

The compute-unit bill comes in and it does not match the estimate. You budgeted for a few hundred dollars of scraping that month, and the invoice reads like someone left a browser farm running over a long weekend. Then a marketplace Actor you depend on flips to “under maintenance” at 2 a.m. because a target site shipped a layout change, and your morning pipeline run returns half-empty datasets nobody notices until a downstream report comes back wrong.
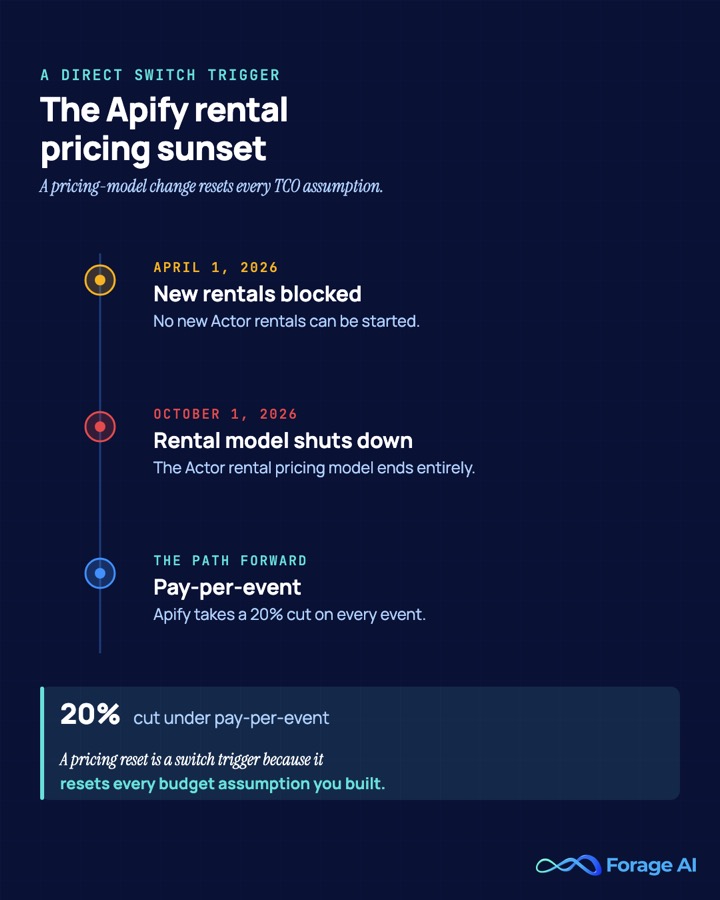
If you run web data for a living, you have lived some version of that week. And in 2026 it comes with a deadline attached. Apify is sunsetting its Actor rental pricing on October 1, 2026, with new rentals blocked since April 1, pushing teams onto pay-per-event where Apify takes a 20% cut. A pricing-model change is the kind of thing that forces a decision you have been putting off.
So this is not another roundup that hands you a list and wishes you luck. The trap in those lists is that they answer the wrong question. The question is not which tool to swap in. It is which of three models your team should be running at all: self-serve, an API, or fully managed. We will name the recurring reasons teams leave, set up the model that decides everything, then work through ten real alternatives, each mapped to the specific Apify weakness it answers.
Quick Digest
- Apify is good, which is the point: It rates well (G2 4.7/415, Capterra 4.8, Trustpilot 4.8). Teams rarely leave on quality. They leave on cost predictability, maintenance load, and a pricing-model change with a date on it.
- Why teams actually leave: Unpredictable compute-unit bills (G2’s “Pricing Issues” and “Expensive” tags are the two loudest), the Actor rental sunset on October 1, 2026, Actor fragility, scale ceilings, and anti-bot gaps on hard targets.
- The real divide: Self-serve, API, or managed. The only question that matters is who owns breakage, QA, maintenance, and compliance when something breaks at 2 a.m.
- The ten alternatives, by category: Managed (PromptCloud, Grepsr), scraping and data APIs (Bright Data, Zyte, Oxylabs, ScraperAPI, ScrapingBee, Firecrawl), and self-serve or open-source (Octoparse, Scrapy/Crawlee).
- How to choose: Start from your binding constraint. When high scale, high customization, and high reliability all bind at once, no self-serve tool fits and a managed provider does.
- Migration is phased, not a flip: Export datasets, map Actors to equivalents, run a parallel test, cut over, re-point consumers, keep a rollback ready.
Should you really switch from Apify?
Be fair to Apify before you leave it. The headline scores are high: G2 4.7 across 415 reviews, Capterra 4.8, Trustpilot 4.8 (accessed June 18, 2026). The product works. People who use it daily mostly like it. The reason teams leave is almost never quality. It is the bill, the maintenance treadmill, and a pricing model that is changing under them.
That distinction matters, because the worst migration is the one you did not need. We have watched teams burn a quarter moving off a platform when the real culprit was an oversized RAM allocation or one abandoned community Actor. Diagnose first, switch second. If a single inefficient Actor is eating the budget, fix it in place. If the pain is structural, the list below is the spine the rest of this guide maps against.
Here is why teams actually leave, sourced to recurring review themes rather than vibes.
| The recurring weakness | What the reviews and docs show | |
|---|---|---|
| W1 | Pricing unpredictability | On G2, the two most-cited negative tags across 415 reviews are “Pricing Issues” (88 mentions) and “Expensive” (87). Reviewers say it is hard to know the cost until after building a proof of concept; layered compute units plus proxy GB plus per-Actor fees defeat a single forecast. |
| W2 | The Actor rental sunset | Apify retires rental pricing on October 1, 2026, with new rental Actors blocked since April 1, 2026. Unmigrated Actors auto-move to pay-per-usage, and on pay-per-event Apify takes 20%. Pricing churn on someone else’s calendar is itself a switch trigger. |
| W3 | Actor fragility and maintenance | Apify’s own “under maintenance” flag fires when a target site changes layout and an Actor fails quality checks. A Capterra reviewer calls Actor Store quality “wildly inconsistent.” You still inherit the breakage. |
| W4 | Scale ceiling and caps | Reviewers report hard monthly compute caps with no graceful overage handling, and a console that slows with dozens of Actors. The platform is built around many small Actors, not one large guaranteed feed. |
| W5 | Anti-bot on hard targets | On aggressively defended sites, results degrade and costs climb. Reviewers note Actor parameters and item limits are not always respected, a reliability tell on harder targets. |
| W6 | Support and billing friction | Isolated reports of unexpected charges and thin support on billing disputes tied to Actor runs. When the bill surprises you, the recourse path is narrow. |
| W7 | You still own the pipeline | The umbrella weakness. Apify gives you capability (Actors, infra, a marketplace) but you still own cost control, breakage, QA, scale planning, and recourse. It is a platform, not an outcome. |
Every alternative below maps its “better than Apify when” line to one of these seven. For the economics underneath the maintenance line, the build vs buy your web data extraction breakdown runs the full model.

Quick Summary
Q: Should you really switch from Apify, or fix what you have?
A: Apify rates well (G2 4.7/415, Capterra 4.8, Trustpilot 4.8), so quality is rarely the reason to leave. Switch only when the pain is structural: pricing unpredictability, the rental sunset, Actor fragility, a scale ceiling, anti-bot gaps, or thin billing support. If it is one inefficient Actor, fix that in place first.
Expert Insights
The review data backs up the audit-first instinct. Across 415 Apify reviews on a major software-review site, “Pricing Issues” was tagged 88 times and “Expensive” 87 times (accessed June 18, 2026). What we read in that pattern is that cost surprises, not capability gaps, drive most of the dissatisfaction. Surprises usually have a root cause you can find, which is the whole argument for opening the bill before opening a vendor shortlist.
The real divide: self-serve vs managed
Stop comparing tool to tool. A feature checklist (proxies, JS rendering, CAPTCHA handling) hides the question that actually keeps you up: who owns what when something breaks at 2 a.m. That single question splits the entire market into three models.
A self-serve / actor platform, Apify’s native category, hands you the tools and leaves you to own everything: building scrapers, handling failures, maintaining them as sites change, running QA. A scraping / data API moves one layer up. The vendor handles egress and unblocking, the proxy rotation and the anti-bot evasion, while you still write parsers and own data quality. A managed / data-as-outcome provider owns the whole chain: source discovery, extraction, QA, maintenance, and delivery. You brief requirements; you receive structured data on a schema.
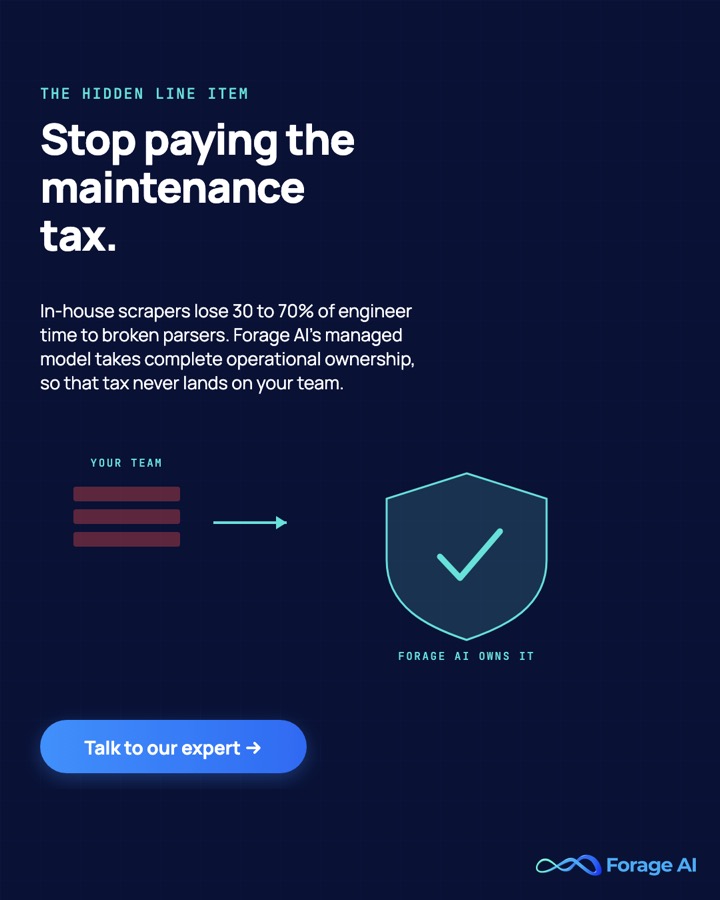
What each leaves on your plate is the real differentiator. Self-serve leaves all of it. An API leaves parsing and QA. Managed leaves the requirements definition and nothing operational. That is the maintenance tax made visible, and it is the line nobody puts on a pricing page.
The numbers behind that tax are specific. In-house engineers spend roughly 30% to 70% of their time fixing broken parsers rather than building features, per an industry maintenance note. A three-person in-house scraping team costs $80,000 to $150,000 annually in salaries, infrastructure, and maintenance, and the three-year TCO climbs from about $250K in year one to about $375K by year three as maintenance and headcount compound. The headline rate is the number that changes least over three years. The maintenance line is the one that compounds.
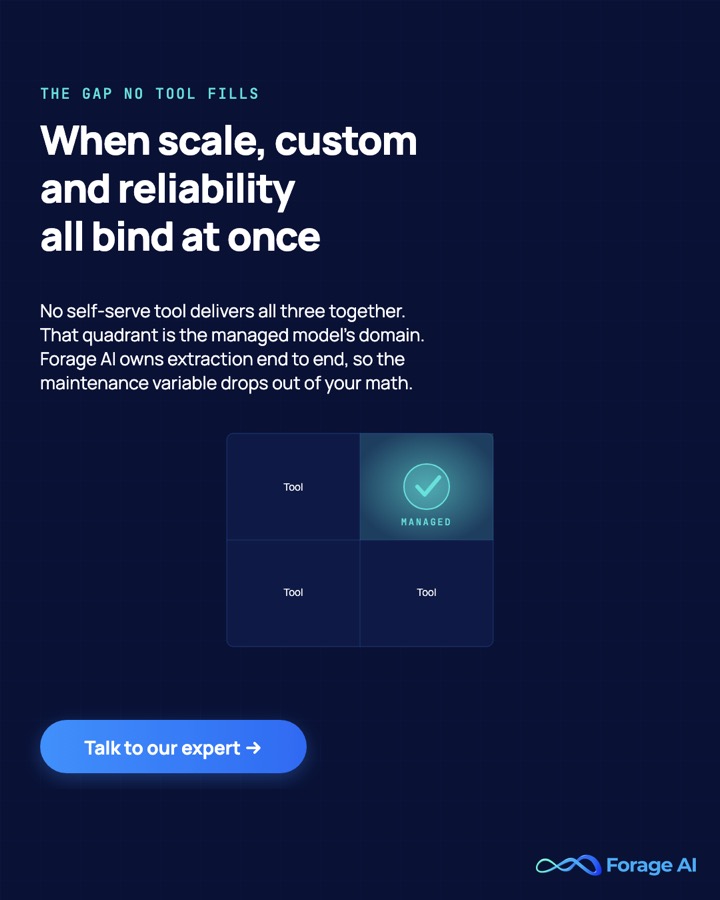
There is a quadrant that decides the whole guide.
> No self-serve tool delivers high scale, high customization, and high reliability at once. That combination is the managed model’s domain, not a tool feature. A tool optimizes for one or two. The third always gives.
For the definitional split underneath this, see managed vs automated/self-serve scraping.


Quick Summary
Q: What is the difference between self-serve, API, and managed web scraping?
A: Self-serve means you own everything (build, fix, maintain, QA). An API means the vendor handles unblocking and egress while you still build parsers and own data quality. Managed means the provider owns the entire chain from discovery to delivery. The maintenance tax (30-70% of engineer time on broken parsers) lands fully on self-serve, partly on API, and not at all on managed.
Expert Insights
The direction of travel makes the managed model’s value clearer the longer you look. As Fabien Vauchelles, the web-scraping expert who created Scrapoxy, put it: “The barrier to entry is getting higher and higher every year. I think we will move toward a closed internet in the coming years.” As access hardens, the proxy and anti-bot economics that already reward scale tilt further toward providers who absorb that infrastructure, and away from buyers renting it in fragments.
Forage AI vs Apify: a side-by-side
Forage AI is the managed counterpoint to Apify, so it earns a direct comparison rather than a row in the roster below. The two are not the same kind of thing. Apify is a self-serve actor platform: you operate it. Forage AI is a fully managed data provider: it owns the pipeline and delivers the data. The table compares them on the dimensions a pipeline owner actually weighs.
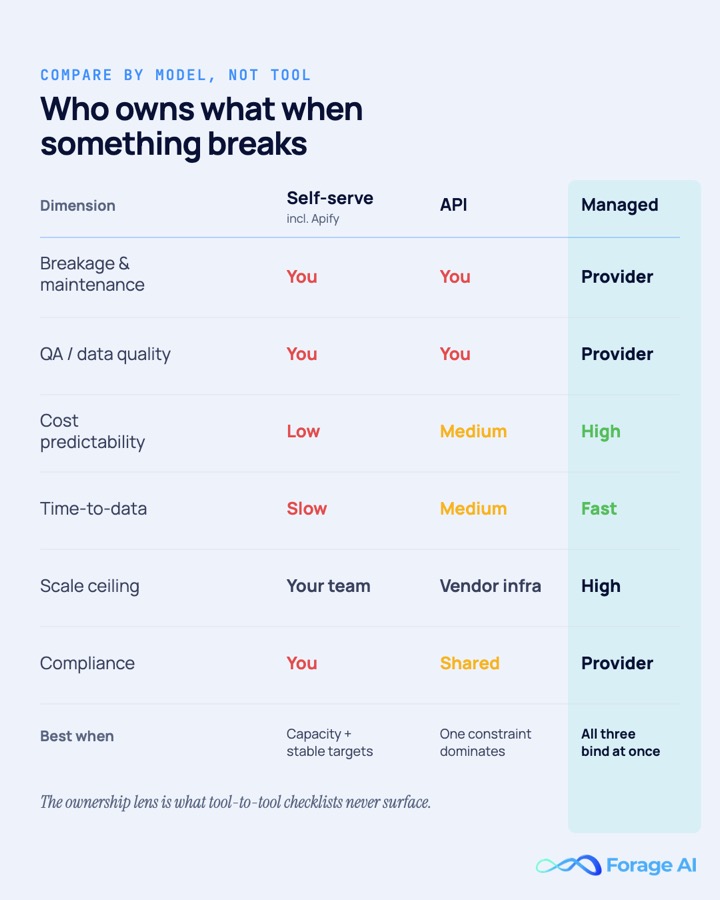
| Dimension | Apify (self-serve actor platform) | Forage AI (managed data-as-outcome) |
|---|---|---|
| Who owns breakage & maintenance | You | Provider |
| Who owns QA / data quality | You | Provider (automated plus human QA) |
| Cost model | Usage-metered (compute units + proxy + fees), low predictability | Custom contract, high predictability |
| Time-to-data | You build and maintain | You hand off requirements, provider delivers |
| Scale ceiling | Your engineering capacity and plan caps | Provider-managed, high “ |
| Compliance / data ownership | You own compliance posture; you operate everything | Client owns all delivered data; provider runs everything, no reselling |
Source: composite from Apify pricing and docs (2026) and Forage company context (2026).
Read across the rows and the trade is plain. Apify hands you maximum control and the maximum burden. Forage trades day-to-day control for end-to-end ownership: source discovery, extraction, cleaning, multi-layer QA, maintenance, and delivery all sit with the provider. The mechanism most teams underestimate is QA. Forage runs a QA team sized well above the typical delivery ratio and applies both automated and human review before data ships. “
This is not the right answer for everyone, and saying so is the honest move. Forage is the wrong fit for a developer who wants a $49 API key tonight, a one-off scrape, or hands-on control of the code. It is a partnership and contract model, not pay-as-you-go. It earns its place when data is the product, when scale and customization and reliability all bind at once, and when the team does not want to own extraction infrastructure. That is the rare quadrant no self-serve tool occupies. The deeper case for why the maintenance burden disappears on this model is in the hidden maintenance cost of running your own scrapers.
Quick Summary
Q: How is Forage AI different from Apify?
A: Apify is a self-serve actor platform you operate; you own breakage, QA, maintenance, and cost control. Forage AI is a fully managed provider that owns the full pipeline (discovery, extraction, QA, maintenance, delivery) and hands you clean data on a schema. Choose Forage when data is the product and scale, customization, and reliability all matter at once; stay self-serve when you want hands-on control or pay-as-you-go.
Expert Insights
The structural backdrop is why “who owns QA and breakage” is the deciding question, not a feature you tick off. Automated bots accounted for 53% of all web traffic in 2025, up from 51% in 2024, per the 2026 Bad Bot Report. As more of the web becomes automated traffic, defenses harden and beating them stops being a one-time build. As Iain Lennon, Chief Product Officer at a managed data provider, observed: “Anti-bot solutions will continue to increase the rate of changes to their configurations. Software automation to respond and handle these will increasingly become vital.”
Ten other Apify alternatives, in depth
These ten span the three models, grouped by category so you can read them through the framework rather than as a leaderboard. Forage AI is the managed pick, covered in the side-by-side above, so it does not repeat here. Each entry carries the same compact table, a real review signal, and the specific Apify weakness it answers. The right one depends entirely on which constraint is binding for you.
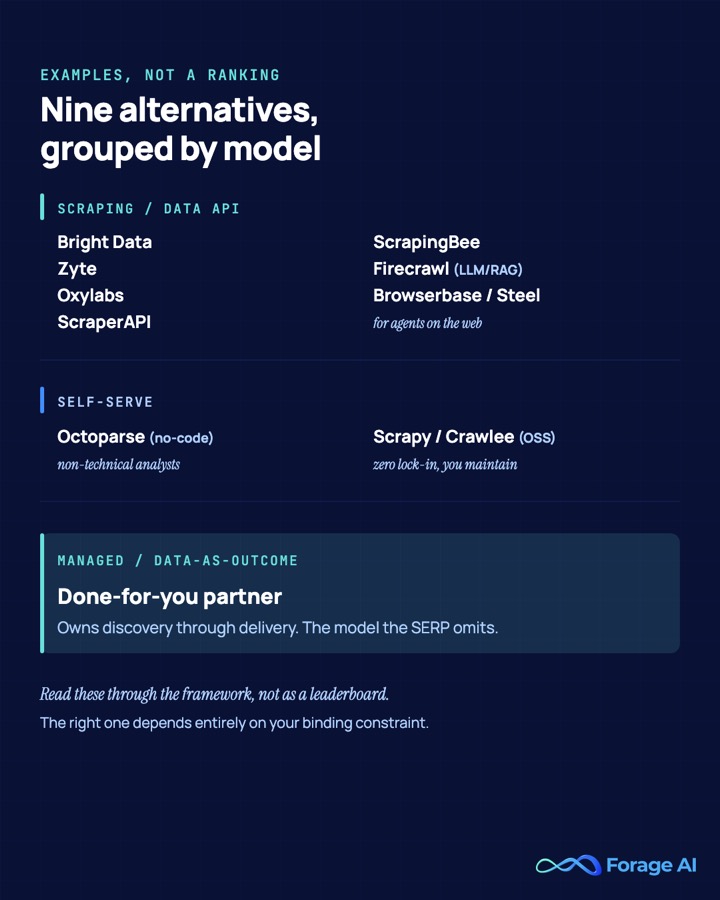
Best managed / done-for-you alternatives
If your binding constraint is W7 (you still own the pipeline) or the W3 maintenance treadmill, the managed model is the answer, and Forage AI in the side-by-side above is the deepest treatment of it. The two providers below are the closest reviewed comparators in the same data-as-outcome category.
PromptCloud
| Best for | Hands-off recurring enterprise feeds, teams without dedicated scraping engineers |
|---|---|
| Service model | Fully managed Data-as-a-Service (since 2009) |
| Pricing model | Custom managed, roughly $250 to $5,000+/mo; directory plans from ~$49/site/mo with record caps |
| Reviews | G2 4.6/5 (16) · Capterra 4.2/5 (14), accessed June 18, 2026 |
| Standout strength | The managed model removes complexity end to end; data arrives structured |
| Watch-out | High for small teams; thin community signal |
| Better than Apify when | W3 + W7: you do not want to debug broken Actors at 2 a.m. |
PromptCloud is the closest reviewed comparator to a fully managed provider. You specify the data, they build and maintain custom crawlers and deliver clean structured data on a schedule. The single most common positive theme in reviews is the hands-off model itself. One reviewer put it plainly: “The fully managed service model takes all the complexities away… data well structured and needed no further processing.” Responsive support shows up again and again as the second praise point.
Who it is for: enterprise teams that want recurring feeds without standing up a scraping function. The honest watch-out: a reviewer notes that “for smaller companies, price is on a higher side,” and there is almost no Reddit or community presence, so unfiltered peer signal is thin. You also will not find a public price card, which makes comparison-shopping a sales conversation.
Against Apify specifically, PromptCloud answers W3 and W7 directly. The Actor fragility that puts maintenance on your engineers, and the umbrella problem that you still own the pipeline, both disappear when the provider runs everything. You trade self-serve immediacy for never touching breakage again.
Grepsr
| Best for | Data-driven teams wanting accurate, ready-to-use datasets at scale |
|---|---|
| Service model | Managed web-data service with a platform layer |
| Pricing model | Starter Pack from $350 for one-time projects; recurring is custom-quoted |
| Reviews | Capterra 4.7/5 (~81), accessed June 18, 2026 |
| Standout strength | Data quality plus a managed-delivery model with a stronger review base than most managed peers |
| Watch-out | Opaque recurring pricing; no public list |
| Better than Apify when | W7 + W4: you need delivered, QA’d datasets at scale, not Actors you operate and cap-manage |
Grepsr pairs a managed service with a platform layer, and it carries the strongest managed-service review base in this roster: Capterra 4.7/5 across roughly 81 reviews. Users consistently praise data quality and the managed approach, with ready-to-use datasets cited across e-commerce, AI and ML, consulting, healthcare, and finance. For a managed provider, that volume of reviews is a real signal rather than a handful of testimonials.
Who it is for: teams that want accurate, scalable, ready-to-use datasets without running pipelines themselves. The honest watch-out: recurring pricing is custom and opaque, with no public list, so you cannot comparison-shop without a sales call. The $350 Starter Pack lowers the barrier for a one-time project, but a recurring engagement is a quote.
Against Apify, Grepsr answers W7 and the W4 scale ceiling. Where Apify is built around many small Actors that you operate and cap-manage, Grepsr delivers QA’d datasets at scale as an outcome. You stop managing compute caps and start receiving data.
Best scraping and data APIs
These answer W5 (anti-bot on hard targets) and W1 (cleaner billing than layered compute units), but they leave parsing and QA with you, so they only partly address W7. This is the right category when one constraint dominates and you have the engineering capacity to own the parsers.
Bright Data
| Best for | High-scale, hard-target unblocking; compliance-sensitive enterprise |
|---|---|
| Service model | Proxy network + Web Scraper APIs + ready datasets |
| Pricing model | PAYG plus monthly plans; premium-priced (confirm current tiers on pricing page) |
| Reviews | G2 4.6/5 (284) · Capterra 4.5/5 (~15), accessed June 18, 2026 |
| Standout strength | Proxy IP quality and the strongest compliance posture in the roster |
| Watch-out | Premium price; complaints of being charged for results not returned |
| Better than Apify when | W5: the binding constraint is unblocking hard, defended targets at scale |
Bright Data is the enterprise default for the proxy and infrastructure layer, with a deep residential network plus scraper APIs and ready datasets. The praise is specific: “the best residential proxy provider, high-quality IPs that don’t get flagged as proxies, strong uptime,” with a much lower error rate than alternatives on hard targets. With 284 G2 reviews at 4.6, it has the largest verified review base among the API players here.
Who it is for: teams unblocking aggressively defended sites at scale, especially where compliance posture matters. The honest watch-out: reviewers report performance degrading over time and a higher error rate at points, plus being charged for results they did not receive back, and a steep learning curve. You also still build and host the scrapers; Bright Data handles egress, not your pipeline.
Against Apify, Bright Data answers W5. Apify’s reliability is target-dependent and degrades on hard sites; Bright Data’s proxy depth is the binding advantage exactly there. If unblocking is your constraint and you have parsers already, this is the trade.
Zyte
| Best for | Scrapy shops; teams wanting a graduation path from API to managed feeds |
|---|---|
| Service model | Spans self-serve API (Zyte API), hosted spiders (Scrapy Cloud), and managed feeds (Zyte Data) |
| Pricing model | Zyte API PAYG (pay for successful requests); Zyte Data Standard $500/mo, Custom $1,000/mo + ~$100 setup |
| Reviews | G2 and Capterra profiles exist; modest base “ |
| Standout strength | Spans API to fully managed in one vendor |
| Watch-out | No PAYG spend cap (bill-spike risk); managed tier narrower than a full partner |
| Better than Apify when | W5 + partial W7: you want automatic unblocking plus an on-ramp to managed delivery |
Zyte is the one mainstream player that crosses from API into managed feeds, which makes it the natural bridge in this list. It runs three products: Zyte API (PAYG, pay for successful requests), Scrapy Cloud (hosted spiders), and Zyte Data (managed feeds at $500 to $1,000/mo). Reviewers praise ease of use, reliable performance, strong support, and clean Scrapy integration, which makes it intuitive for Python teams that do not want to run infrastructure.
Who it is for: Scrapy shops, and teams that want to start on an API and graduate to managed delivery without switching vendors. The honest watch-out: one Capterra reviewer reported waking up to a bill 40x higher than expected because PAYG has no spending cap, and the pricing structure gets complex at scale. The managed tier is also narrower than a full done-for-you partner.
Against Apify, Zyte answers W5 and part of W7. You get automatic unblocking like the other APIs, but unlike them you also get an in-vendor path toward managed delivery, so as the maintenance burden grows you can move up a tier rather than re-platform.
Oxylabs
| Best for | Reliability-first, proxy-dependent scraping at scale with hands-on support |
|---|---|
| Service model | Premium proxies + Web Scraper API |
| Pricing model | Web Scraper API from ~$49/mo; proxy units from $0.59 (datacenter) up to ~$5.64 (Web Unblocker); enterprise custom |
| Reviews | G2 4.5/5 (362) · Trustpilot 4.1/5 (711), accessed June 18, 2026 |
| Standout strength | High success rate plus a named, reachable account manager |
| Watch-out | High pricing; unused credits expire; steep learning curve |
| Better than Apify when | W5 + W6: you need top-tier success rates and real account support |
Oxylabs sits at the premium end of the proxy and scraper-API category, and it has the deepest review base in this roster (362 on G2, 711 on Trustpilot). The recurring praise is reliability plus support: “reliable proxies, easy setup… excellent support with a dedicated RM always reachable,” with high success rates on large-scale e-commerce extraction. For teams where a failed run is expensive, that combination is the draw.
Who it is for: reliability-first teams running proxy-dependent extraction at scale that also want hands-on account support. The honest watch-out: high pricing is the single most-cited concern, unused credits expire (which surprises PAYG users), and there is a learning curve. It is infrastructure-first, so you still parse and QA.
Against Apify, Oxylabs answers W5 and W6. The success rate beats Apify’s target-dependent reliability on hard sites, and the dedicated account manager directly addresses the thin billing-dispute support that Apify reviewers flag. You are buying both unblocking and a human to call.
ScraperAPI
| Best for | Teams that already have parsers and just need reliable egress IPs plus rendering |
|---|---|
| Service model | Proxy + JS-rendering API |
| Pricing model | Hobby $49/mo, up to Advanced $1,975/mo; free tier plus trial; credit-based |
| Reviews | G2 4.4/5 (~16) · Trustpilot 4.5/5 (~93% five-star), accessed June 18, 2026 |
| Standout strength | Simple, reliable egress; >99% success in an independent benchmark |
| Watch-out | No credit rollover; premium-credit math complicates budgeting |
| Better than Apify when | W1 + W5: you want one clean proxy/rendering endpoint instead of layered CU billing |
ScraperAPI is the no-frills proxy-and-rendering endpoint for teams that already own their parsers. Reviewers like that it “handles technical challenges like proxies and CAPTCHAs seamlessly,” and an independent benchmark showed it hitting over 99% success and the fastest among tested competitors on a hard target. If you only need reliable IPs and rendering bolted onto an existing pipeline, that focus is the appeal.
Who it is for: teams with working parsers that need dependable egress and rendering, nothing more. The honest watch-out: there is no credit rollover, plans carry monthly commitments, and premium-credit costs get confusing, especially once premium parameters are enabled, which makes budgeting harder than the headline tier suggests.
Against Apify, ScraperAPI answers W1 and W5. Instead of juggling Actors plus separate proxy and storage line items, you get one endpoint with one credit meter, which is a cleaner billing story than Apify’s layered compute units, and the success rate handles harder targets.
ScrapingBee
| Best for | Small and mid dev teams wanting the easiest API integration with good support |
|---|---|
| Service model | Developer-friendly proxy + JS-rendering API |
| Pricing model | From $49/mo; credits and concurrency scale with tier |
| Reviews | G2 4.8/5 (~20) · Capterra 4.9/5 (~137), accessed June 18, 2026 |
| Standout strength | Dead-simple integration plus proactive support (refunds without being asked) |
| Watch-out | Pricing feels high on lower tiers; stealth proxies burn credits fast |
| Better than Apify when | W1 + W6: you want simple, transparent billing and genuinely responsive support |
ScrapingBee carries the highest review scores in this roster (G2 4.8, Capterra 4.9 across ~137 reviews), and the praise is about ease and service. Reviewers call it “dead simple to integrate, handles JavaScript-heavy and anti-bot pages surprisingly well,” and note that support reportedly issues refunds without being asked and follows up with help. For a small team, that low-friction experience is the whole pitch.
Who it is for: small and mid-sized developer teams that want the easiest integration and responsive support over maximum scale. The honest watch-out: pricing feels high on the lower tiers, stealth-proxy levels burn credits fast, and concurrency caps will force an upgrade as you grow. It is not built for the hardest anti-bot targets at high volume.
Against Apify, ScrapingBee answers W1 and W6, which happen to be two of Apify’s softest review areas. The billing is simpler and more transparent than layered compute units, and the support culture (proactive refunds) is the opposite of the thin billing-dispute recourse Apify reviewers describe.
Firecrawl
| Best for | AI and LLM pipelines; RAG ingestion needing clean, token-efficient output |
|---|---|
| Service model | API returning clean markdown/JSON; open-source core |
| Pricing model | Free 1,000 pages/mo; Hobby $16/mo (3,000 credits), then higher tiers; credit-based |
| Reviews | No major G2/Capterra presence; 131k+ GitHub stars as the popularity proxy |
| Standout strength | Clean LLM-ready output (markdown uses ~67% fewer tokens than raw HTML) |
| Watch-out | “1 credit/page” is misleading; real costs hit 5-9x with JSON and Enhanced mode |
| Better than Apify when | W1-adjacent + use-case fit: the job is feeding an LLM, not operating a fleet of Actors |
Firecrawl is the AI-pipeline specialist, returning clean markdown and JSON built for LLM ingestion. It sits in the newer wave of AI-powered web scraping tools aimed at LLM and RAG workflows rather than classic fleet-style scraping. It has no formal G2 or Capterra footprint, so do not cite a star rating that does not exist; the honest signal is community traction, and 131k+ GitHub stars is a strong one. Its differentiator is token efficiency: markdown output uses roughly 67% fewer tokens than raw HTML, with native LangChain and LlamaIndex integrations.
Who it is for: AI and LLM teams doing RAG ingestion that need clean, token-efficient output rather than deep typed-column extraction. The honest watch-out: the “1 credit per page” headline is misleading, with real costs hitting 5 to 9x once JSON and Enhanced mode are enabled, there is no pure PAYG, credits do not roll over, and early-2026 GitHub issues report hanging crawls and 429s. It also has no formal review track record to lean on.
Against Apify, Firecrawl is a use-case answer rather than a head-to-head. If the job is feeding an LLM clean markdown, operating a fleet of Actors is the wrong shape entirely, though watch Firecrawl’s own credit-multiplier opacity, which echoes the W1 unpredictability you are trying to escape.
Best self-serve and open-source
These answer W2 (escape Actor-marketplace pricing churn) and W1 (own your unit economics), but you inherit maintenance, the very W3 burden, so they are honest trade-offs rather than clean wins.
Octoparse
| Best for | Non-technical analysts on stable, long-tail sites |
|---|---|
| Service model | No-code visual scraper (desktop plus cloud) with a template library |
| Pricing model | Free tier; Standard ~$83-$119/mo; Professional ~$299/mo; add-ons for proxies and CAPTCHA |
| Reviews | G2 4.7/5 · Capterra 4.7/5 (~106) · Trustpilot 3.7-3.9/5 (~91), accessed June 18, 2026 |
| Standout strength | No-code ease plus a large template library |
| Watch-out | Add-ons inflate the bill 40-60%; the G2/Capterra-vs-Trustpilot gap reflects incentivized reviews |
| Better than Apify when | W3 for non-coders: a non-developer wants to self-build without writing Actor code |
Octoparse is the no-code default, a point-and-click desktop and cloud scraper with a deep template library. Reviewers praise “ease of use for web scraping, a visual interface that makes complex extraction straightforward even for non-coders,” and pre-built templates that cut setup time. The review picture comes with a caveat worth reading carefully: G2 and Capterra both sit at 4.7, but Trustpilot lands at 3.7 to 3.9, and that gap is partly driven by documented solicitation of paid five-star reviews. Trust the lower, unfiltered Trustpilot score and its billing and refund complaints.
Who it is for: non-technical analysts working stable, long-tail sites where layouts rarely change. The honest watch-out: it struggles with complex or dynamic workflows, depends on the desktop app, inflates the bill 40 to 60% through proxy and CAPTCHA add-ons, and has a short 5-day refund window.
Against Apify, Octoparse answers W3 for non-coders. A non-developer can build and own a scraper visually without writing or maintaining Actor code, though they still inherit breakage when a target site changes. It moves the work off code, not off maintenance entirely.
Scrapy / Crawlee
| Best for | Engineering teams wanting zero lock-in and full control of unit economics |
|---|---|
| Service model | Open-source frameworks; you host and maintain |
| Pricing model | Free (infrastructure costs only) |
| Reviews | No G2/Capterra rating (open-source); Scrapy ~62k GitHub stars, Crawlee ~12k (JS) / ~9k (Python) |
| Standout strength | Total control plus zero licensing lock-in; large mature community |
| Watch-out | You absorb the full maintenance tax and the engineering headcount it implies |
| Better than Apify when | W1 + W2: you want fully owned economics with no marketplace pricing churn |
Scrapy and Crawlee are the open-source route, for teams that want to own everything and pay only for infrastructure. Scrapy is the most widely deployed structured-scraping framework (around 62k GitHub stars, mature since 2008); Crawlee adds autoscaling, headless browsing, and JS rendering out of the box. One detail matters for the leave-Apify decision: Crawlee is built and maintained by Apify, so if Crawlee is your draw, leaving the ecosystem is less clear-cut than it looks. The community case is total control and owned unit economics with no lock-in.
Who it is for: engineering teams that want zero lock-in and direct control of their unit economics. The honest watch-out: you own all maintenance, anti-bot escalation, and proxy tuning, which is the full W3 burden plus the headcount it implies. Teams without dev capacity should not pick this; you inherit the entire maintenance tax (the 30-70% engineer-time figure from earlier).
Against Apify, Scrapy and Crawlee answer W1 and W2. You get fully owned economics with no marketplace pricing churn, no rental sunset, and no 20% pay-per-event fee, at the explicit cost of owning all maintenance yourself. It is the cleanest escape from pricing-model risk and the heaviest in operational load.
All ten alternatives at a glance
Here is the whole field on one screen, so you can compare the alternatives side by side before you read the framework below. Match the row to your binding constraint, then go back to that provider’s deep dive.
| Provider | Model | Pricing model | Rating | Better than Apify when |
|---|---|---|---|---|
| Forage AI | Managed (data-as-outcome) | Custom contract | Managed engagement | W7 + W1 + W3: you want delivered data, not a pipeline to run, QA, and maintain |
| PromptCloud | Managed | Managed subscription | G2 4.6 (16) | W3 + W7: hands-off managed feeds instead of fixing Actors |
| Grepsr | Managed | Managed plans | Capterra 4.7 (~81) | W7 + W4: managed delivery that scales past DIY caps |
| Bright Data | Scraping/data API + proxy | Usage + subscription | G2 4.6 (284) | W5: the toughest anti-bot targets and largest scale |
| Zyte | API to managed feeds | Per-success / managed | Solid but smaller review base | W5: high success rate on hard, protected targets |
| Oxylabs | API + proxy | Usage + subscription | G2 4.5 (362) | W5 + W6: enterprise anti-bot depth plus support |
| ScraperAPI | Scraping API | Credit tiers | G2 4.4 (~16) | W1 + W5: predictable pricing with basic unblocking |
| ScrapingBee | Scraping API | Credit tiers | G2 4.8 (20) / Capterra 4.9 | W1 + W6: simple, forecastable pricing and good support |
| Firecrawl | API (LLM/RAG-ready) | Usage / credits | No major reviews (131k+ stars) | AI fit: LLM-ready output for agents and RAG |
| Octoparse | Self-serve, no-code | Freemium + tiers | G2/Capterra 4.7 (Trustpilot 3.7) | W3: a no-code path for non-engineers |
| Scrapy / Crawlee | Open-source | Free (infra only) | No rating (62k / 12k stars) | W1 + W2: fully owned economics, no marketplace lock-in |
Quick Summary
Q: What are the best Apify alternatives in 2026?
A: Ten span three models. Managed: PromptCloud and Grepsr (plus Forage AI in the side-by-side). Scraping and data APIs: Bright Data, Zyte, Oxylabs, ScraperAPI, ScrapingBee, and Firecrawl. Self-serve and open-source: Octoparse and Scrapy/Crawlee. The right pick depends on your binding constraint, not a ranking: managed for maintenance and ownership, APIs for unblocking, self-serve for owned economics.
Expert Insights
Proxy economics reward a scale most teams never reach, and that is the tell for which model fits. Bright Data’s residential pricing drops from $8.40/GB at 10GB to $3.30/GB at 10TB, so the per-unit infrastructure savings only land at volumes far beyond what a typical in-house team runs. For most buyers, that gap is the clearest signal that the infrastructure layer is better absorbed by a provider than rented in pieces, which is why the API and managed categories exist at all.
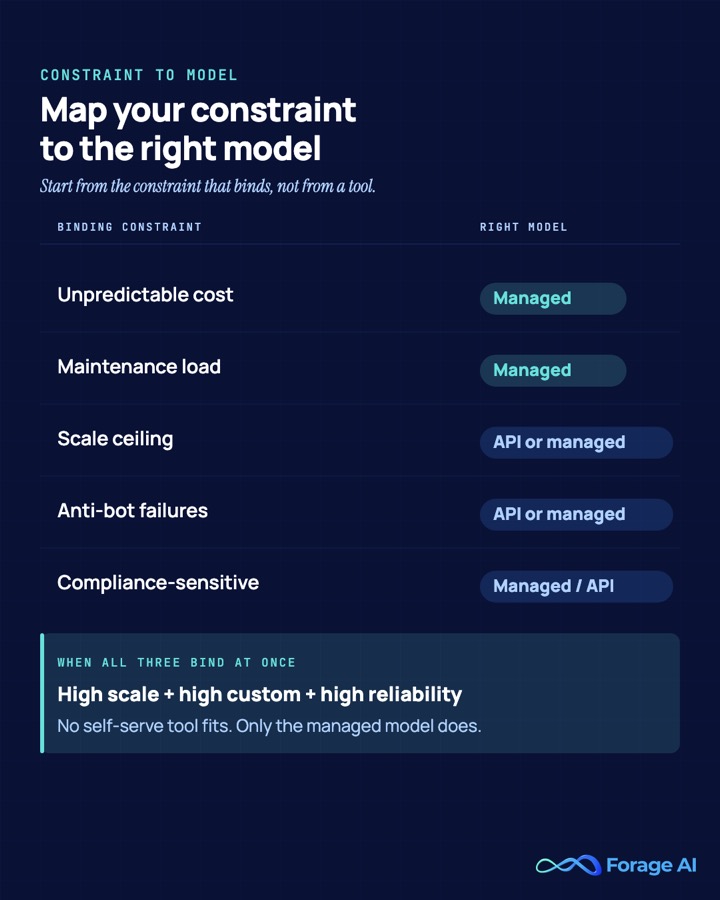
How to choose: a decision framework
Start from your binding constraint, not from a tool. The SERP gives you category buckets and leaves you to connect them yourself. The logic that connects a problem to a model is the thing nobody publishes, so here it is, as three questions.
Question one: is the pain structural or self-inflicted? If a single oversized Actor or an abandoned community Actor is the cause, fix it in place and stop. If the cost model itself, a scale ceiling, an ongoing maintenance load, anti-bot failures, or compliance exposure is binding, the model is wrong for you and a switch is warranted.
Question two: how many constraints bind at once? If one constraint dominates and you have engineering capacity to spare, an API or self-serve tool fits: Bright Data or Oxylabs for unblocking, ScraperAPI or ScrapingBee for clean egress, Octoparse or Scrapy for owned control. If two or more bind together, the math tips toward managed.
Question three: do scale, customization, and reliability all bind together? If they do, the search for a tool is over.
> If high scale, high customization, and high reliability all matter at once, no self-serve tool is the right answer. A managed provider is. That quadrant is the central claim of this whole guide, because it is the gap no tool fills and no roundup names.
A tie-breaker earns its place when two models look close. If your scored comparison lands within roughly 5% across models, break the tie on the dimension that will cost you the most in year two. For most teams running business-critical pipelines, that is maintenance load (the unplanned engineering drain that compounds) or compliance ownership (which shapes your contract and renewal position). To formalize the evaluation, the how to evaluate a data-extraction vendor checklist pairs directly with this framework.
Quick Summary
Q: How do you choose the right Apify alternative for your team?
A: Ask three questions. Is the pain structural or self-inflicted? How many constraints bind at once? Do scale, customization, and reliability all bind together? One dominant constraint points to an API or self-serve tool; two or more, or all three of scale-customization-reliability, point to managed. Break ties on the dimension whose failure costs the most in year two.
Expert Insights
The decision compresses to one variable in practice. When managed delivery is benchmarked against in-house, the number that decides the math is maintenance hours per source, not the sticker price, because maintenance is the line that compounds while the headline rate sits still. A precise per-source figure from real deployments would make that rule load-bearing rather than directional. “
Migrating off Apify: practical considerations
Migration is a phased process, not a flip, and it is the operational reality every roundup skips. The switching cost is never zero on any path, but it differs sharply by where you are going. We recommend running these five steps in order.
Step one: export your Apify datasets. They are available in JSON, CSV, Excel, XML, HTML, RSS, and JSONL (confirm the current list on Apify’s storage docs before you plan around it).
Step two: map each Actor to an equivalent in the target model. An API equivalent if you are staying hands-on, or a requirements spec if you are moving to managed.
Step three: run parallel or shadow tests so the new pipeline proves itself against the old one before you trust it with anything downstream.
Step four: cut over once the new feed matches the old on coverage and quality.
Step five: re-point downstream consumers and keep a rollback path ready in case the new feed misbehaves under real load.
The target model changes the nature of the work, which is the part to weigh before you commit. Moving to another self-serve tool or an API means rebuilding scrapers and parsers, the same work in a new place. Moving to a managed provider shifts the job from “rebuild scrapers” to “hand off requirements,” which is a fundamentally different switching cost. And there is a clock on all of it: the longer the decision sits, the more your existing data ages underneath you. For the deeper mechanics, the migration mechanics guide transfers directly to a platform switch.

Quick Summary
Q: What does migrating off Apify actually involve?
A: Five steps in order. Export your Apify datasets, map each Actor to an equivalent in the target model, run a parallel or shadow test, cut over, then re-point downstream consumers with a rollback plan. On a managed model, the work shifts from rebuilding scrapers to handing off requirements.
Expert Insights
The cost of delay is measurable, which is the argument against an indefinite hold. Whatever dataset a stalled migration is protecting keeps degrading on the data-decay curve: B2B contact data decays roughly 22.5% per year, and 70.8% of business contacts change within 12 months, while the decision waits. That is part of why a phased, parallel-tested switch beats sitting still. A real onboarding or time-to-launch figure from an anonymized migration would give this step a concrete anchor. “
FAQ
Apify vs Bright Data, which is better?
They are different models, so it is not apples to apples. Bright Data is an API plus proxy and data-infrastructure provider; Apify is a self-serve actor platform. For high-scale unblocking of hard targets when you have engineering capacity to own the parsers, Bright Data’s proxy depth (G2 4.6 across 284 reviews) is the stronger pick. For lightweight orchestration of well-maintained Actors on stable targets, Apify holds its own. Neither owns the full pipeline; for that you want a managed provider.
Is there a free Apify alternative?
Scrapy and Crawlee are the leading free, open-source options, with roughly 62k and 12k GitHub stars respectively. Free describes the license, not the cost of running it in production. You inherit the 30-70% maintenance tax engineers spend fixing broken parsers, plus anti-bot tuning and proxy costs. Note also that Crawlee is built by Apify, so it is less of a clean break than it looks. Firecrawl offers a free 1,000 pages per month for AI-pipeline use if your need is LLM-ready markdown rather than typed extraction.
What is the best Apify alternative for enterprise scale?
It depends on the binding constraint. If the constraint is unblocking at scale, Bright Data or Oxylabs (G2 4.5 across 362 reviews) lead the API category. If scale, customization, and reliability all bind at once, no self-serve tool covers that quadrant and a fully managed provider does, owning breakage, QA, maintenance, compliance, and delivery so the maintenance variable drops out of your math. Grepsr and PromptCloud are the closest reviewed managed comparators; Forage AI is the deeper managed treatment in the side-by-side above.
When should you stay on Apify?
Stay when you run well-maintained Actors on stable, popular targets where layout changes are rare, when you need lightweight orchestration of multi-step pipelines, when access to Crawlee on managed infrastructure is the draw (Crawlee is Apify’s own SDK), and when your team has the engineering hours to tune compute-unit usage well. In short, stay when none of the seven weaknesses bind. “The problem is always Apify” is false; sometimes Apify is the right tool.
What is the best managed Apify alternative?
A managed provider owns the full chain: source discovery, extraction, QA, maintenance, compliance, and delivery. Among reviewed comparators, Grepsr (Capterra 4.7 across ~81 reviews) and PromptCloud (G2 4.6) are the closest. The model fits when data is the product and you do not want to own extraction infrastructure. The trade is that it is a contract and partnership model, not a $49 self-serve API key.

Where to start
When an Apify bill spikes or an Actor breaks at 2 a.m., the instinct is to go shopping for a better tool. That instinct points at the wrong variable. The headline price on a pricing page is the number that changes least over three years. Maintenance hours per source is the number that compounds, and it is the one that actually decides whether to build, buy, or hand off.
So map your binding constraint to a model before you shortlist anything. If one constraint dominates and you have the engineering hours, pick an API or self-serve tool from the list above. If scale, customization, and reliability all bind at once, the search for a tool is over, because no tool occupies that quadrant. A managed provider does, and the maintenance variable disappears from your ledger because someone else carries it. The switch was never really about which tool. It was about which model owns the cost you cannot see on the invoice.
Related Articles
- Web Scraping Companies vs Tools: Which Fits Your Team. The two-way build-vs-buy lens this guide extends into three models.
- Bright Data Alternatives for Enterprises: A Managed Provider Guide. Sibling alternatives guide for the proxy and data-provider category.
- Octoparse Alternatives: Best Web Scraping Tools & Managed Services Compared. For teams outgrowing no-code and point-and-click scrapers.
- Build or Buy? A Strategic Guide to Web Data Extraction. The full TCO model behind the build-vs-buy decision.
- Custom Web Scraping: When Off-the-Shelf Tools Stop Scaling. The managed and custom path after self-serve tools hit a ceiling.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




