

It is a Sunday afternoon in a conference room. The closing books for a $1.2 billion carve-out are stacked on the table: 826 documents, 41 jurisdictions, and four bidder iterations of every NDA. The senior associate has not slept properly since Thursday. Counsel for the buyer is asking for an updated change-of-control summary by 7 a.m. Monday. Nobody on the team is reading every page anymore. They are skimming, sampling, and trusting that the diligence binder is clean.
This is what legal document processing is supposed to fix. The promise sounds clean: classify every incoming document, extract the load-bearing clauses, validate against the term sheet, route exceptions to a partner. The promise is also where most legal-tech projects quietly fail. Not because the technology cannot extract, but because the technology that extracts often cannot be defended in a privilege review, cannot keep client memoranda within the firm’s perimeter, and cannot withstand the variability of real legal documents.
This guide is for the Legal Ops Director who has tried point tools, hit a wall, and now has to convince a Managing Partner, a General Counsel, and a Compliance lead simultaneously. We will cover what legal document processing actually is in 2026, the seven document types that defeat templated review, the privilege-waiver precedent that quietly broke most public AI tools for law, the IDP-plus-human-review architecture that survives both a state bar review and a Big Four audit, and the seven vendor questions that separate the partners that hold up from the ones that demo well.
Quick Digest
- Lawyers spend ~2.1 hours per day, 26% of the working day, on document drafting and review tasks that can be automated (Thomson Reuters Legal Technology Survey 2025). Returning that time to higher-value work is the operational case.
- Seven document types defeat templated review: multi-party contracts, case files and pleadings, regulatory filings, deeds and leases, eDiscovery production sets, M&A diligence binders, and privileged client memoranda.
- Public GenAI tools now waive attorney-client privilege. Judge Rakoff confirmed in February 2026 that submitting privileged content to ChatGPT, Claude, or Gemini equals disclosure to a third party. Most legal SaaS routes documents through those same models.
- The defensible architecture is layered: enhanced OCR, ML-based extraction per document family, rule-based validation, human-in-the-loop review for exceptions, and write-back to the firm’s DMS or CLM. No single layer carries the accuracy on its own.
- The audit trail required for legal work is page-level cite-back, not document-level confidence scores. Every extracted value links to its source span, model version, and reviewer ID.
- Automation surrounds the lawyer’s judgment; it does not replace it. Intake, extraction, clause validation, and binder indexing are high-fit. Negotiation, opinion work, and privileged advice are not.
- Sovereignty is the swing factor on every legal IDP deal. Most procurement reviews die at the question “where does the document actually get processed?” Sovereign-by-design IDP (no third-party LLMs in the path, on-prem and VPC-ready) clears the gate.
- The ROI case for the GC and the firm COO is hours returned plus error reduction: 65 to 80% reduction in first-draft production time on standard matters, and error rates drop from 4.2% manual to under 0.5% automated (ALM Intelligence).
- Seven evaluation criteria separate partners that survive Legal review from those that pass on the demo floor: no third-party LLM in the path, on-prem/VPC option, cite-back audit trail, legal-format coverage, human-in-the-loop QA, DMS/CLM integration, and privilege-waiver indemnification.
What legal document processing actually is in 2026
Legal document processing is the combination of intelligent document processing (IDP), business-rule validation, and human-in-the-loop review that turns the unstructured artifacts of legal work, contracts, filings, pleadings, deeds, and memoranda into structured records that downstream systems can consume. It covers intake classification, clause-level extraction, jurisdiction and party validation, exception routing, and write-back to the firm’s document management system (DMS) or contract lifecycle management (CLM) platform.
It is not a system that gives legal advice. Counsel still owns the opinion, the negotiation, and the strategy. Automation belongs in the document handling, classification, extraction, and validation layers that surround a lawyer’s judgment, never on top of it. Readers new to the technology stack underneath this work will get a faster orientation from our OCR vs IDP comparison; this guide assumes you already know why plain OCR is not enough for legal documents.
The 2026 environment is different from the 2023 environment in three structural ways. Privilege rules now cover AI exposure. Most state bars have followed the ABA in clarifying that submitting privileged content to a public AI tool implicates the duty of confidentiality, and a US District Court ruling in February 2026 has made that case law. Adoption has crossed the Rubicon. Thomson Reuters reports generative AI usage at 28% in law firms and 23% in corporate legal departments in 2025, with 53% of small firms and solos integrating generative AI into their workflows (up from 27% in 2023). And vendor stacks have multiplied: CLM, contract drafting, eDiscovery, IDP, legal research, and matter management each have their own tools, each touching the same privileged documents.
Expert Insight. The cleanest definitional line we use with firm leadership: if the system would ever generate a final piece of advice without a human signing off, it is out of scope. If the system says “this matter is ready for an associate, here are the extracted clauses and the flagged exceptions,” it is in scope. The boundary is the legal judgment, not the document.
Quick Summary. “Is legal document processing the same as a CLM?” No. A CLM stores and manages contracts after they exist. Legal document processing is the layer that turns inbound, unstructured legal documents into the structured records a CLM, DMS, or matter system can use in the first place.
The seven legal document types that defeat templated review
Most legal-tech demos show a clean, well-formed contract being read correctly and call it a day. Real legal documents are messier than the demo. These seven document classes are where templated extraction stops working, and where the gap between vendor accuracy claims and field performance shows up under load.

- Multi-party contracts. Master services agreements, joint ventures, and partnership deeds carry heavy redlining, track-change residue, multi-counterparty annexes, and side letters. A clause-extraction model trained on a clean buyer-seller NDA does not survive a 12-party joint venture document. Real-world contract data extraction has to handle this variance per clause family, not per document template.
- Case files and pleadings. Court-stamped filings, exhibits, depositions, expert reports, and witness statements arrive in formats that vary by court, state, and filing system. Templated OCR misses exhibit references, footnotes, and handwritten judicial markings.
- Regulatory submissions. SEC 10-Ks, FDA NDAs, HSR antitrust filings, and FTC second requests. Tables, schedules, footnotes, and supporting exhibits can add up to thousands of pages. Each regulator’s filing system has its own structural quirks.
- Deeds, titles, and lease addenda. County-recorder PDFs and multi-jurisdiction lease addenda. Real estate documents specifically defeat single-template OCR because the format varies county by county, and the same document family will arrive scanned, born-digital, and re-photocopied within a single binder.
- eDiscovery production sets. Mixed-format dumps with email, attachments, OCR’d scans, native files, and metadata. Technology-assisted review (TAR) is now standard in large litigation, but the underlying IDP layer must handle format variance before TAR can do its job.
- M&A diligence binders. 800-document data rooms with mixed PDF, DOCX, scan, and image formats. The clause that decides the price often sits on page 41 of a 60-page schedule. Templated review at this volume is the single biggest predictable failure mode in transactional practice.
- Privileged client memoranda. Internal opinions, work product, ethics memos. This is the document family that cannot leave the firm’s perimeter under any circumstances. Any IDP solution that routes through third-party LLMs is structurally excluded from this category by design.
Templated review works on documents that do not vary. Legal documents always vary, and the variation is the work product. That is why teams that try to standardize their way into automation discover that the standardization itself is the bottleneck.
Expert Insight. The accuracy benchmark we trust on legal files is clause-level by document family, by jurisdiction. A vendor reporting “94% accuracy on contracts” is hiding the fact that simple NDAs are perfect and 12-party joint ventures are 60 percent. Counsel only cares about the documents where the accuracy is hardest to achieve.
Quick Summary. “Why does templated review keep failing on legal documents?” Because templates assume document stability and legal documents are structurally unstable. Per-family extraction with ML plus rules plus human-in-the-loop is the only architecture that survives the variance.
The privilege problem: why most legal SaaS quietly fails Legal review
This is the section most legal-tech vendors pitch. Almost every IDP and contract-review SaaS product on the market today routes documents through third-party large language models, OpenAI, Anthropic, Google, or one of the major hyperscaler-hosted variants, to do the heavy lifting of parsing, summarization, and clause extraction. For most use cases, that is operationally fine. For legal work, it is a privilege problem with case law behind it.

In February 2026, US District Judge Jed S. Rakoff confirmed that sharing confidential information with a publicly available GenAI tool waives both the attorney-client privilege and the work-product doctrine. The reasoning is straightforward: submitting privileged content to a third-party model is, legally, disclosure to a third party. Privilege does not survive disclosure.
The operational consequence is that any document-processing tool whose extraction pipeline hits OpenAI, Anthropic, Google, or any other third-party LLM hands the firm or the legal department a privilege risk it did not have before procurement signed the contract. Vendor terms that “do not train on your data” do not solve this; the test the courts apply is disclosure to a third party, not training. Once the document leaves the perimeter, the privilege analysis is over.
This is the gate at which most legal-IDP deals quietly die. Compliance asks for the sub-processor list. The list has five LLM vendors. The legal review ends. The procurement team moves on.
The way Forage AI is built avoids this category of risk by design. Extraction runs within Forage’s own systems, with on-premises and VPC deployments available for environments where the documents must remain within the firm’s perimeter. No third-party LLM sits in the data path. Client data is never sent to public AI services, never aggregated across clients, never resold, and never used to train external models. SOC 2, GDPR, and HIPAA-compliant workflows are not configuration options; they are how the service is built. Detail: forage.ai/intelligent-document-processing.
Expert Insight. The fastest way to lose a legal-IDP deal in 2026 is to hand the General Counsel a sub-processor list with five upstream LLM providers on it. The fastest way to win the same deal is the one-line answer: no third-party LLM in the data path, on-prem or VPC deployment, audit trail per extraction. Procurement gates have moved upstream; a contract that says “we do not use OpenAI” closes more legal-ops business than any feature bullet.
Quick Summary. “Why is sovereignty the swing factor in legal IDP?” Because Judge Rakoff’s February 2026 ruling turned third-party LLM routing into a privilege-waiver risk. Tools that process privileged content outside the firm’s perimeter fail the legal review, even if they win the demo.
The defensible architecture: IDP plus human review for legal work
The pattern that holds up at scale on legal documents is layered. No single layer carries the accuracy on its own; each layer covers a different failure mode that the next one would otherwise propagate.

Enhanced OCR runs first, with HDR image processing, handwriting recognition, table detection, and signature and stamp recognition. Machine learning extraction reads clause-level content with models trained per document family, contracts, filings, deeds, and exhibits. Rule-based validation checks the extracted values against jurisdiction, party names, term sheets, and fund mandates, catching the cases where the model is confidently wrong. Human-in-the-loop review handles edge cases that the rules cannot specify: unusual indemnification language and a side letter that contradicts the master agreement. And delivery writes the validated record back into the firm’s DMS (iManage, NetDocuments, SharePoint) or CLM platform, where the lawyer’s normal workflow picks it up.
The reason layering wins is not that any single layer is unusually strong. It is that the layers overlap in their failure modes. ML catches what templates miss. Rules catch what ML hallucinates. Humans catch what rules cannot specify. And the human corrections compound back into the model over time. Single-model stacks have to be perfect on day one and degrade from there. Layered stacks accumulate institutional memory.
Forage AI has built this model across more than 10 million parsed documents in financial, legal, and healthcare workflows. The QA team is sized at roughly three times the industry average relative to delivery. That ratio sounds excessive until the first sanctions motion arrives and counsel has to defend a 94% field-level accuracy claim with no human verification log.
Expert Insight. The human review layer is also where firm-specific institutional memory accumulates. After a year of running a firm’s M&A binder flow, the reviewers have seen the same edge cases hundreds of times: the buyer who always asks for a non-standard MAC, the seller’s counsel who buries the indemnification cap in a schedule. That pattern set trains the next quarter’s model. Pipelines without a human layer never accumulate this asset.
Quick Summary. “Why does the layered architecture beat single-model approaches on legal documents?” Because each layer protects against a different failure mode. ML covers variability, rules cover known constraints, humans cover the long tail, and the loop compounds. A single AI model has to be perfect day one and degrades from there.
The audit trail required for legal work: cite back to the page, not the document
Legal work is judged twice: once when it is filed, and once when something goes wrong. The second judgment is unforgiving. When a state bar inquiry, a sanctions motion, or a regulator’s question arrives, the answer to “where did this number come from?” cannot be “the IDP extracted it.” The answer has to include which document, which page, which bounding box on that page, which extraction model version, which validation rules fired, which human reviewer touched it, what they changed, and when.

This is field-level, cite-back lineage, not document-level audit logs. Most generic IDP products produce the latter and call it an audit trail. They tell you that document X was processed at time Y with confidence Z. They do not tell you which span on which page produced the extracted clause, nor do they retain a tamper-evident history of human corrections. The first time a partner has to defend an extracted value to opposing counsel, the gap shows.
The test is simple. Pick any closed matter from six months ago. Try to reconstruct, in 60 seconds, the source span for the three most decision-relevant extracted values in that matter. If you cannot, the firm does not have an audit trail. It has a logfile. The distinction matters at exactly the worst possible time.
Expert Insight. The single most diagnostic question in any legal-IDP vendor evaluation is “can you walk me through a closed matter from six months ago and show me where each extracted clause came from?” Vendors that pass that test almost always pass the rest of the evaluation. Vendors that pivot to talking about confidence scores are quietly admitting their audit trail is document-level.
Quick Summary. “What audit trail does legal document processing need?” Page-level cite-back. Every extracted value ties to its source span, model version, validation outcome, and human-review history. Document-level logs do not survive a bar inquiry or a sanctions motion.
Where automation belongs in legal work, and where it doesn’t
A clean way to think about scope: automation belongs wherever the work is mechanical extraction, classification, routing, or validation against a known rule. It does not belong in strategic advice, negotiation positioning, opinion work, privileged client communication, or any decision that requires reading the spirit of a contract or the politics of a counterparty.

The high-fit moments across a legal workflow are intake classification (separating contracts from correspondence from exhibits), clause and party extraction (pulling names, dates, jurisdictions, governing law, indemnification language), term-sheet versus draft validation (catching the cases where the negotiated draft diverges from the agreed term sheet), diligence-binder indexing (turning 800 documents into a navigable index in hours, not days), conflict checks across filings, and bill-back coding for matter management. For a deeper treatment of the orchestration around extraction, see our document workflow automation guide.
The low-fit moments are strategic advice, negotiation positioning, privileged client memoranda, witness preparation, settlement and arbitration calls, and any ethical-screen judgment that requires reading the relationship between counsel and client. Assistive AI can support these, surfacing precedent, summarising the matter history, flagging anomalies, but the lawyer stays in the loop, and the automation stays in support. The boundary is the judgment, not the document.
Firms that try to automate the judgment work end up either over-recommending the conservative position (model takes the path of least resistance) or under-flagging the risky one (model penalizes anything novel). Both outcomes show up in malpractice reviews. Counsel staying in the judgment seat is not a brake on automation; it is the design.
Expert Insight. The lifecycle map also helps with change management on the associate floor. Associates resist “the AI is replacing me” framing and accept “the AI is opening the binder and indexing it; you are reading what matters” framing. The map gives partners and ops leads something concrete to point at when they explain scope.
Quick Summary. “Which legal tasks should we automate?” Intake classification, clause and party extraction, validation against known rules, diligence-binder indexing, conflict checks, bill-back coding. Not negotiation, not strategic advice, not privileged opinion work.
The ROI case for the GC and the firm COO
General Counsel and firm COOs do not buy automation on the promise of speed. They buy it on a defensible model of hours returned to higher-value work, error reduction, and cycle-time-driven client retention. At enterprise scale this is where the operational case turns strategic: firms that treat document processing as a competitive advantage redirect partner leverage and associate utilisation toward client-facing work their slower competitors cannot match.
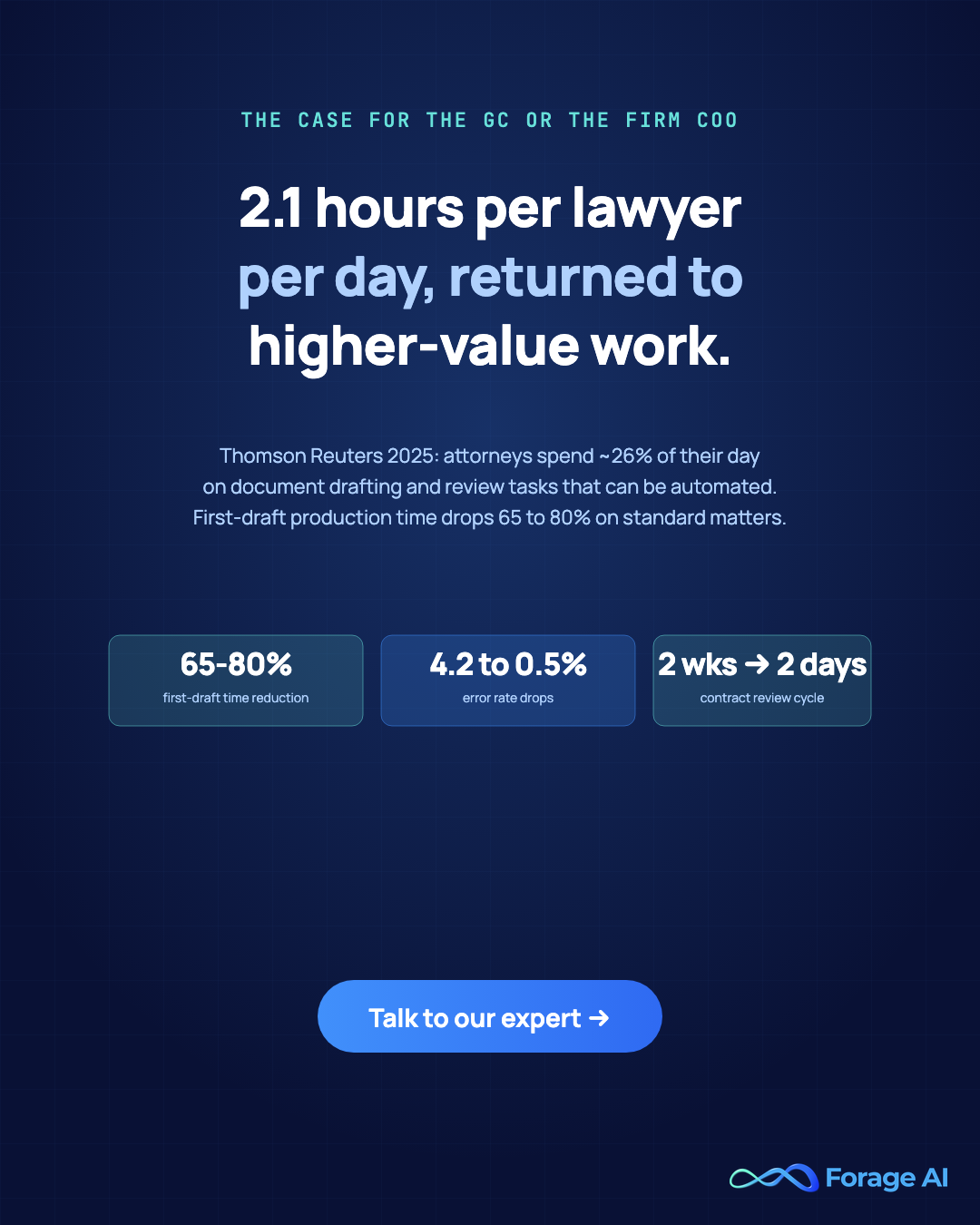
The anchor numbers, all from third-party 2025 research. 2.1 hours per attorney per day on document drafting and review, equivalent to 26% of the working day (Thomson Reuters Legal Technology Survey 2025). 65 to 80% reduction in first-draft production time on standard matter types: contracts, pleadings, client letters, engagement agreements. Error rate drops from 4.2% manual to under 0.5% automated on document assembly (ALM Intelligence). Contract review cycles compress from two weeks to two days on representative deal flow.
A workable model: take the average fully-loaded cost per attorney hour, multiply by the share of attorney time spent on document handling (typically 20 to 30% depending on practice mix), and model the reduction under realistic adoption assumptions. Add the error-reduction line (malpractice premiums, rework cost, client-confidence cost). Subtract the software cost, integration cost, and change-management cost. Discount the first-year ROI by 40 to 50% to absorb the realistic ramp.
Cost is the closing argument in the GC or COO conversation, not the opener. The opener is privilege defensibility, audit-trail granularity, and the cost of doing nothing through the next CAT-volume quarter.
Expert Insight. The number that lands hardest in a partner conversation is billable hours redirected from review to advice. If document handling delays compress associate capacity by even one hour per day per attorney, that is real client-billable time the firm is leaving on the table. Frame the ROI in terms of partner leverage and associate utilisation as much as in terms of error reduction.
Quick Summary. “How do I model the ROI for the GC or COO?” Hours returned (2.1 per attorney per day × the share of doc handling tasks automated), plus error reduction (4.2 to 0.5% on document assembly), plus cycle-time-driven retention. Anchor the closing argument on privilege defensibility, not on speed.
Seven questions to ask any legal IDP partner before procurement
When the field of vendors narrows and the evaluation moves into procurement, these criteria separate partners that survive Legal review from partners that pass on the demo floor.

| Criterion | What to ask | Red flag |
|---|---|---|
| “Generic REST API, you build it.” | Sub-processor list in writing. Where is the model hosted? | “We use industry-leading AI” with no named vendor |
| On-prem or VPC option | Privileged work product never leaves the firm’s perimeter. | “Cloud-only” with no isolation option |
| Cite-back audit trail | Page, span, model version, reviewer. Reconstruct any closed matter in 60 seconds. | Logs only, no chain of custody |
| Legal-format coverage | By document family and by jurisdiction. | Demos a clean NDA, no real-format coverage data |
| Human-in-the-loop QA | Named QA ratio relative to delivery, not “AI-powered QA.” | No human review layer at all |
| DMS / CLM integration | iManage, NetDocuments, SharePoint, Ironclad, Agiloft. | “Generic REST API, you build it” |
| Indemnification on privilege waiver | Who pays if sourcing or processing waives privilege downstream? | Silence, or boilerplate carve-outs |
The criteria are uneven on purpose. Sovereignty and audit trail outweigh integration in importance. A partner that integrates fast but fails the privilege review will cost the firm more in malpractice exposure than any integration ever saved.
Expert Insight. The most reliable closing question in a legal-IDP evaluation is “will your team sit in the room with our Legal lead and walk through the architecture together?” Vendors that say yes almost always pass the privilege review. Vendors that route the question to a sales engineer who promises a follow-up rarely close the deal.
Quick Summary. “What should I score partners on?” Sovereignty (no third-party LLM, on-prem / VPC), audit trail granularity, legal-format coverage, QA model, integration, partnership shape, and privilege-waiver indemnification. Sovereignty and audit trail weigh heaviest because they decide whether the deal survives the firm’s Legal review.
How Forage AI approaches legal document extraction
Forage AI is not a CLM, not a legal-research platform, and not a contract-drafting tool. We do not give legal advice, adjudicate clauses, or replace the firm’s case management system. We act as the acquisition layer for the document data that flows into those systems: the extraction, structuring, and quality assurance work that must happen between the document’s arrival and the matter being workable.
Our approach combines multi-method extraction (XPath plus NLP plus custom-trained ML models running in parallel, so accuracy holds when one method degrades), a 200% QA model with a QA team roughly three times the industry average size, and a delivery model where data stays inside our perimeter and yours. We have parsed more than 10 million documents across financial, legal, and healthcare workflows. Legal sits at the intersection of all three, which is why the same patterns that hold up for KYC, contract data extraction, and clinical document workflows hold up for case files.
Sovereign by design means client data never trains third-party models, never gets resold, never aggregates across clients. SOC 2, GDPR, and HIPAA-compliant workflows are not a configuration option; they are how the service is built. On-premises deployment is available when the document corpus must remain within the firm’s perimeter. The signal phrase is the one Legal needs to hear: your privileged content stays in our perimeter. The contract backs the marketing.
Onboarding typically takes one to two weeks per document family. The team is dedicated, not a ticket queue. The acquisition layer is yours. The team operating it is ours.
Expert Insight. The most common reason firms move from a generic IDP product to a Forage engagement is not accuracy. It is document-family expansion velocity. The firm’s queue keeps absorbing new jurisdictions, new regulators, new post-M&A document families, and the existing tool cannot keep up. The dedicated-team model exists for exactly that pattern.
Quick Summary. “What does Forage AI do for legal?” Run the extraction, structuring, and QA layer that turns legal documents into validated structured records inside the firm’s DMS, CLM, or matter system. We do not give legal advice. We make the document data trustworthy, auditable, and sovereign.
Frequently Asked Questions
How accurate is legal document processing today?
Honest accuracy claims are clause-level, by document family, by jurisdiction. A reasonable expectation is 95 to 97% accuracy on standard contracts and 85 to 92% on multi-party agreements, regulatory filings, and scanned exhibits, with the gap closed to 99% plus through human-in-the-loop review on the exceptions that fall below a confidence threshold. Document-level accuracy numbers in vendor decks usually overstate what survives a partner review.
Does using AI in document review waive the attorney-client privilege?
Yes, if the AI is a public third-party tool. In February 2026, US District Judge Rakoff confirmed that submitting privileged content to public GenAI tools like ChatGPT, Claude, or Gemini waives both attorney-client privilege and work-product protection. A sovereign IDP that processes inside the firm’s perimeter, with no third-party LLM in the data path, does not implicate the same disclosure analysis. This article is general guidance, not legal advice; consult qualified counsel for your specific situation.
What is the difference between IDP and a CLM?
A CLM stores, manages, and tracks contracts after they exist as structured records. IDP is the layer that turns inbound, unstructured legal documents (PDFs, scans, mixed-format diligence binders) into the structured records a CLM, DMS, or matter system can consume. The two are complementary; IDP feeds the CLM.
Can we automate contract drafting?
Partially. Standard-matter first-draft production is well-served by automation (65 to 80% time reduction on engagement agreements, NDAs, and similar). Negotiated draft work, opinion letters, and bespoke transaction documents stay with counsel. The automation belongs around the drafting, not in it.
How long does it take to deploy legal document processing?
For an extraction layer on a single document family (say, NDA extraction or county-recorder deed extraction), one to two weeks from brief to live with a competent partner. For a full multi-family rollout integrated with the firm’s DMS or CLM, three to six months is realistic. Most of the timeline is integration, change management on the associate floor, and document-family coverage expansion.
Related Articles
- AI-Powered Intelligent Document Processing Solutions 2025, broader overview of how AI-powered IDP works across regulated industries.
- Invoice Automation: How Modern AP Teams Are Eliminating Manual Document Processing, the AP-side companion: how the same IDP-plus-human-review architecture handles invoice capture, validation, and ERP write-back.
Sources
- Thomson Reuters, 2025. Legal Technology Survey. Attorneys spend ~2.1 hours per day, 26% of the working day, on document tasks.
- ALM Intelligence, 2024. Error rate in manually drafted legal documents: 4.2%. Reduced under 0.5% with automated assembly.
- US District Court, S.D.N.Y., February 2026 (Judge Rakoff). Sharing privileged content with a public GenAI tool waives attorney-client privilege and work-product protection.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




