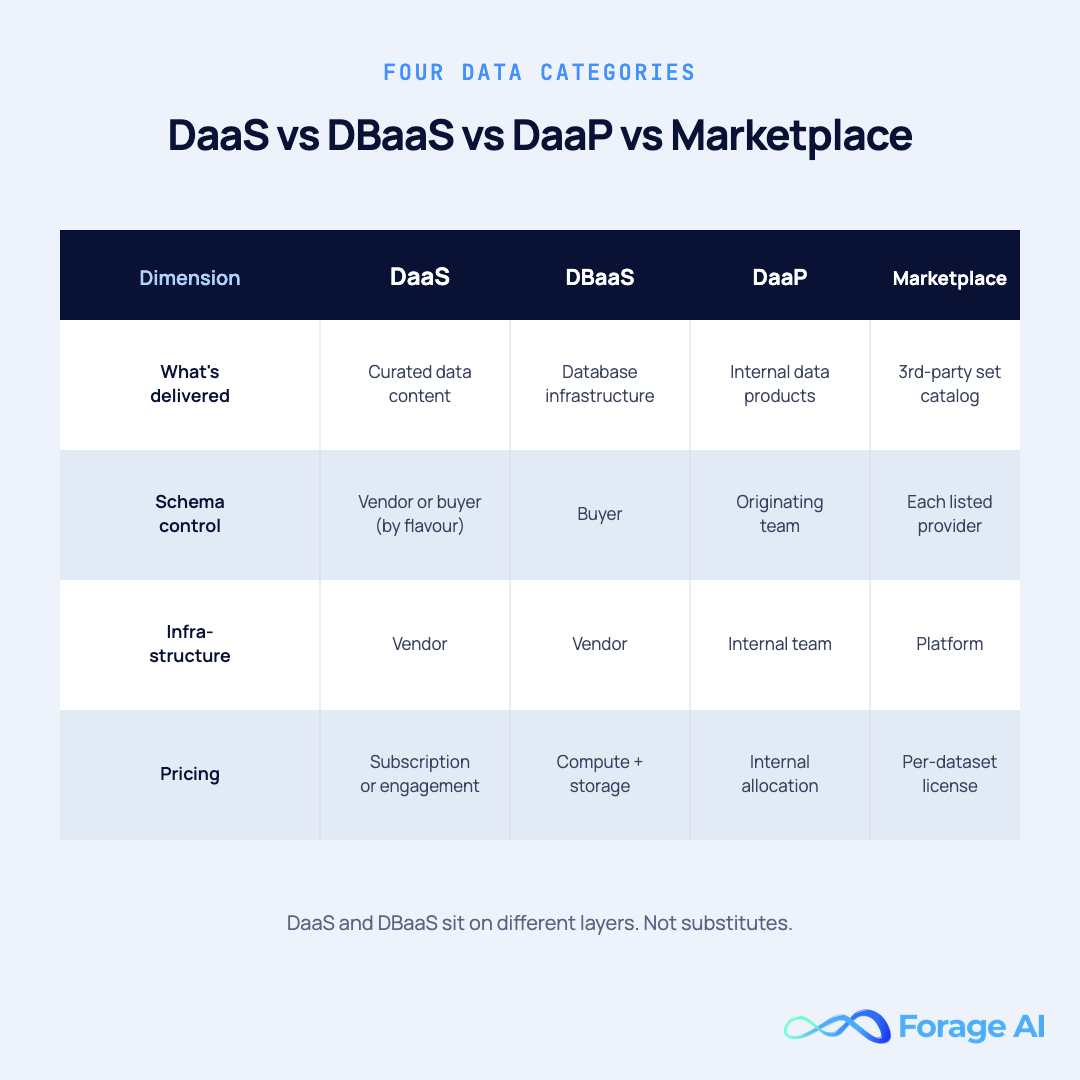
| What’s delivered | Who controls schema | Pricing typically | |
|---|---|---|---|
| DaaS | Curated data content | Vendor (packaged) or buyer (custom) | Subscription or engagement |
| DBaaS | Database infrastructure | Buyer | Compute + storage |
| DaaP | Internal data products | Originating team | Internal allocation |
| Data Marketplace | Catalog of third-party datasets | Each listed provider | Per-dataset license |
The common misconception is that DaaS and DBaaS are interchangeable. They aren’t; they live on different layers of the stack. DBaaS is plumbing for your own data. DaaS is content acquired and curated for you. If you find yourself comparing the two in a vendor evaluation, you’ve probably scoped the wrong question.
Quick Summary — Is DaaS the same as DBaaS? No. DaaS gives you the data; DBaaS gives you the place to store it. You may need both, in sequence, but they’re not substitutes.
Expert Insights — The Data-as-a-Product movement, popularized by Zhamak Dehghani’s data mesh writing, is sometimes mistakenly pitched as a competitor to DaaS. It isn’t. DaaP is how an internal data team organizes itself; DaaS is how an enterprise sources external data it can’t generate in-house.
Packaged DaaS: What You Get from Crunchbase, ZoomInfo, D&B, and the Rest

With the neighboring categories sorted, the packaged side of DaaS is where most buyers start, so it’s where we start, too. Packaged DaaS is what most people picture when they hear “Data as a Service.” It’s a subscription to a pre-built dataset, with the vendor owning the schema, refresh cadence, and delivery format end-to-end. You don’t tell them what to collect or how to model it. You tell them how much you’ll pay, and you receive the data shaped the way every other customer receives it.
The packaged market is mature and segmented. A few category examples:
- Firmographic and B2B contact data: ZoomInfo, Dun & Bradstreet, Cognism.
- Startup, funding, and private-company data: Crunchbase, PitchBook.
- Consumer and marketing data: Acxiom, NielsenIQ.
- Credit and risk data: Equifax, Experian, TransUnion.
Pricing on this side usually falls into one of three models: per-seat licenses, per-record consumption, or tiered API access (with a free or freemium entry point that scales up to enterprise). For evaluation depth on this layer of the market, see our walkthrough of the best firmographic data providers in 2026, our roundup of the best Data-as-a-Service companies, and the B2B data provider selection guide.
Packaged DaaS works well in certain situations. Your use case maps cleanly onto the vendor’s canonical schema. Coverage matters more than depth: you need a lot of records, and you don’t need each one annotated with fields specific to your product. Your team isn’t trying to differentiate on the data itself. Account prioritization, top-of-funnel enrichment, baseline market sizing, credit checks: all good, packaged DaaS use cases.
There’s a less-discussed reality on this side, though, that buyers tend to discover after the contract is signed. Packaged datasets are non-differentiating by design; that’s the point. Every competitor with the same subscription is looking at the same records. And the quality of those records is uneven. A 2026 Landbase analysis found that B2B contact data decays at roughly 2.1% per month (about 22.5% per year) and reported an industry-average B2B data accuracy of around 50%, compared with 97%+ from high-quality providers. The vendor’s standard schema also can’t carry your business rules (your definition of an “active customer,” your deduplication logic, your industry classification dictionary) without a downstream normalization layer that your team has to build and maintain.
Quick Summary — When is packaged DaaS the right call? When your use case fits the vendor’s canonical schema, when coverage matters more than depth, and when you’re not trying to differentiate your product on the data itself. If your product economics depend on fields the vendor doesn’t carry, you’re shopping in the wrong aisle.
Expert Insights — The 2.1%-per-month decay rate is the unspoken pricing factor on packaged contact data: the per-record cost looks reasonable at signing, but the working-record cost ratchets up every quarter as accuracy degrades and your team patches around it.
The “Wrong 60%”: Why Packaged DaaS Misses What Differentiates Your Product
Here’s the frame that organizes the rest of this article.
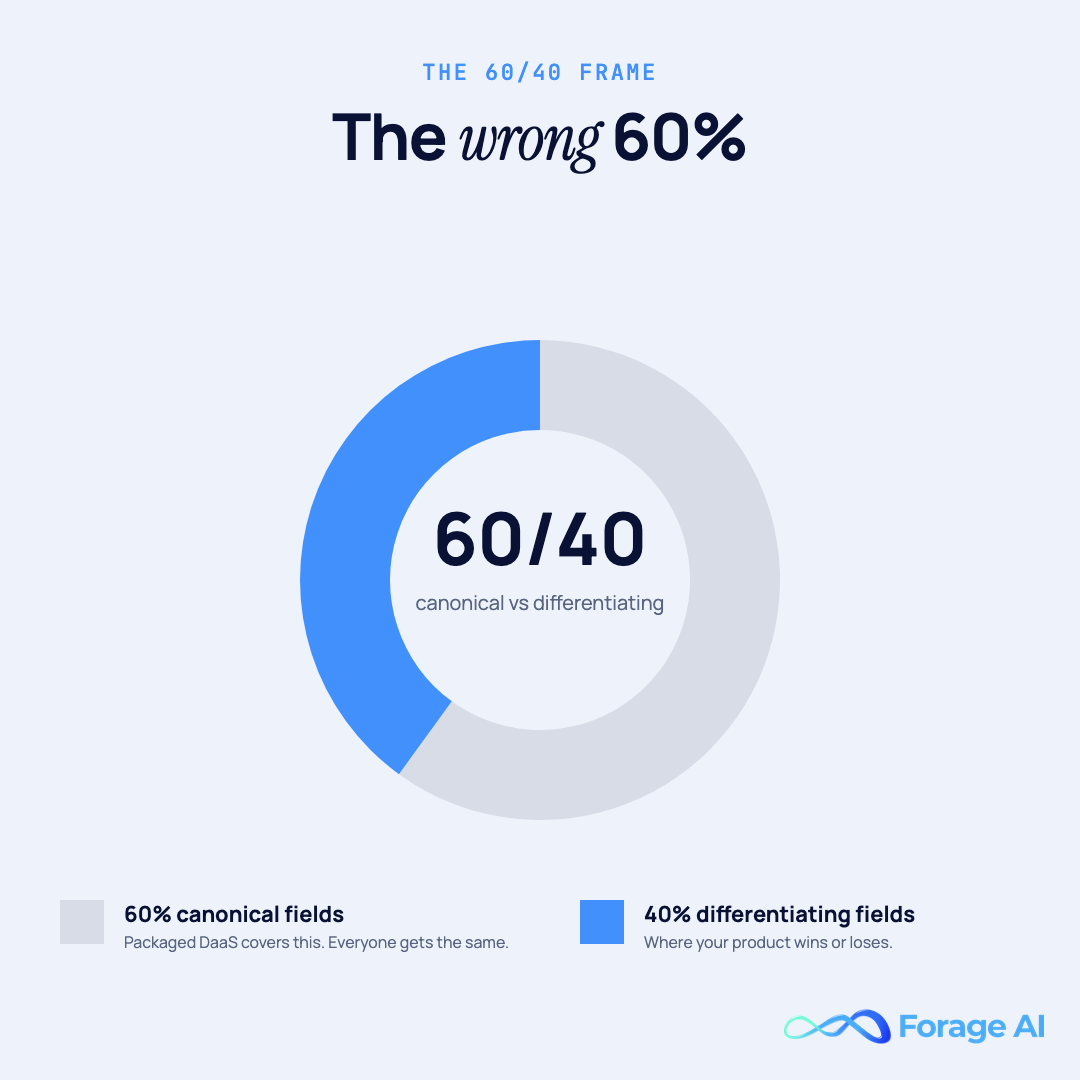
Pre-built datasets are designed to serve the median use case. They cover the fields most buyers in their target segment need most of the time: the canonical 60%. The remaining 40% (the fields that would let your product do something the median customer can’t) is, almost by definition, outside the dataset. We call this the wrong 60%: not because packaged data is wrong, but because it’s the wrong 60% for product builders whose differentiation lives in the other 40%.
The shape of the gap differs by industry, but the pattern is consistent. A healthcare analytics product needs hospital-system affiliation graphs, provider network membership, and sub-specialty practice areas: fields a generic provider directory doesn’t carry. A real-estate intelligence product needs zoning attributes, ownership-entity resolution, and parcel-level utility data: fields beyond what a national listings feed offers. A B2B financial-services product needs deep-nested firmographics (subsidiary structures, ownership cascades, regulatory entity IDs) that don’t fit a flat CRM schema. A regulatory data product needs the URLs for every rule cited, not just the rule itself.
This isn’t a vendor failing. It’s structural. Packaged datasets serve median demand. Differentiating fields are, by definition, non-median. A vendor can’t profitably build and maintain a dataset that includes every long-tail field every buyer wants, so they don’t.
The cost shows up in two places. First, your product roadmap stalls on data dependencies that aren’t in the subscription you bought. Second, and this is the more dangerous one, you start trying to fix it by adding more subscriptions. If you’re already seeing the warning signs that your B2B data provider is limiting your growth, the second pattern is what we cover next.
The AI-readiness dimension makes the gap visible more quickly than before. Gartner’s 2024 forecast projected 60% of AI projects would be abandoned through 2026 due to a lack of AI-ready data. AI/ML training sets need depth, meaning the long-tail fields. Packaged datasets, optimized for median coverage, often fail the readiness check. And MIT Sloan has cited 15–25% of annual revenue lost to poor data quality, much of which traces to the moment a generic schema meets a specific product need.
The 60/40 Frame. Packaged DaaS covers the canonical 60% of the fields your category needs. The differentiating 40% (the fields that make your product yours) is, by definition, not in the package. If your product’s economics live in the 40%, packaged DaaS is incomplete, not wrong.
Quick Summary — Why doesn’t a packaged dataset just add the fields I need? Because the vendor’s business model is built on median demand. A field that’s critical to your product but irrelevant to 80% of their other customers will never make it onto the roadmap. That’s not bad faith; it’s how packaged data is priced.
Expert Insights — When we audit a customer’s existing packaged subscriptions, the field-level gap is usually 30–40% and almost always in the fields they care about most.
The 12-Vendor Sprawl Reality: What Actually Happens When Packaged Isn’t Enough
Most enterprise data buyers do not jump from one packaged subscription to a custom acquisition partner in a single move. They take the long way around, and the long way around is what we call the 12-vendor sprawl.
The pattern is consistent enough to be described as a composite. One global B2B firmographics buyer (anonymized; this is a composite story, not a single named account) bought a primary packaged dataset, filled field gaps within six months, and bought a second dataset to fill them. The second had different gaps, so they bought a third. Three years in, they were managing eight to twelve packaged-data subscriptions, each with its own data dictionary, refresh cadence, and definition of what a “company” was. Buyers often arrive at this point after a long detour through alternatives to Bright Data and similar packaged providers, hoping the next vendor will be the one that finally fits. The team whose actual job had become schema reconciliation (figuring out whether Acme Corp in one feed was the same legal entity as Acme Corporation in another) had grown to thirty to fifty people. The bill, between licenses and headcount, was in the eight-figure range a year.
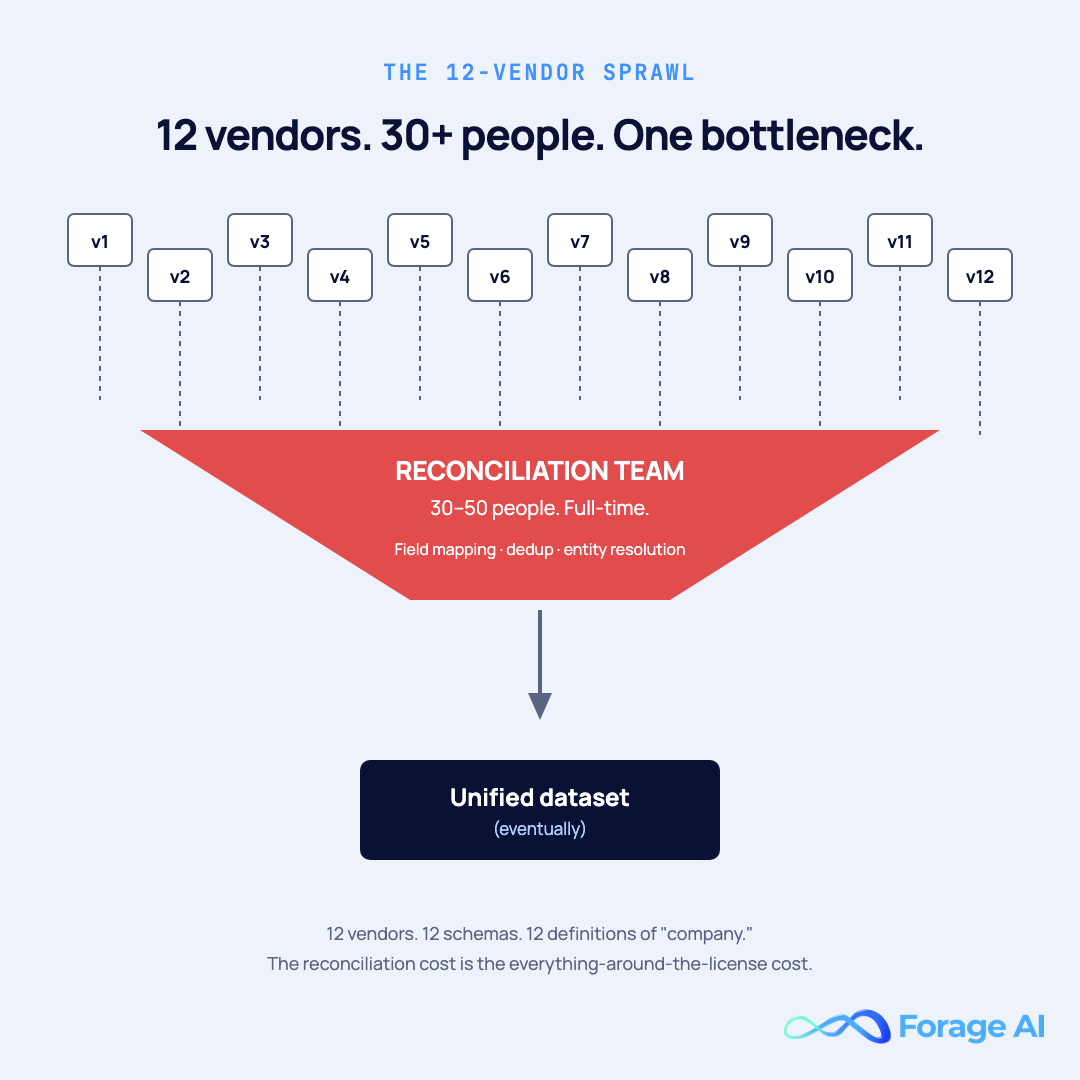
The reason this fails economically isn’t the license cost; it’s the cost of everything around the license. Vendor management, contract renewal, schema reconciliation, dedup against eight different entity IDs, and ongoing drift as each vendor changes their schema independently. And the data still isn’t yours: you don’t own the acquisition layer, you just own the reconciliation cost on top of it. For a more structured walkthrough of how to evaluate vendors before you stack them, our complete guide to selecting a B2B data provider covers the scorecard side of this decision.
The temptation when you’re already deep in vendor sprawl is to “just add one more” to fix the latest gap. That instinct is what makes the pattern self-reinforcing.
The Augmentation Trap. Stitching outputs from N packaged vendors does not produce a custom dataset. It produces an expensive, fragile, never-finished one, with reconciliation as a permanent line item.
Quick Summary — Won’t a few more subscriptions fix the gap? For a quarter or two, maybe. After that, you’ve moved the cost from “missing fields” to “reconciling vendors,” and the reconciliation cost grows with every new feed. The exit isn’t another subscription. It’s a different model.
Expert Insights — Procurement teams in 2026 are pushing back hard on multi-vendor data spend. The consolidation pressure is real, and it’s giving data leaders cover to make the move they should have made two contracts ago.
Custom DaaS: Your Fields, Your Business Rules, Your Cadence, Your Format
If packaged DaaS is a subscription to a dataset, custom DaaS is a managed acquisition relationship for a dataset that doesn’t yet exist: your dataset, built around your product. The vendor doesn’t ship you their schema. They build and operate the acquisition pipeline that produces yours.
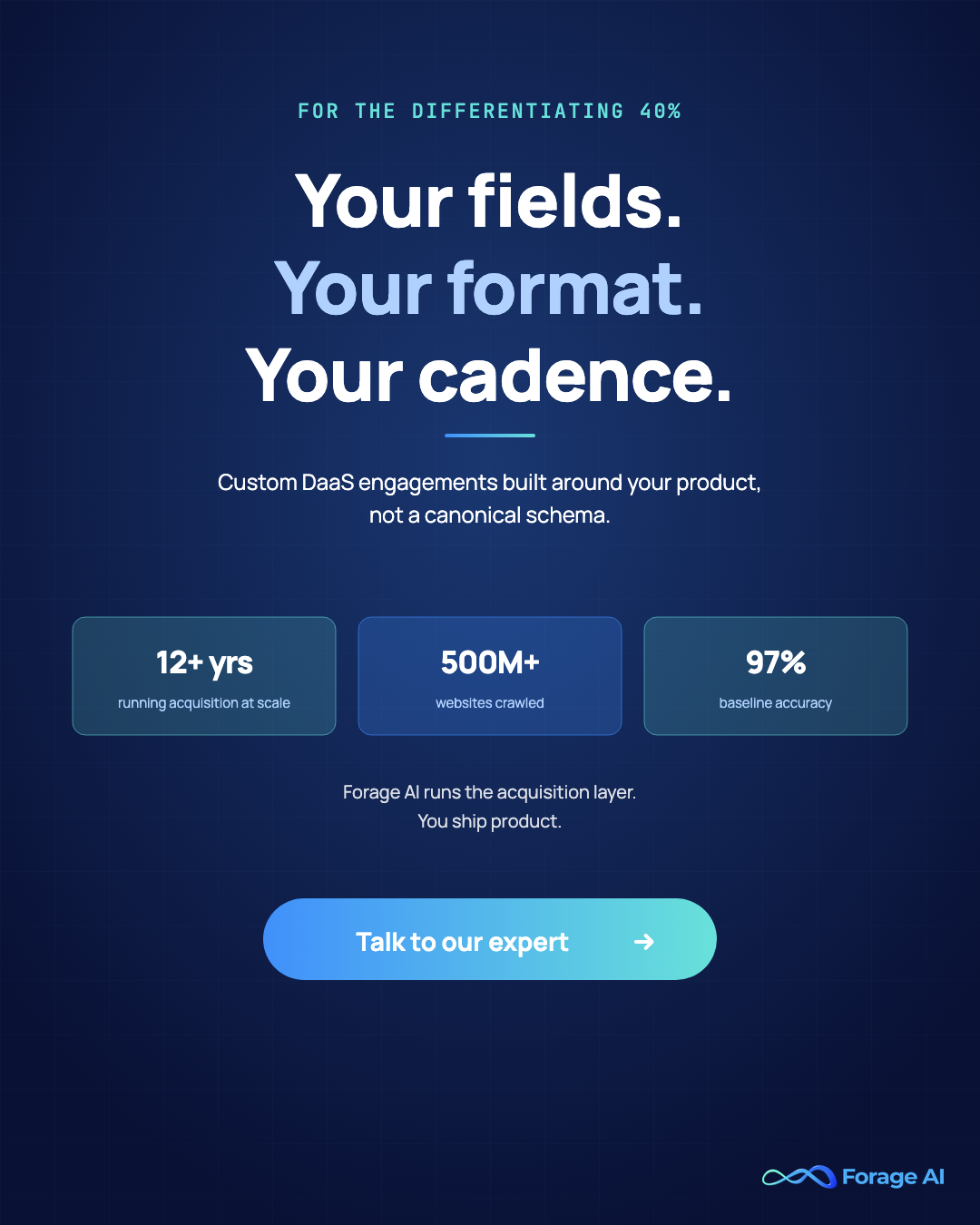
The shape of a custom DaaS engagement comes down to four levers, and the framing is deliberate: your fields, your rules, your cadence, your format.
- Your fields. The field set is built around your product, not a canonical schema. If your application needs hospital-affiliation graphs, ownership cascades, regulatory URLs, or any of the long-tail attributes that packaged datasets skip, those are line items in the engagement, not feature requests to a vendor roadmap.
- Your business rules. Validation, deduplication, entity resolution, and dictionary mapping are embedded in the pipeline rather than run downstream as a separate normalization step. Your definition of “active customer,” your industry taxonomy, your dedup logic: those are part of the data before it lands in your warehouse, not work your team does after delivery.
- Your cadence. Refresh frequency is tied to your decision velocity, not the vendor’s batch schedule. If your product makes calls hourly, the data refreshes hourly. If quarterly is enough, quarterly is what you pay for.
- Your format. Delivery fits your stack: NDJSON for streaming ingestion, Parquet for warehouse drop, SFTP for legacy pipes, direct-to-warehouse for Snowflake or BigQuery, RAG-ready for AI applications, on-prem for regulated environments.

Most enterprise data engineering teams can run pipelines beautifully. They have the talent, the platform, and the discipline. What they generally can’t reliably do is acquire external data at scale. That gap is what automated data extraction at production scale actually solves. The five disciplines that make external acquisition work (anti-bot evasion, long-tail source discovery, parsing and normalization at variable scale, infrastructure that flexes from a million pages to a billion, and continuous monitoring and repair) don’t usually fit into a single job description. They live in a vendor that does only this.
This is why the more useful framing for enterprise buyers in 2026 is “the data acquisition layer” rather than the internal-infrastructure framing. Your warehouse, transformation, and modeling stack is internal infrastructure. Your acquisition layer is the relationship that feeds them. For a deeper read on what this looks like in practice, our piece on custom web data extraction for competitive advantage walks through where the work concentrates, and our modern data extraction services guide covers the broader category.
This is the layer Forage AI operates in. Twelve-plus years running external-data acquisition at enterprise scale, 500M+ websites crawled, a hundred-plus extraction specialists, 97% baseline accuracy moving to 99%+ with human-in-the-loop QA, built specifically to be the acquisition layer for product teams whose differentiation lives in the 40%.
Custom DaaS is not consulting. It’s not custom-scraping-by-the-hour. It’s not a packaged dataset with a sticker on it. It’s a continuous, managed acquisition relationship you don’t have to staff, run, or repair, producing a dataset you own outright.
The Four Custom Levers. Fields, Rules, Cadence, Format. If a vendor can move all four of them to fit your product, you’re looking at custom DaaS. If they can move none, you’re looking at a packaged subscription with a thicker contract.
Quick Summary — How is custom DaaS different from hiring a scraping consultant? Consulting is a project. Custom DaaS is a relationship. The vendor doesn’t deliver a one-time dataset; they own the acquisition layer that keeps it fresh, monitored, and repaired as sources change. Schema drift, anti-bot evasion, and source discovery are their problem, not yours.
Expert Insights — IDC’s longstanding data team productivity work has shown that roughly 82% of data team time is spent on data collection and preparation, with under 20% on analysis, and an Anaconda 2024 survey found that data scientists’ time on data prep is around 45%. The custom-DaaS thesis is that those numbers don’t get fixed inside your team. They get fixed by moving the acquisition layer—and the automated data collection behind it—outside of it.
DaaS Pricing Models: Subscription, Per-Record, Tiered, and Custom-Engagement

DaaS pricing splits along the same packaged-vs-custom line.
On the packaged side, there are three dominant models. Per-seat subscription charges per user are common in B2B contact platforms, where seats correlate with usage. Per-record consumption charges per row returned, common with enrichment APIs. A tiered API offers stepped quotas (free → pro → enterprise), common in developer-facing data products. All three share the same hidden-cost dynamic: the price you signed for is for fields you can use. Fields you can’t use, fields you have to discard or re-derive, and fields the vendor calls correct, but your audit says aren’t, all stay on the bill.
On the custom side, pricing is engagement-priced, not list-priced. The scope, fields, business rules, refresh cadence, volume, and SLAs vary enough between customers that a public rate card would be misleading. The economic argument for custom engagement isn’t “cheaper per record.” It’s “one predictable contract instead of (license + offshore reconciliation team + internal QA overhead + lost engineering cycles).”
The Gartner 2020 number that keeps getting re-cited has staying power for a reason: poor data quality costs the average organization $12.9 million per year. That figure largely reflects the cost of packaged-DaaS shoppers who were undercounted at the time of signing, and the cost of custom-DaaS engagements is sized to absorb.
A note on framing: cost-effectiveness is a real benefit of moving to a custom engagement once you account for the full picture, but it’s never the lead reason. Buyers who lead with cost end up back in the packaged aisle within a year. Buyers who lead with fit stay.
Quick Summary — Why isn’t custom DaaS pricing published? Because the engagement scope (fields, business rules, refresh cadence, volume, SLAs) varies widely across customers. A public rate would mislead. The right comparison isn’t “per record”; it’s “total cost, today and in two years, including the reconciliation team you’d otherwise build.”
Expert Insights — Gartner’s $12.9M figure for poor data quality has held up across multiple updates since 2020 because it’s a composite cost, not a single line item. It’s the operational drag, the missed revenue, and the engineering rework added together. That’s why packaged vs. custom pricing comparisons that look only at the line item are misleading.
Sovereignty: Where Your Data Goes, Who Else Sees It, Who Resells It
Pricing decides what you spend. Sovereignty decides what happens to the data once the contract is live, which, for regulated buyers, becomes the bigger procurement question. There’s a dimension of DaaS evaluation that the SERP almost completely ignores: what actually happens to your queries, fields, and derived data once they enter a DaaS vendor’s perimeter.
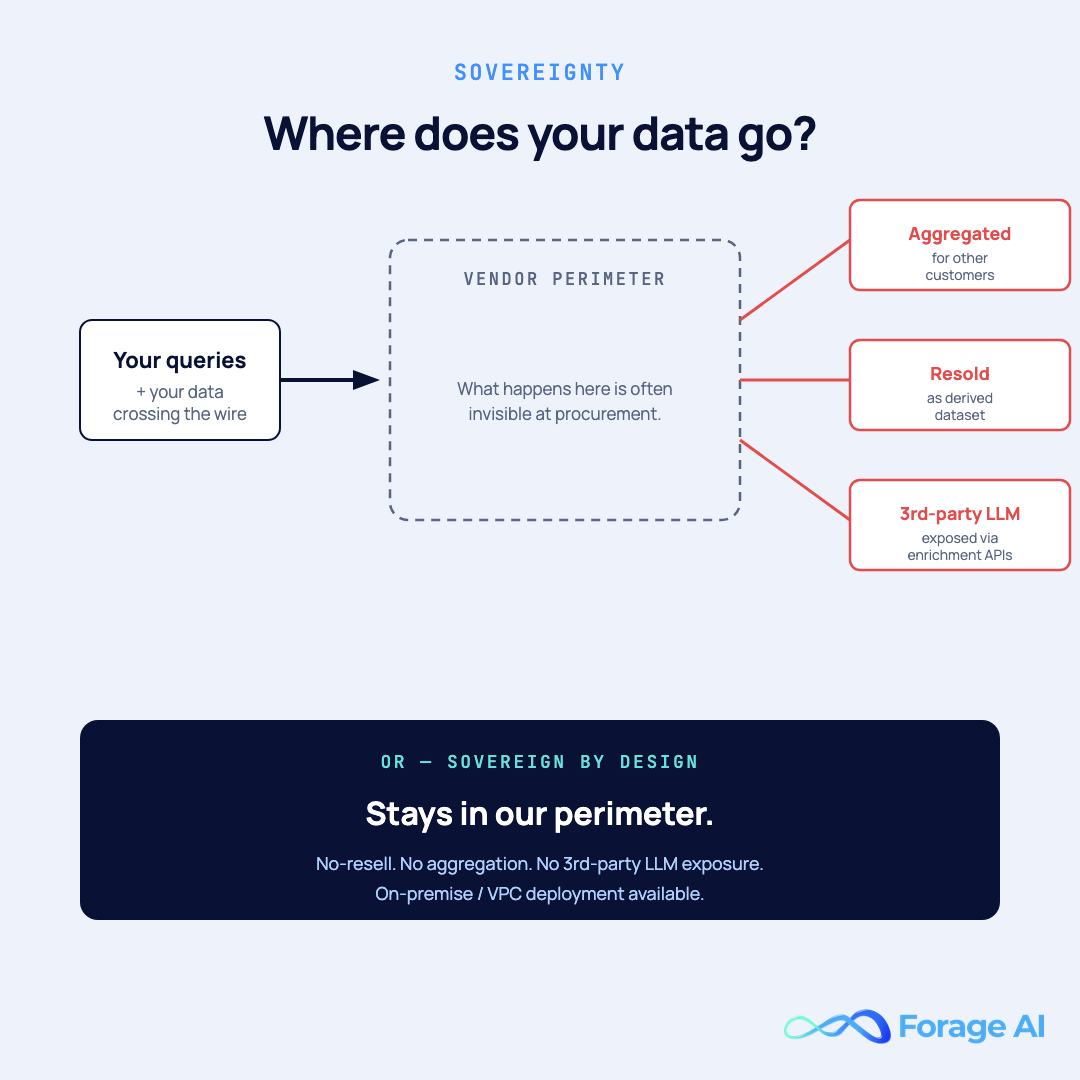
On the packaged side, many vendors aggregate usage signals across their customer base. Some resell derived datasets back to the market; your query patterns help train models that other customers benefit from. Many rely on third-party LLM APIs for enrichment or classification, meaning prompts (and sometimes data) leave the vendor’s environment and enter the model provider’s environment. None of this is necessarily bad, but it’s often invisible at the time of procurement.
On the custom side, the contract is the control surface. Real engagements include explicit no-resell clauses, no-aggregation clauses, no-third-party-LLM exposure when required by the buyer, and on-premises deployment options for regulated environments. SOC 2 compliance is necessary but not sufficient: SOC 2 attests to operational controls, not to whether your data shows up in someone else’s derivative product.
This matters most in healthcare, finance, and legal, where procurement and legal teams now treat data sovereignty as a primary purchase trigger rather than a nice-to-have. In-house data acquisition is increasingly being blocked by legal review, which pushes the question to the vendor: Can you provide contractual cover for where this data lives, who else sees it, and whether you train on it?
For buyers with strict sovereignty requirements (on-prem deployment, contractual no-resell, no third-party LLM exposure), Forage AI’s custom engagements include those terms as standard, not as an upsell.

This article discusses procurement and data-handling considerations at a general level. It is not legal or compliance advice. Consult qualified counsel for your organization’s specific requirements.
Quick Summary — Why is data sovereignty a DaaS decision, not just an IT decision? Because the DaaS model determines what happens to your data inside the vendor’s perimeter. Packaged vendors often aggregate, often resell derived data, and often rely on third-party LLMs. Custom engagements can contractually rule out all three. The difference is built into the model, not bolted on after.
Expert Insights — Gartner’s Andrew White has been consistent on the AI-ready data thesis through 2025 and 2026: AI readiness is increasingly inseparable from data sovereignty, because training-data provenance, lineage, and exclusivity all become procurement requirements once a buyer puts data through an AI system.
A Four-Question Test: Should You Subscribe or Commission a Custom DaaS Engagement?
Here is the framework the article has been building toward. Four questions. If you answer “yes” to any one of them, packaged DaaS is not complete for your use case. If you answer “yes” to two or more, custom DaaS is the right move.

1. Does your product depend on fields that packaged vendors don’t carry? If the fields that make your product different from your category’s median offering aren’t in the canonical schemas of the leading packaged vendors, and you’ve checked, not assumed, that’s the wrong-60% signal. Packaged DaaS can supplement, but it can’t be the foundation.
2. Does your refresh cadence need to be tied to your decision velocity, not the vendor’s batch? If your product needs daily, hourly, or event-driven freshness on data the vendor refreshes monthly or quarterly, the cadence mismatch is structural. You can’t fix it with a faster API tier.
3. Do your business rules need to be embedded in the pipeline, not run after delivery? If your team is doing meaningful dedup, validation, entity resolution, or dictionary mapping on packaged data after it arrives, you’re maintaining a second, hidden acquisition layer downstream. Moving those rules upstream into the pipeline is what custom DaaS is for.
4. Does your delivery format need to fit your stack — NDJSON, Parquet, RAG-ready, on-prem drop — rather than the vendor’s standard API? If your engineering team’s first hour with a new dataset is reformatting it, you’ve signed up for that hour every refresh, in perpetuity. Custom delivery formats permanently remove that work.
This is not a “build vs buy” framework. It’s a subscribe vs commission framework. Building the acquisition layer in-house was already off the table for most enterprise buyers once the five-discipline problem (anti-bot, source discovery, parsing/normalization, scaling, monitoring/repair) became clear. The real question for almost every Head of Data Ops in 2026 is which kind of vendor relationship to be in. For a more detailed read on why the build option keeps falling out of favor, our build vs buy decision guide covers the underlying economics; the broader category context is in our modern data extraction services guide.
The Four-Question DaaS Test. One “yes” → packaged is incomplete. Two or more “yes” → custom is the right move. Zero “yes” → packaged DaaS probably fits, and you should stop reading custom DaaS articles.
Quick Summary — Can a buyer use both packaged and custom DaaS? Yes, and most mature data programs do. Packaged covers the canonical 60% (broad coverage, low-differentiation use cases). Custom covers the differentiating 40% (the fields your product actually competes on). The decision isn’t “which one”; it’s where to draw the line between them.
Expert Insights — In our experience working with enterprise buyers who outgrow packaged DaaS, three signals show up together: refresh cadence frustration, fields the vendor “doesn’t roadmap,” and a reconciliation team that keeps growing. When all three are visible, the conversation has stopped being about subscriptions.
Conclusion
Come back to the moment we opened with: the field you needed wasn’t in the dataset, so you bought another one, then another. The article’s argument is that pattern isn’t a procurement failure; it’s a category-confusion failure. Data as a Service isn’t one decision; it’s two. Packaged DaaS solves coverage. Custom DaaS solves fit. Which one of your product economics demands comes down to whether your differentiation lives in the canonical 60% or in the 40% the vendor’s schema doesn’t carry.
Most enterprise data programs in 2026 are already running in a hybrid mode (packaged for breadth, custom for depth), and the boundary is moving. AI-readiness pressure is making the wrong-60% cost visible faster than it used to, because models exposed to generic data produce generic outputs.
A custom DaaS engagement is often cheaper than the packaged-plus-offshore-plus-reconciliation reality, once total costs are honestly accounted for. Forage AI runs the acquisition layer for product teams whose packaged vendors fall short, including buyers like Vested, where the relationship has delivered 12 consecutive months of 100% uptime. If your product depends on the differentiating 40%, see how that works in practice.
FAQs
1. What is Data as a Service in simple terms? Data as a Service is on-demand delivery of external data via the cloud: someone else acquires, cleans, and maintains the data, and you consume it via a subscription or managed engagement. It comes in two flavors: packaged (a subscription to a pre-built dataset like ZoomInfo or Crunchbase) and custom (a managed acquisition relationship built around your specific fields, business rules, refresh cadence, and delivery format).
2. What’s the difference between packaged DaaS and custom DaaS? Packaged DaaS provides every customer with the same schema and refresh cadence; the vendor owns the dataset shape end-to-end. Custom DaaS builds the acquisition relationship around your product’s specific fields, your business rules (validation, dedup, taxonomy), your refresh velocity, and your delivery format. The right way to pick: if your product depends on fields outside the median schema, custom DaaS is the model.
3. Is ZoomInfo (or Crunchbase, or D&B) a DaaS? Yes, all three are packaged DaaS. They’re the right call when your use case maps cleanly to their canonical firmographic, funding, or credit data schema and coverage matters more than depth. They’re the wrong call when your product depends on fields outside their schema, when your refresh cadence needs to differ from theirs, or when your business rules need to be embedded in the data before it reaches you.
4. How do DaaS pricing models work? Packaged DaaS uses per-seat licensing, per-record consumption, or tiered API access (free → pro → enterprise). Custom DaaS is engagement-priced based on scope, fields, refresh cadence, volume, and SLAs: one predictable contract instead of license fees, offshore reconciliation, and internal QA overhead. The total-cost comparison usually matters more than the per-record line item.
5. How is DaaS different from DBaaS? DaaS delivers ready-to-use data content; you consume the data the vendor has acquired and curated. DBaaS (Database as a Service) delivers managed database infrastructure; you bring your own data and run your own queries, while the vendor handles uptime and scaling. They sit on different layers of the stack and aren’t substitutes.
6. When does packaged DaaS stop working for an enterprise? When the differentiating 40% of your schema isn’t in the vendor’s dataset, when refresh cadence doesn’t match your decision velocity, when your business rules need to be embedded in the pipeline rather than run after delivery, or when your delivery format needs to fit your stack rather than the vendor’s standard API. Any single one of these signals means the package is incomplete; two or more mean custom DaaS is the right move.
Related Articles
- 5 Best E-commerce Data Extraction Solutions for Business Growth — A side-by-side look at e-commerce data extraction solutions for teams pulling competitor pricing, reviews, and catalog data.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




