

Most teams reading this already have scripts running. Cron jobs, a proxy pool, PagerDuty alerts when something dies at 3 am. By every surface signal, extraction is automated. So why does every sprint still carry a scraper bug, and why is the engineering lead asking for a new hire just to keep the pipelines from breaking?
The honest answer is that “automated” is not a binary. In 2026, it is a five-tier maturity progression, and most teams are stuck on a rung that looks organized from the outside and is quietly compounding maintenance cost on the inside. The Fivetran 2026 Enterprise Data Infrastructure Benchmark reports 97% of enterprise leaders have seen pipeline failures delay analytics or AI initiatives. The EU AI Act’s remaining provisions take effect on August 2, 2026, with penalties of up to €15M or 3% of global annual turnover for high-risk AI violations (and up to €35M or 7% for prohibited AI practices). Extraction is no longer plumbing. It is the first mile of every AI and analytics investment the company is making this year.
This article is for data-ops leads and engineering managers who have outgrown their scripts and want a diagnostic, not a sales pitch. It won’t re-explain web scraping. For that, see our Web Data Extraction techniques guide.

QUICK DIGEST
- Data extraction automation is a five-tier ladder: manual, scripted, scheduled, self-healing, and fully managed
- Most teams plateau at Tier 2 (Scheduled) for years because the maintenance tax stays invisible until it’s structural
- The jump from Tier 2 to Tier 3 is architectural; Tier 3 to Tier 4 is organizational
- A 10-question diagnostic at the end tells you which tier you’re actually on and what the next move costs
Why Data Extraction Automation Is a Ladder, Not a Switch
Every top-ranking article on this topic frames automation as a binary. Manual versus automated, tool versus script, buy versus build. That framing serves a reader writing their first scraper. It actively misleads a reader running fifty.
The reality is a progression. Each team sits on a rung. Moving up isn’t a preference; it is forced by source count, refresh frequency, or the emerging gap between what extraction produces and what downstream systems demand. The economics of each rung differ wildly.
Consider the context. 80–90% of enterprise data is unstructured, per CDO Magazine, citing IDC. Gartner puts the average annual loss from poor data quality at $12.9M per organization. IBM places the aggregate US cost at $3.1 trillion. Most of that loss routes through extraction, the step that decides what reaches analytics and AI, and what arrives corrupt.
What Top Articles Get Wrong
The ranking stops at “use a tool” or lists 20 vendors. It never explains why two teams running the same tool get wildly different results. The reason isn’t the tool. It is the architecture around the tool, the governance on top of it, and the organizational decision about who owns what that breaks.
Worth knowing:
- The Fivetran 2026 Benchmark puts average enterprise data-initiative spend at $29.3M/year, yet reliability remains the top blocker
- Barr Moses (Monte Carlo): “AI will only ever be as useful as the first-party data that powers it”
- The global autonomous data platform market is projected from $2.51B (2025) to $15.23B (2033)
Why should I care about extraction tiers if my current system “works”?
Because “works” is a lagging indicator. By the time a Tier 2 system visibly breaks, the team is already burning a third of its capacity on maintenance, and that cost compounds with every new source added.
The Data Extraction Automation Maturity Ladder
The framework. Every subsequent section maps to one tier.
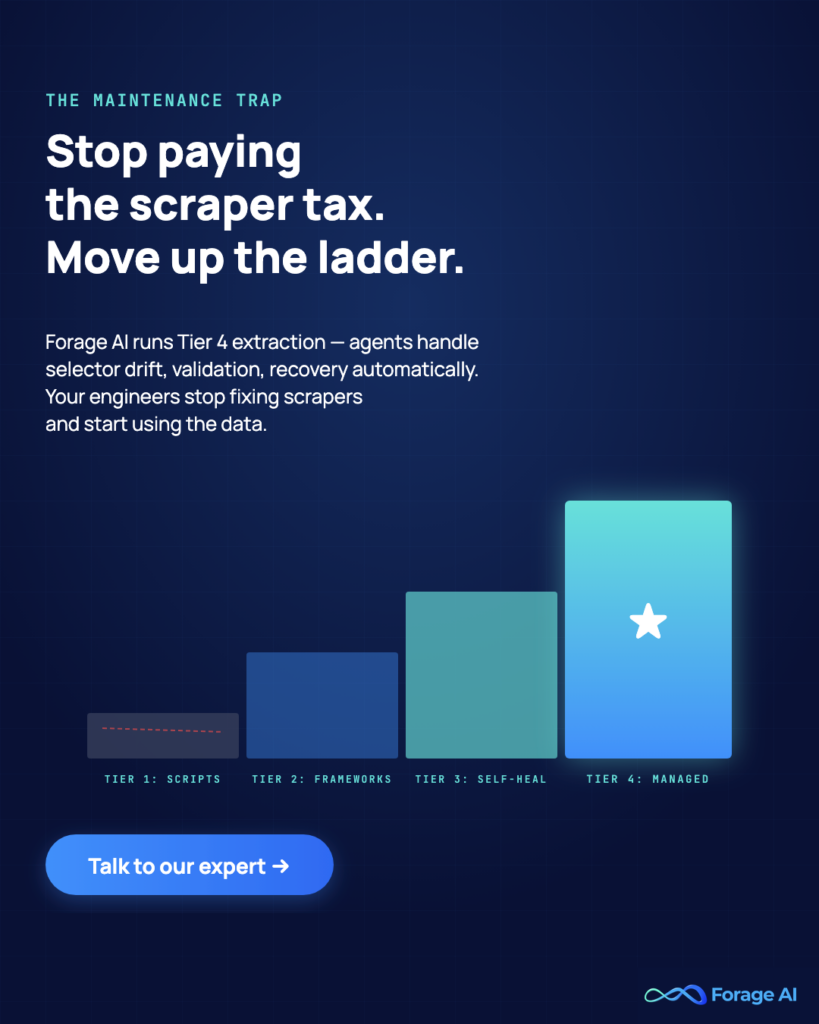
| Tier | Name | What it looks like | Who’s here | The breakpoint |
| 0 | Manual | Pipelines that classify failures, regenerate selectors, validate schema, and recover without human touch | Pre-data-team startups; small research teams | Volume exceeds human capacity |
| 1 | Scripted | Custom Python / Scrapy / Playwright scripts. One engineer knows how it works | Most early data teams | Owner leaves; sources pass ~3 |
| 2 | Scheduled | Orchestrator (Airflow, Dagster, Prefect) + cron + alerts + shared proxy pool | The majority of teams | Maintenance consumes >25% of data-engineering capacity |
| 3 | Self-Healing | Pipelines that classify failures, regenerate selectors, validate schema, recover without human touch | Teams with 3+ senior data engineers and a multi-year horizon | Governance, SLA, or compliance burden exceeds technical capacity |
| 4 | Fully Managed | External partner owns the extraction lifecycle end-to-end; client retains data ownership | Data product builders, resellers, strategic enterprise data teams | This is the top; the question becomes partner selection |
Read it this way: each tier solves the problem created by the tier below it. The jump from Tier 2 to Tier 3 is architectural. New stack, new observability model, new failure discipline. The jump from Tier 3 to Tier 4 is organizational. Someone else owns the lifecycle; the client owns the data and the governance.
What the Ladder Doesn’t Tell You
The ladder doesn’t tell a team where they should be. Five stable sources with weekly refreshes are perfectly healthy at Tier 1 or 2. Don’t pay for Tier 4 capability you don’t need. Reliability at Tier 3 doesn’t guarantee correctness either; schema validation, entity resolution, and QA remain separate problems that have to be designed in.

Worth knowing:
- IBM’s $3.1T figure is a US aggregate; the enterprise-level average of $12.9M (Gartner) is the more usable number for a business case
- Every team that tells us “we’re at Tier 3” is usually at a broken Tier 2
- Being at Tier 3 solves reliability but not governance. EU AI Act audit-trail requirements are a separate bar.
How do I figure out which tier I’m actually on?
Use the diagnostic near the end of this article. Most teams place themselves one tier higher than operational reality supports. A script on a cron is not Tier 2 without schema validation and failure classification.
Tier 0–1: Manual to Scripted, Where Most Teams Start
Tier 0 is someone in a spreadsheet. Rationale for low-volume, high-judgment work: analysts transcribing competitor pricing for ecommerce data scraping, a compliance officer pulling filings. Slow, error-prone, fine at the small scale.
Tier 1 is the first script. Python + `requests` + BeautifulSoup, pointed at a handful of URLs, writing to CSV. LLM-assisted coding has collapsed Tier 0 to Tier 1 to hours. Common stack: Scrapy, Playwright, Crawlee, headless Chromium.
The trap: Tier 1 feels like automation. No retries. No observability. The engineer who wrote it is the single point of failure. With more than three sources or a weekly refresh, it’s already straining. Industry practitioner data suggests 2–4 weeks to build a typical Tier 1 scraper, then 5–10 hours per week per scraper in ongoing maintenance. That number looks small until there are thirty scrapers.
What Tier 1 Will Not Solve
A cron wrapper around a Tier 1 script is not Tier 2. You’ve added a schedule to a fragile system; you haven’t improved the system. The first time the website changes its HTML, the cron runs successfully, writes empty data, fires no alert, and downstream consumers use stale numbers for a week before anyone notices. Catching that silent failure is exactly the job of the best data observability tools for external data pipelines, which watch for stale or broken feeds the scheduler never flags.
Tier 1 also doesn’t handle rate-limit regressions, authentication renewal, proxy rotation at scale, or structured error recovery. For the full manual vs. automated breakdown, see our Manual vs Automated Web Data Extraction comparison.
Worth knowing:
- LLM-assisted scripting (Cursor, Claude Code) has dropped Tier 0 → Tier 1 from weeks to hours, which also lowers the bar for building something brittle
- “No-code” extraction tools often keep teams stuck at Tier 1 longer than writing their own code would
- Year-old Tier 1 scripts typically consume 20–30% of engineering cycles in ongoing maintenance
When does a Tier 1 scraper stop being enough?
When the team can’t answer “how fresh is every source right now?” without asking a specific engineer. That’s the moment scripted extraction is outgrown, and a real orchestration layer is needed.
Tier 2: Scheduled Pipelines, Where Most Teams Plateau

This is the central section. Tier 2 is the ceiling for the vast majority of data teams, and they sit on it for years before someone forces the budget conversation that triggers a move.
Tier 2 looks organized. Airflow, Dagster, or Prefect run jobs on a schedule. PagerDuty or Slack alerts when jobs fail. Shared proxy pool. Dashboards. On-call rotations. So why does every sprint still carry a scraper bug?
The Maintenance Tax
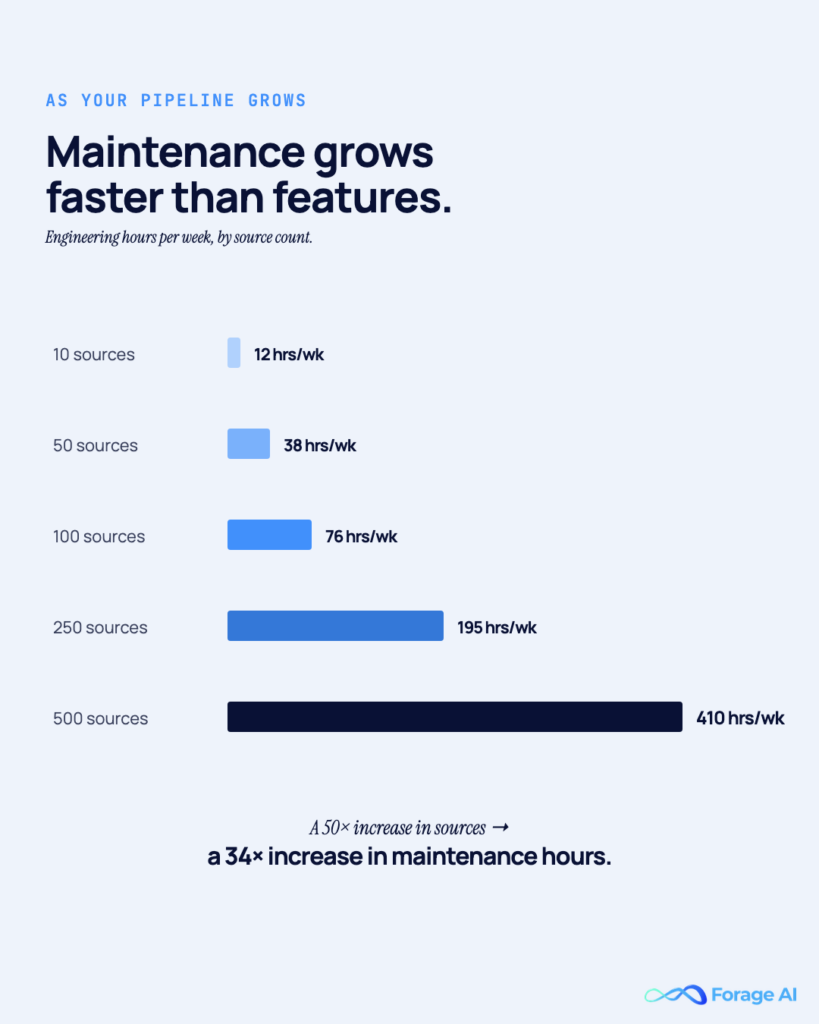
The Monte Carlo 2026 Annual State of Data Quality Survey reports that data teams spend 60–80% of their time maintaining fragile pipeline systems. A publicly cited enterprise case put the number at 40% of data-engineering hours each week spent fixing scrapers. Industry cost analyses find that hidden maintenance costs 60–70% of the total cost of ownership for in-house extraction, and, across software generally, 50–80% of the lifetime cost sits in the maintenance phase.

This is the Tier 2 maintenance tax. Every new source multiplies it. It compounds, rather than adding linearly, because every scraper shares proxy infrastructure, alerting rules, monitoring dashboards, and on-call attention. Adding the thirtieth scraper is harder than adding the third. High-cadence workloads feel it first — the teams running competitor price tracking across dozens of retail sites typically hit this wall well before they hit Tier 3. Retail and marketplace teams running price intelligence across thousands of SKUs are the canonical example: the work survives Tier 2 only until the SKU count outruns the on-call rotation.
Chad Sanderson, who wrote *Data Contracts* (O’Reilly, 2024), makes the point sharply: detection-based data quality doesn’t scale. Alerting tells a team a job failed. It doesn’t tell them the data is wrong. Tier 2 systems are alerting systems. They are not validation systems.
Why Teams Plateau Here
- The system works most of the time. Nobody signs off on rewriting a working system.
- Individual failures are cheap. A broken selector costs an hour to fix. The cost hides in aggregate.
- The team is too busy to refactor. Time that could be spent on architecture is spent on firefighting.
Why Tier 2 Feels Like Automation But Isn’t
The silent failure modes are where Tier 2 actually lives:
- Schema drift. The website adds or removes a field. The extractor runs, returns partial data, and commits it to storage. Downstream consumers never know.
- Silent gaps. Extraction returns zero items. The alert only fires if the job failed, not if it succeeded with an empty payload.
- Cascading auth failures. Token expires mid-run; half the extraction completes, half fails; a re-run creates duplicates.
- Rate-limit regressions. The website tightens its rate limit; the backoff wasn’t built for the new threshold; a silent ban ensues.
A clean Airflow DAG is a clean schedule, not a clean pipeline. If the current operational question is “Did the job complete?” rather than “Was the data correct?”, the team is at Tier 2. For a deeper breakdown of these failure modes, see Why Most Enterprise Data Pipelines Break and Why Product Teams Regret Building Automated Web Scraping In-House.
Worth knowing:
- In-house extraction TCO for ~100 sources typically runs $250K in year 1, $300K year 2, $375K year 3 (industry cost analysis, 2026)
- At enterprise scale, fully loaded in-house cost crosses $10K–$20K/month across proxies, infrastructure, engineering time, and monitoring
- Chad Sanderson’s rule: “If data quality contributes meaningfully to ROI, you need to start thinking about the contract.” Enforcement in CI/CD, not alerts downstream.
How do I know I’ve hit the Tier 2 ceiling?
When adding a new source costs more engineering time than the previous one did. That’s the compounding signature of the maintenance tax, and it only grows.
Tier 3: Self-Healing Pipelines, The Architectural Breakthrough
Tier 3 is the first tier where the pipeline actually thinks. Not in the agentic-hype sense, in the practical sense that the system classifies why something broke and chooses a different path, rather than retrying the same broken action with backoff.

What Self-Healing Actually Means
A 403 response is not a selector mismatch. An empty DOM is not a timeout. A CAPTCHA trigger is not a rate-limit ban. A self-healing pipeline distinguishes between failure classes and handles each differently. That classification step is the heart of Tier 3.
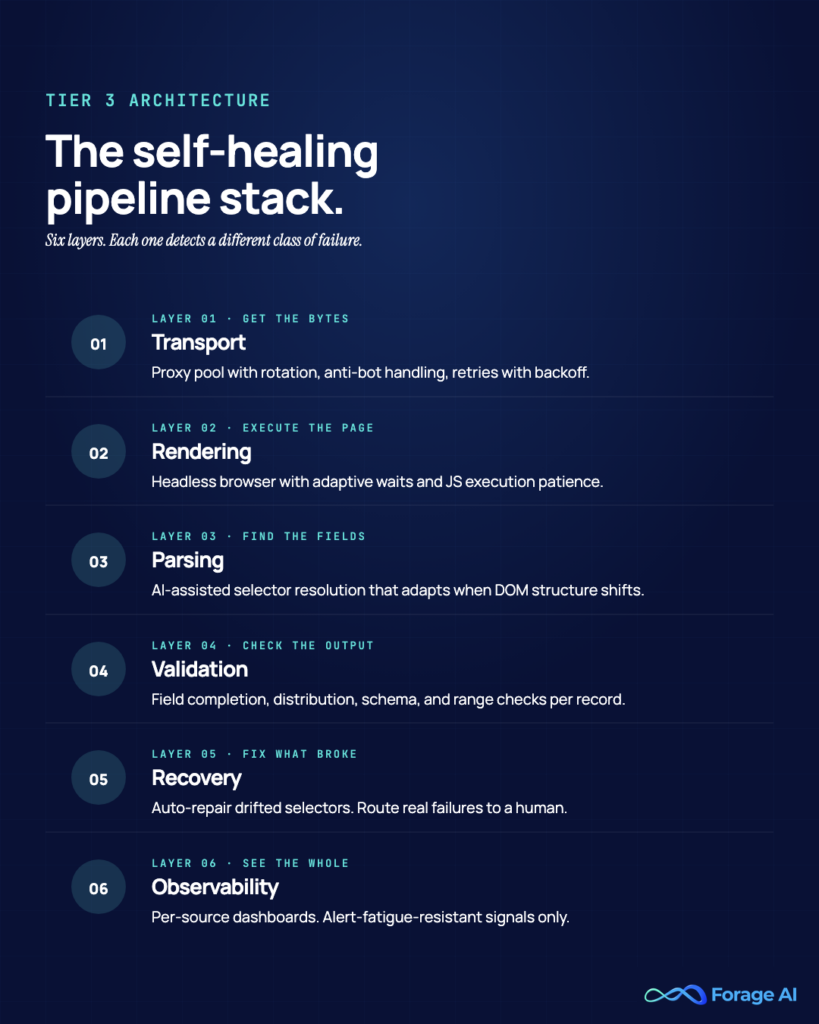
On top of it sit four capabilities:
- Selector regeneration. When a website changes its HTML structure, the system uses an LLM to regenerate the extraction code once, not per page. A 2025 McGill University study found AI-based extraction maintained 98.4% accuracy across 3,000 test pages even after structural changes. Setup drops from weeks to hours.
- Schema validation at write time. Every extraction is validated against a declared schema, using Pydantic in Python or Zod in JavaScript, before it hits storage. If validation fails, nothing is written, and the failure itself becomes a signal.
- Fallback selectors. Every critical field can be extracted in at least two ways. Primary fails → secondary fires. Both fail → classified failure, not silent suppression.
- Observability at the data level. The metric isn’t “job completed.” It’s “extraction succeeded, AND data is structurally valid, AND row count is within expected range.”
The Role of AI (And the Trap)
There are two ways to use AI in extraction:
- AI at runtime: an LLM parses every page. Expensive, slow, and unpredictable. Published benchmarks show accuracy variance as wide as 0–75% on identical tasks.

- AI at setup: an LLM regenerates deterministic extraction code whenever a website changes, and the code runs normally thereafter. Cheap at runtime, adaptive at structural change. This is the approach that scales.
The 2026 Stack
Expect a combination of these in a modern Tier 3 build: Playwright for rendering, Crawlee or Scrapy for orchestration, Pydantic or Zod for validation, and, increasingly, MCP (Model Context Protocol) servers. MCP, released by Anthropic in November 2024, has become the default protocol for AI agents that invoke extraction capabilities, such as functions.
What Tier 3 Will Not Solve
- Source discovery. Self-healing assumes the team already knows what to extract. Figuring out what is a separate problem.
- Compliance documentation. A pipeline can hit 98% reliability and still fail an EU AI Act audit without tamper-resistant logs.
- Human-in-the-loop QA. For high-stakes data (legal, financial, medical), automated validation isn’t enough. Tier 3 reduces noise; it doesn’t replace expert review.
Building Tier 3 in-house is realistically a 6–9 month project for 2–3 senior data engineers, plus an observability stack and a schema-governance discipline maintained indefinitely. Forage operates Tier 4 pipelines that behave this way at runtime. Pipelines self-update when websites change, across 500M+ websites crawled over twelve years. The difference between buying and building is discussed in the next section.
For the deep dive on Tier 3 patterns, see Most Reliable Ways to Automate Enterprise Web Data Extraction and Best AI Agent Solutions for Large-Scale Web Data Extraction.
Worth knowing:
- Agentic AI traffic grew ~7,851% year-over-year in 2025–2026; AI scraper traffic grew ~597% (Information Age / ACS 2026)
- MCP is becoming the default integration layer for AI-to-web, but it doesn’t fix reliability; it collapses integration friction
- Chip Huyen (AI Engineering, O’Reilly 2024): pipeline brittleness, not model quality, is the dominant bottleneck for production AI
What’s the difference between scheduled scraping and a self-healing pipeline?
Scheduled scraping runs a script on a timer and alerts when jobs fail. A self-healing pipeline classifies why a job failed, regenerates extractors when a website’s structure changes, validates output against a schema, and recovers without human intervention.
Tier 4: Fully Managed, The Top of the Ladder
Tier 4 is an organizational decision, not a technical one. The team stops owning the extraction lifecycle and hands it to a partner who owns pipeline design, QA, monitoring, maintenance, and delivery, while retaining full data ownership, governance, and lineage.
Not every team needs Tier 4. Stable source counts, low refresh frequency, and in-house expertise can rationally stop at Tier 3. But with >100 sources, daily refresh, SLAs to paying customers, or downstream AI systems, Tier 4 is almost always cheaper, faster, and safer than continuing to build in-house.
What Fully Managed Actually Includes
Genuine Tier 4 goes beyond what a tool vendor or reseller can offer:
- Source discovery and evaluation. The partner helps decide what to extract, not just how.
- Layered QA: AI + human review as a continuous workflow, not a one-off. This is the 200% QA model: every extraction goes through automated checks and expert human verification. It’s the only model that consistently produces data clean enough for downstream AI training or paying customers.
- Domain expertise. Operators who have seen the industry’s data patterns before.
- Dedicated team continuity. The same engineers maintain the pipelines on a quarter-to-quarter basis.
- Governance by design. Audit trails, data lineage, no-resell guarantees, and on-prem deployments for sensitive workloads.
Forage operates at this tier. The scale that makes Tier 4 feasible: 500M+ websites crawled, 10M+ documents parsed, 100+ data experts, a QA team 3x the industry average, and reinforcement learning from human feedback baked into every pipeline so extraction quality improves with each run. That depth is the compounding advantage of a managed approach, not a feature list.

Why Layered QA Only Works Here
Competitors routinely advertise “AI + human review” at every tier. In practice, it only works at Tier 4. The volume to justify a dedicated QA team, the feedback loops that turn human corrections into model improvements, and the organizational separation between extraction operators and QA reviewers: none of that fits inside a tool license.
Compliance as Infrastructure in 2026
The remaining provisions of the EU AI Act enter into force on August 2, 2026. Extraction feeding high-risk AI needs:
- Automatic tamper-resistant logging of every extraction event
- Article 11 technical documentation tying each output to source material, model version, and policy
- Transparency obligations to downstream deployers and affected persons
- Training data governance with verifiable deletion tests
Raconteur’s 2026 EU AI Act audit guide puts it clearly: “In the 2026 compliance environment, screenshots and declarations are no longer sufficient. Only operational evidence counts.” A Tier 2 or 3 system rarely produces that evidence by default. Tier 4 partners build it in because they have to; they carry the audit risk with the client.
What Tier 4 Will Not Solve
- Loss of control. This is the common fear, and it’s misplaced at reputable partners. Data ownership, lineage, and no-resell guarantees are standard and should be in the contract.
- Sub-scale workloads. Ten sources, no growth plan, the Tier 4 economics don’t work.
- The team can’t articulate the scope. A partner can help scope. It cannot decide on a strategy.
For real numbers on the build-vs-buy calculus, see our 2026 Budget Analysis on Services vs In-House Teams and the full services landscape guide. For how layered QA works in practice, see Human-in-the-Loop Data Extraction.
Worth knowing:
- Thermo Fisher automated 53% of its 824K annual invoices, cutting processing time by 70% (case study collection, 2025)
- Allianz cut claim settlement time 80% via managed extraction + automation
- Eletrobras moved accuracy from 50% to 92% on 65K documents/year, saving $277K annually
- One enterprise replaced a 15-person manual team with an AI-driven managed system: year-1 cost dropped $4.1M → $270K, accuracy rose 71% → 96%

When does moving to Tier 4 make financial sense?
When extraction supports a product customers pay for, when the team carries SLAs or compliance obligations, or when the system is past ~100 sources with daily refresh. At that scale, Tier 4 TCO is consistently lower than in-house Tier 3.
How to Automate Data Extraction from Websites (The Operational Playbook)
Zooming into the web-extraction-specific mechanics, because this is the most common automation starting point. Document extraction follows similar principles but with IDP-specific wrinkles, which are a separate discussion.
The Order of Operations
- Check for a public API first. APIs are 10–100× faster than HTML parsing, with no rendering overhead and no anti-bot exposure. If a clean API exists, use it.
- Respect rate limits. Most production targets tolerate 0.5–10 requests/second, depending on website size. Implement exponential backoff. Honor robots.txt.
- Rotate proxies for high-volume or blocked targets. Residential proxies are slower but cleaner; datacenter proxies are faster and cheaper but easier to flag.
- Headless browser only when necessary. If the data lives in static HTML, don’t pay the Playwright tax. If JS execution or interaction is required, Playwright is the default in 2026.
- Validate against a schema on every write. Non-negotiable. Pydantic or Zod. If the schema fails, nothing writes.
- Retry with classification, not blind backoff. 403 → proxy rotation; selector miss → fallback logic; timeout → exponential retry.
- Monitor data shape, not just job status. Alert when extraction drops to zero items or error rates exceed 10%.
- At least two selectors per critical field. Primary + fallback. A single selector is a latent bug.
What This Playbook Will Not Handle
This is a Tier 2–3 checklist. It won’t resolve source discovery, compliance evidence, or domain-specific validation. It also won’t save a team running it against thousands of sources with a team of two; the maintenance math breaks. For the enterprise-scale version, see our deep-dive into the Enterprise Web Data Extraction Infrastructure.
Worth knowing:
- A small set of patterns (APIs-first, rate limits, proxy rotation, schema validation, classified retries, data-shape monitoring) covers roughly 90% of production failure modes per 2026 industry best-practices research
- Per-page LLM extraction runs at fractions of a cent via vision models, but only when AI is used at setup, not at inference
- Cloudflare‘s 2025–2026 bot-detection updates mean residential proxy + real browser fingerprinting are now baseline, not advanced
What’s the first thing to check before automating extraction from a new website?
Whether it exposes a documented or discoverable API. An API call is consistently 10–100× faster and more reliable than scraping rendered HTML.
The 2026 Stack: Agentic AI, MCP, and What Actually Changed This Year
Three shifts define 2026, and most pre-2024 content misses them.
From Scripts to Agents
Classic scraping was procedural: fetch the URL, apply a selector, write the output. Agentic extraction is goal-oriented: observe the page, reason about structure, decide the extraction path, validate the result, and recover if needed. When the website changes, the agent adapts.
This isn’t speculative. It’s running in production. Information Age / ACS 2026 reports agentic AI traffic grew ~7,851% YoY in 2025–2026; AI scraper traffic grew ~597% in the same window.
MCP as the New Default Protocol
Model Context Protocol (Anthropic, November 2024) has become the default way AI agents interact with tools. For extraction, LLM clients can invoke extraction capabilities like functions. MCP doesn’t fix reliability. It collapses integration friction.
Compliance as Part of the Stack
The EU AI Act’s August 2, 2026, deadline isn’t a future problem. It’s this quarter’s problem for most teams reading this. Penalties for high-risk AI violations reach €15M or 3% of global turnover (and €35M or 7% for outright prohibited AI practices). Article 11 documentation, tamper-resistant logging, and transparency obligations apply to any high-risk AI system, and extraction feeds most of them.
Barr Moses’s 2026 predictions land the point: “We need to move beyond traditional notions of data quality, to establish tools, standards, and processes to improve the health and performance of the data pipelines that will ultimately feed our AI.” A Tier 4 partner is one answer to that mandate. Not because managed is inherently better, but because the audit risk is shared and the compliance infrastructure comes in the contract.
What the 2026 Stack Will Not Do
- Agents are not deterministic. Expect variance. Build validation around them; don’t trust them blindly.
- MCP is a protocol, not a product. It doesn’t handle auth, rate limits, or data quality.
- Compliance posture doesn’t come with the tool. It has to be designed into logging, lineage, and governance.
Worth knowing:
- Gartner 2026 prediction: AI-enhanced workflows reduce manual data-management intervention by ~60% by 2027
- Autonomous data platform market projected 6× growth: $2.51B (2025) → $15.23B (2033)
- Chip Huyen’s thesis, that pipeline brittleness is the real bottleneck for production AI, is landing with regulators; 2026 audit frameworks increasingly treat brittle pipelines as negligence
Does the EU AI Act apply to US-based extraction systems?
Yes. If the extraction feeds AI products deployed to EU users, the system is in scope. Tamper-resistant logging, Article 11 documentation, and source-to-output lineage are required regardless of the company’s headquarters.
Self-Assessment: Which Tier Are You Actually On?

Score honestly. Most teams place themselves one tier higher than operational reality supports.
The Ten-Question Diagnostic
- Can you answer “how fresh is every source right now?” without asking a specific engineer?
- When a source changes layout, does your system notice within an hour?
- Do you have schema validation for every write during extraction?
- When extraction returns empty, does the system distinguish “empty because broken” from “empty because no new data”?
- Is more than 25% of your data-engineering capacity going to extraction maintenance?
- Can you produce a signed audit trail from output back to source, model version, and governing policy?
- Do you have a named person whose sole responsibility is extraction QA?
- When you add a new source, does it cost less engineering time than the previous one did?
- Is your extraction SLA contractually guaranteed to downstream consumers?
- Do you retain data ownership and lineage independent of any extraction provider?
How to Read Your Score
- Mostly “no” on 1–4: Tier 1 or a broken Tier 2, regardless of what the architecture diagram says.
- “Yes” on 5: Stuck at Tier 2; the maintenance tax is compounding. Build vs. buy is urgent, not theoretical.
- “Yes” on 1–4 but “no” on 6–9: Tier 3 for reliability, Tier 2 for governance. That gap is an audit risk under the EU AI Act.
- “Yes” on most of 1–9: Tier 3 or Tier 4. The question is now partner selection, not architecture.
The Build-vs-Buy Overlay
If the team is stuck at Tier 2 and deciding what’s next, the choice is between building Tier 3 (6–9 months, 2–3 senior data engineers, ongoing investment) and buying Tier 4 (managed by a partner, with the lifecycle owned). The right answer depends on how strategic extraction is to the product, how many sources need to scale, and whether compliance obligations push audit-evidence generation onto a partner.
For the full decision framework, see the Build or Buy Strategic Guide. For budget math, the Services vs In-House 2026 Budget Analysis. For the QA architecture that makes Tier 4 work, Human-in-the-Loop Data Extraction.
Worth knowing:
- Most teams moving from Tier 2 to Tier 4 do so after a specific failure event, such as a broken vendor, a failed audit, or a product incident, rather than a planned migration
- Teams that try to skip Tier 2 → Tier 4 without addressing governance end up with outsourced reliability but unresolved data-ownership gaps
How do I know I’m ready to move to a fully managed partner?
When extraction is strategic to the product, maintenance is eating up >25% of data-engineering capacity, and the compliance posture requires audit evidence that the current stack can’t provide. That’s the moment Tier 4 ROI becomes clear.
Frequently Asked Questions
What is data extraction automation?
Data extraction automation is the use of software, such as scripts, orchestrators, AI agents, or managed services, to collect data from websites, documents, APIs, and other sources without manual effort. It sits inside the broader practice of automated data collection as its execution layer — the rung where reliability, change-detection, and recovery actually live. In 2026, it spans a five-tier maturity ladder: manual, scripted, scheduled, self-healing, and fully managed.
How does data extraction automation actually work?
It combines a transport layer (proxies and rate limiting), a rendering layer (HTTP or a headless browser), a parsing layer (selectors and AI-generated extractors), a validation layer (schema checks), and an observability layer (monitoring for silent failures). Higher tiers add failure classification, self-healing recovery, and managed QA on top.
What’s the difference between scheduled scraping and self-healing pipelines?
Scheduled scraping runs scripts on a timer and alerts when jobs fail. Self-healing pipelines classify why a job failed, regenerate extractors when website structures change, validate output against a schema, and recover automatically. Most teams calling themselves “automated” are scheduled, not self-healing.
Is AI-based data extraction reliable enough for production?
Yes, when designed correctly. The 2025 McGill University study found AI-based extraction maintained 98.4% accuracy across 3,000 pages, even after structural changes. The key is using AI for setup and selector regeneration, not per-page inference, which combines AI’s adaptability with deterministic runtime cost.
How much does it cost to automate data extraction at scale?
In-house Tier 3 extraction for ~100 sources typically costs $250K in year 1 and climbs to $375K by year 3, with maintenance consuming 60–70% of total cost. Fully managed (Tier 4) services are often cheaper at that volume because the maintenance burden is shared and amortized across shared infrastructure.
When should I build in-house versus buying a managed extraction service?
Build if the team has 3+ senior data engineers, fewer than ~50 stable sources, and extraction is strategic. Buy if extraction supports a downstream product, SLAs are contractual, compliance obligations (EU AI Act, HIPAA, SOC 2) apply, or the system needs to scale past 100 sources at daily refresh.
What are the compliance requirements for automated data extraction in 2026?
The EU AI Act’s remaining provisions apply from August 2, 2026, with penalties of up to €15M or 3% of global annual turnover for high-risk AI violations (rising to €35M or 7% for prohibited AI practices). Extraction systems feeding high-risk AI must produce tamper-resistant logs, Article 11 documentation, and audit trails that tie every output back to the source material, model version, and policy.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




