

You bought a firmographic database six months ago. It came with promises, millions of company records, dozens of attributes per record, and a refresh schedule on the contract. Today, your sales team has quietly stopped trusting it. About 40% of the company URLs are dead. Half the revenue brackets are guesses. The technology stack is two years out of date on the accounts that matter most.
This is the part nobody warns you about. Firmographic data is not a one-time purchase. It is a continuously decaying asset, closer to inventory than to software. The day you buy it, it starts to age. By the time your AI scoring model is in production, a meaningful slice of the data feeding it is already wrong.
This guide is for the data and product leaders who are tired of that pattern. We will cover what firmographic data actually is, the attributes that make up a usable record, where the data comes from at a sourcing-mechanics level, why static databases decay faster than you would expect, and what continuous, real-time firmographic intelligence looks like in practice. The goal is not a vendor pitch; it is a clear-headed view of what good firmographic data looks like in 2026 and what it takes to keep it good.
Quick Digest
- What firmographic data is: the descriptive, company-level attributes B2B teams use to identify, segment, score, and target other businesses, the business equivalent of demographic data for a person.
- The core attributes: a usable record carries company name and legal entity, industry classification, size, revenue, founding year, location, technology stack, web presence, business model, funding stage, and corporate structure.
- Why it matters for B2B: firmographic data is the substrate beneath segmentation, lead scoring, TAM sizing, and AI scoring models, when it is wrong, every downstream system inherits the error.
- The six sources: records are assembled from public web and company sites, business registries and filings, news and press feeds, social and professional platforms, third-party providers, and internal CRM signals.
- The decay problem: static B2B data decays at 20 to 30% per year, so by month twelve a large share of any database you bought is wrong with no clean way to tell which records are stale.
- Real-time intelligence: the alternative is a continuously refreshed, custom-enriched, vertical-aware layer that re-verifies each field on a cadence tuned to how fast it actually changes.
- The seven-point evaluation: judge any provider on freshness, coverage, accuracy and match rate, vertical depth, custom-field capability, sourcing transparency, and data ownership.
What Is Firmographic Data?
Firmographic data is the descriptive information about a company, the business equivalent of demographic data for a person. It is the set of attributes a B2B team uses to identify, segment, score, and target other businesses.
At its core, firmographic data answers a small list of questions: What does this company do? How big is it? Where is it? How does it make money? What does it run on? The answers are delivered as structured fields, and the same fields appear across nearly every commercial firmographic dataset.
A usable firmographic record typically includes the following attributes:
| Attribute | What it captures |
|---|---|
| Company name and legal entity | The canonical name, plus aliases, DBA, and parent / subsidiary structure |
| Industry classification | NAICS, SIC, or proprietary industry codes |
| Company size | Headcount, often bucketed by employee range |
| Annual revenue | Reported or modeled, often bucketed |
| Founding year | Year of incorporation |
| Location | HQ address, plus offices and geographic footprint |
| Technology stack | Software, platforms, and infrastructure the company runs on |
| Social and web presence | Website, LinkedIn, social URLs |
| Contact details | General switchboard, key role emails (where compliant) |
| Business model | B2B, B2C, B2B2C, marketplace, services, etc. |
| Funding stage | Bootstrapped, Series A–D, public, private equity owned |
| Corporate structure | Parent company, subsidiaries, division relationships |
These are the load-bearing fields. Beyond them, vertical-specific firmographic datasets add specialized attributes, for example, NPI numbers and specialty codes in healthcare firmographic data, or property portfolio size and asset class in real estate firmographic data.
Firmographic vs. demographic vs. technographic data
Firmographic data sits inside a small family of B2B data types that are often confused:
- Demographic data describes people, age, role, seniority, and location. It is the foundation of contact-level targeting.
- Firmographic data describes companies, size, industry, revenue, and location. It is the foundation of account-level targeting and ICP scoring.
- Technographic data describes the technology a company uses, such as CRM, marketing automation, data warehouse, and cloud provider. In practice, it is a subset of firmographic data, though many teams treat it as its own category.
| Data type | What it describes | Example | Primary use |
|---|---|---|---|
| Firmographic | The company, its size, industry, revenue, and location | 500-employee SaaS firm, $80M revenue, headquartered in Austin | Account-level targeting and ICP scoring |
| Demographic | The person, age, role, seniority, and location | VP of Data, based in Boston, 15 years experience | Contact-level targeting |
| Technographic | The technology the company runs on | Salesforce CRM, Snowflake warehouse, AWS cloud | Buying-signal and readiness context |

A good B2B motion uses all three. Firmographic segmentation is what stitches them into something an account-based team can actually act on.
Quick Summary
Q: What is firmographic data?
A: Firmographic data is the descriptive, company-level information B2B teams use to identify, segment, score, and target other businesses, the business equivalent of demographic data for a person. A usable record carries attributes like company name and legal entity, industry classification, size, revenue, location, technology stack, business model, funding stage, and corporate structure. It describes companies, where demographic data describes people and technographic data describes the technology a company runs on.
Expert Insights
“Technographic data gets treated as its own category, but operationally it is a subset of the firmographic record, one more field about what a company runs on. The teams that get the most out of firmographic data stop separating the three families and treat them as one account-level picture.”
Forage AI data team
Why Firmographic Data Matters for B2B
Firmographic data is the substrate every account-based B2B motion sits on top of. When the firmographic layer is solid, segmentation, scoring, territory planning, and AI models all work better. When it is wrong, every downstream system inherits the error.
Segmentation and ICP fit
The first job firmographic data does is help a team define its ideal customer profile and then find more companies that match it. Industry, size, revenue band, geography, and technology stack are the dimensions most teams use to draw the ICP. Without trustworthy firmographic fields, “ICP fit” is a guess.
Lead scoring and account prioritization
Once the ICP is defined, firmographic attributes feed the lead-scoring model that ranks accounts. Bigger company, in the right industry, in the right geography, running the technology that signals readiness, those signals come from firmographic data. A scoring model trained on stale firmographic inputs prioritizes the wrong accounts.
TAM sizing and territory planning
When a head of sales or a finance lead asks, “How many companies can we sell to?” the answer is a firmographic query. The same query, sliced by region or industry, sets territory boundaries and quota targets. Inaccurate firmographic data quietly inflates or deflates the TAM by 15–30%, which is enough to make a hiring plan wrong.
Inputs to AI and ML scoring models
Roughly 65% of enterprises now use external data extraction to feed AI and ML projects, and firmographic data is one of the most common inputs to B2B scoring models. Predictive lead scoring, propensity-to-buy models, churn risk models, and account-similarity models all rely on firmographic features. The accuracy ceiling of any B2B AI model is set by the accuracy of the firmographic layer feeding it.
In other words: firmographic data is not a sales-ops convenience. It is infrastructure.
Quick Summary
Q: Why does firmographic data matter for B2B?
A: Firmographic data is the substrate every account-based B2B motion sits on top of, so when it is solid, segmentation, lead scoring, TAM sizing, territory planning, and AI models all work better, and when it is wrong, every downstream system inherits the error. It defines ICP fit, feeds the lead-scoring model, answers “how many companies can we sell to,” and serves as one of the most common inputs to B2B AI models. Inaccurate firmographic data can swing TAM by 15 to 30%, enough to make a hiring plan wrong.
Expert Insights
“The accuracy ceiling of any B2B AI model is set by the accuracy of the firmographic layer feeding it. Around 65% of enterprises now use external data extraction to feed AI and ML projects, so the firmographic record stopped being a sales-ops convenience and became infrastructure. Teams that treat it as a one-time list rather than a maintained layer inherit the error everywhere downstream.”
Forage AI data team
Where Firmographic Data Comes From
Here is where most articles on firmographic data stop. They tell you what the attributes are and how to use them. They rarely tell you where the actual values come from, which is the question that determines whether the data is any good in the first place.
Firmographic datasets are assembled from six broad source layers, usually in combination:

| Source layer | What it provides / best for |
|---|---|
| Public web and company websites | Highest-authority source for official name, HQ address, leadership, and product description, crawled at scale |
| Business registries, filings, and government data | Verifiable legal entity info, incorporation date, registered office, officers, and filings (SEC EDGAR, Companies House) |
| News, press releases, and content signals | The timeliness layer, funding rounds, leadership changes, acquisitions, layoffs, and expansion within days |
| Social and professional platforms | Headcount signals, role information, and technology-stack inferences where a company has not published its own size |
| Third-party providers and resellers | Pre-assembled records enriched and resold, fast to add but can propagate a single bad upstream record |
| Internal CRM and first-party enrichment | Closed deals, disqualification reasons, and “wrong contact” flags, the most overlooked firmographic signal |
Public web and company websites
The company’s own website is the highest-authority source for a small set of fields, including official name, headquarters address, leadership team, product description, and sometimes a contact page. Crawling the web at scale is how providers gather these fields across millions of companies. How company data is extracted from the public web is its own discipline, it involves identifying sources, handling structural change, and validating extracted values.
Business registries, filings, and government data
For verifiable legal entity information, the incorporation date, registered office, officers, filings, and public business registries are the canonical sources. In the US, this includes SEC EDGAR for public companies and state-level Secretary of State databases. In the UK, Companies House. Each country has its own registry, and the formats vary.
News, press releases, and content signals
Funding announcements, leadership changes, acquisitions, layoffs, expansion news, these are firmographic events, not just stories. News and press release feeds are the timeliness layer of the firmographic stack. A good firmographic record updates within days of a funding round announcement, not at the next quarterly refresh.
Social and professional platforms
Within platform terms of service, professional social platforms add headcount signals, role information, and technology-stack inferences. This is where most “size” estimates actually come from when a company has not published its own headcount.
Third-party providers and resellers
Many firmographic datasets are partly assembled from other firmographic datasets. Resellers buy from D&B, ZoomInfo, or specialist verticals, enrich with their own signals, and resell. This is fine when done transparently, but it also means a single bad upstream record can propagate across half the market.
Internal CRM and first-party enrichment
The most overlooked source is your own CRM. Every closed deal, every disqualification reason, every “wrong contact” flag is a firmographic signal. Mature data teams treat their CRM as a source, not just a consumer, and feed first-party signals back into the firmographic record.
The point is not that any single source is better than the others. The point is that a usable firmographic record is assembled continuously from many sources, and the quality of the assembly is what separates a good provider from a list broker.
Quick Summary
Q: Where does firmographic data come from?
A: Firmographic datasets are assembled from six broad source layers, usually in combination: public web and company websites, business registries and government filings, news and press release feeds, social and professional platforms, third-party providers and resellers, and internal CRM and first-party enrichment. No single source is better than the others. A usable record is assembled continuously from many sources, and the quality of that assembly is what separates a good provider from a list broker.
Expert Insights
“The most overlooked source is the buyer’s own CRM. Every closed deal, every disqualification reason, every wrong-contact flag is a first-party firmographic signal, and mature teams feed it back into the record instead of only consuming external data. When a reseller layer sits in the middle, a single bad upstream record can propagate across half the market, which is why sourcing transparency matters as much as the sources themselves.”
Forage AI data team
The Hidden Problem with Static Firmographic Databases
Most teams discover the freshness problem the same way: six to twelve months after they bought the database.
How fast does firmographic data decay
Industry research consistently puts B2B data decay rates at 20–30% per year. Some studies, particularly on contact-level data, go higher. Companies move offices, change names, get acquired, lay off staff, switch tech stacks, IPO, go private, and shut down at a steady rate. Each of those events invalidates one or more fields in a firmographic record.
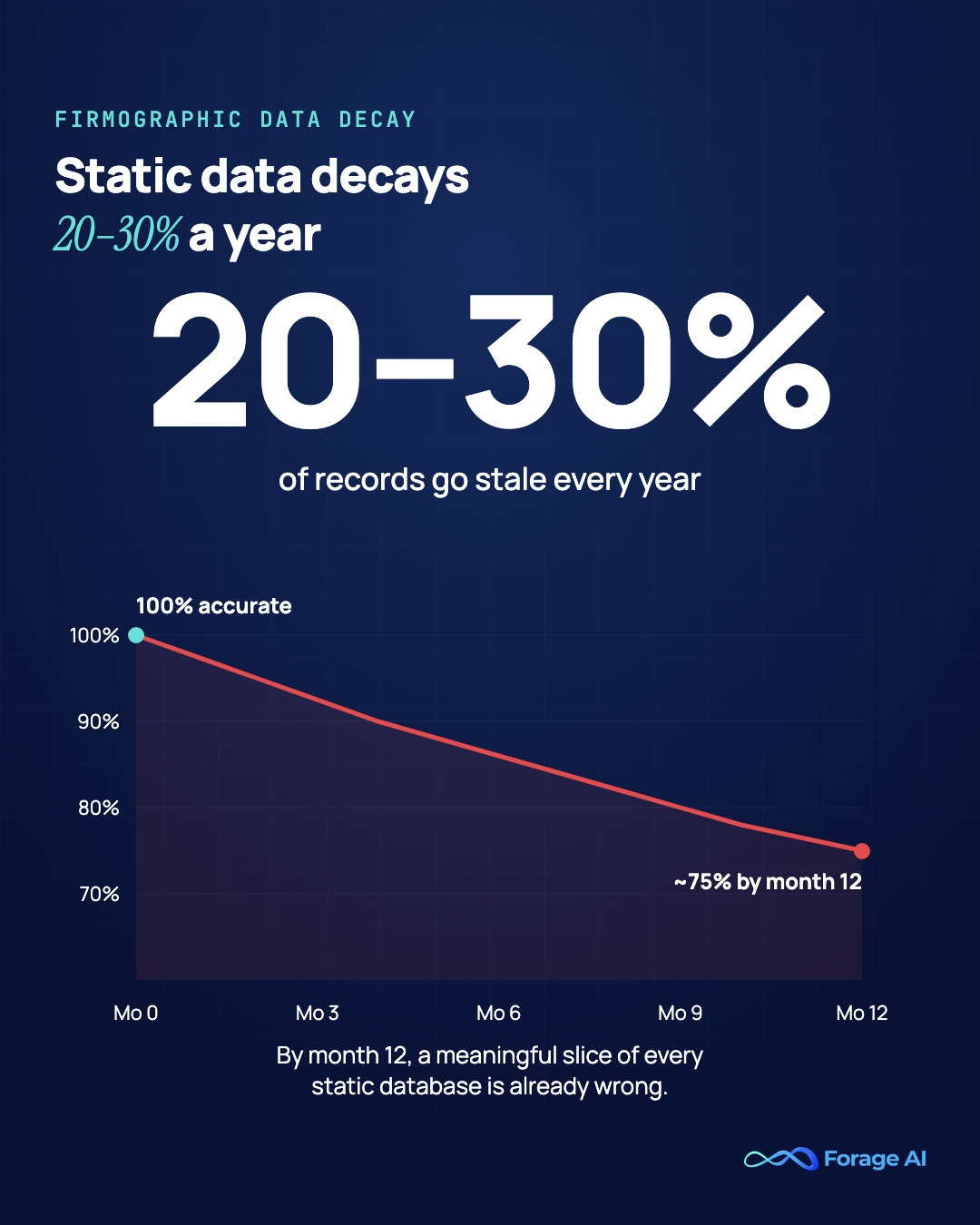
By month twelve, a large share of the database you bought is wrong, and you have no clean way to tell which records are stale and which are still accurate.
The twelve-vendor sprawl pattern
What we see at scale, especially inside larger B2B teams, is the following pattern. The team starts with one firmographic provider. The provider misses a vertical, so they add a specialized one. They need real estate signals, so they add a real estate firmographic vendor. They need news triggers, so they add a news provider. They need contact-level data, so they add a contact provider.
Twelve months in, the team is managing a dozen vendor relationships, a dozen schemas, a dozen invoices, and a dozen subtly different definitions of “company.” A 30–50-person aggregation team is stood up whose only job is field mapping, deduplication, and conflict resolution. The team’s best people are doing field mapping instead of strategy.
This is not a hypothetical pattern. It is the most common state we encounter in first conversations with B2B data teams who have outgrown an off-the-shelf provider.
The “40% wrong URLs” problem
One real example: an asset management firm bought a flagship firmographic dataset from a name-brand provider. The first time their team actually tried to use it, 40% of the company URLs were dead, companies had been acquired, websites had been redirected, and domains had been parked. The dataset was technically delivered. It was operationally unusable.
A separate example, from a media company’s advertising division: they bought a major firmographic provider’s dataset and could not match a meaningful share of it back to their CRM. The provider’s “company” record and the CRM’s “company” record used different identifiers, slightly different name normalizations, and different industry codes. Matching it required a custom entity matching project, which was the kind of work the firmographic purchase was supposed to eliminate.
The lesson is not that any one provider is bad. The lesson is that a static, point-in-time firmographic database is the wrong shape of asset for a continuously changing world. Warning signs your B2B database is limiting growth usually surface here.
Quick Summary
Q: What is the hidden problem with static firmographic databases?
A: Static firmographic databases decay at 20 to 30% per year, so by month twelve a large share of the database is wrong with no clean way to tell which records are stale. The problem compounds in two ways: vendor sprawl, where a team ends up managing a dozen providers, schemas, and definitions of “company” and a 30 to 50-person aggregation team, and operational failures like the asset management firm that found 40% of its company URLs dead on first use. A point-in-time database is the wrong shape of asset for a continuously changing world.
Expert Insights
“The vendor-sprawl pattern is the most common state we encounter in first conversations with B2B data teams who have outgrown an off-the-shelf provider. Twelve months in, a 30 to 50-person aggregation team is doing field mapping, deduplication, and conflict resolution instead of strategy. The asset-management firm that found 40% of its URLs dead on first use is not an outlier, it is what a point-in-time database looks like once it ages.”
Forage AI data team
What Real-Time Firmographic Intelligence Looks Like
The alternative to the static-database pattern is real-time firmographic intelligence, a continuously refreshed, custom-enriched, vertical-aware data layer that behaves like infrastructure rather than a product purchase. Forage AI’s firmographic product is built this way: real-time company data, not stale databases.

Continuous monitoring versus quarterly refresh
The most basic shift is cadence. Instead of receiving a quarterly or semi-annual snapshot, a continuously monitored firmographic dataset re-verifies each field on a schedule tuned to its actual change frequency. HQ address: maybe once a quarter. Funding stage: within days of a news signal. Headcount: monthly. Technology stack: monthly to quarterly, depending on signal strength. The result is a record that is always within its own freshness window, and a freshness timestamp on every field, so a downstream team can decide whether to trust it.
| Field | Re-verify frequency |
|---|---|
| HQ address | Roughly quarterly |
| Funding stage | Within days of a news signal |
| Headcount | Monthly |
| Technology stack | Monthly to quarterly, depending on signal strength |
Custom enrichment
A second shift is the move from fixed schemas to custom enrichment. Most off-the-shelf firmographic datasets ship a fixed schema, twenty or thirty fields, take it or leave it. A custom firmographic layer adds the fields your scoring model actually needs: a specific product signal scraped from the company’s site, a regulatory filing flag, a vertical-specific identifier, and a sub-industry classification that does not exist in NAICS. You define the fields. The pipeline goes and gets them.
Vertical-specific depth
Healthcare firmographic data requires NPI numbers, specialty codes, taxonomy classifications, and provider network relationships. Real estate firmographic data needs property portfolio size, asset class, and ownership structure. General firmographic data, the kind most B2B teams need, needs solid industry coding, technology stack, funding signals, and parent/subsidiary structure. A real-time firmographic provider offers vertical-depth datasets, ensuring the right fields are available for the use case.
The QA layer that makes “fresh” data actually trustworthy
Freshness without quality assurance is just high-frequency noise. The QA layer is what makes a continuous firmographic feed usable, with multi-method extraction, automated regression testing, and human review for edge cases. Forage AI runs a QA team three times the industry average size relative to delivery, and 500M+ websites have been crawled across our operating history. That QA layer is the difference between a stream of changes you can act on and a stream of noise you have to filter.
This is the operating model we built the firmographic product around: continuous monitoring, custom enrichment, and vertical depth across healthcare, real estate, and general firmographic datasets, with data ownership remaining with the client and no reselling.
Quick Summary
Q: What does real-time firmographic intelligence look like?
A: Real-time firmographic intelligence is a continuously refreshed, custom-enriched, vertical-aware data layer that behaves like infrastructure rather than a product purchase. Instead of a quarterly snapshot, each field is re-verified on a cadence tuned to how fast it changes, HQ address roughly quarterly, funding stage within days of a news signal, headcount monthly, technology stack monthly to quarterly, with a freshness timestamp on every field. It adds the custom fields a scoring model needs, offers vertical depth for healthcare and real estate, and runs a QA layer that turns a stream of changes into something a team can act on.
Expert Insights
“Freshness without quality assurance is just high-frequency noise. We run a QA team three times the industry average size relative to delivery and have crawled 500M+ websites across our operating history, because that QA layer is the difference between a stream of changes you can act on and a stream you have to filter. Re-verifying each field on a cadence tuned to how fast it actually changes is what makes the data behave like infrastructure.”
Forage AI data team
How to Evaluate Firmographic Data Quality
If you take only one thing from this article, take this: the question is not “is the data right?” but “how do we know?” A good firmographic provider can answer that question for every field they deliver. A weaker one cannot.
When evaluating a firmographic dataset, work through this checklist:
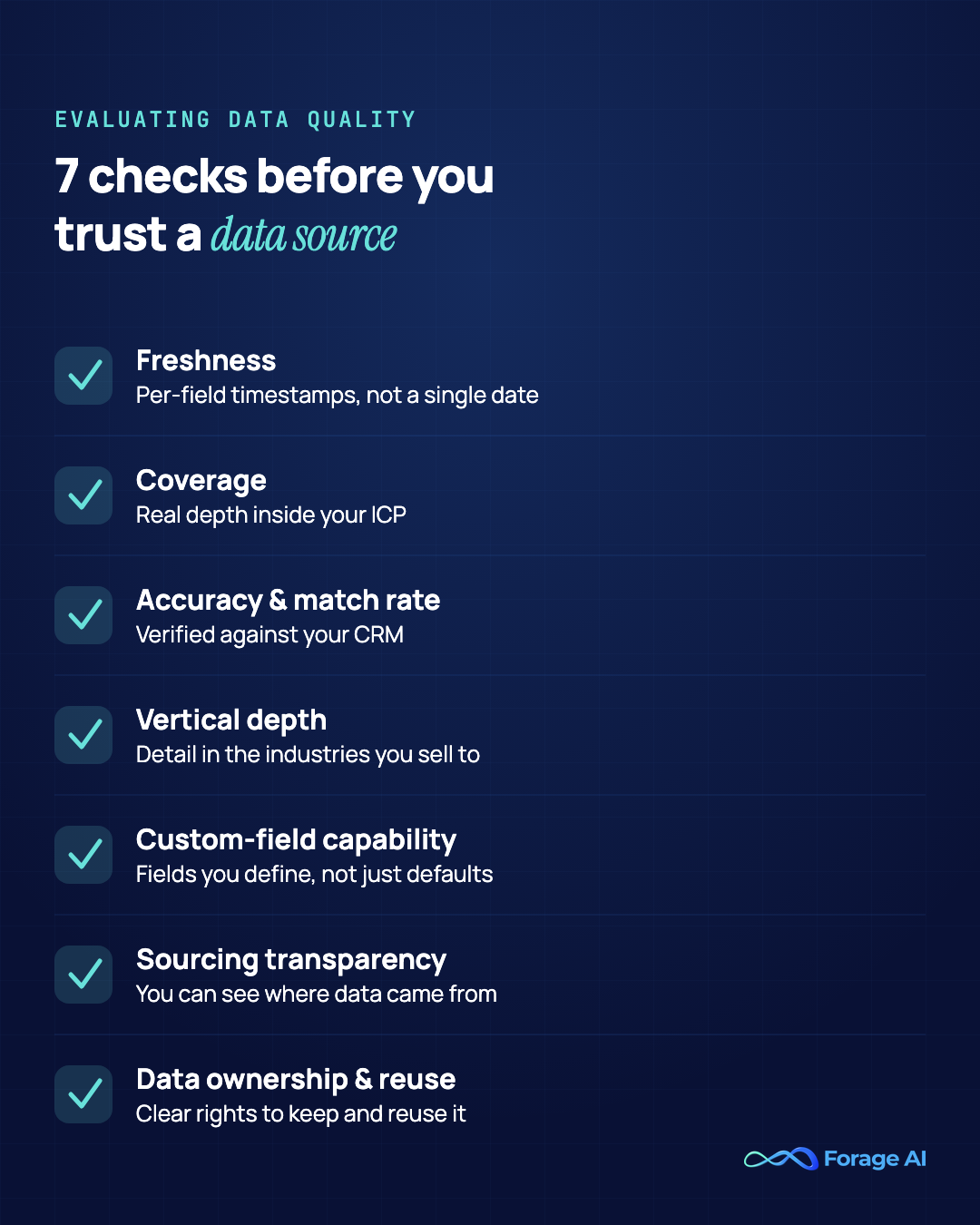
- Freshness. How often is each field re-verified? Is there a per-field freshness timestamp on every record, or just one “last refreshed” date for the whole dataset?
- Coverage. How many records exist for your target geography, industry, and size band? Coverage at the global aggregate level is meaningless; coverage in your ICP is what matters.
- Accuracy and match rate. What percentage of records successfully match your existing CRM? Ask for a sample on a known set of your own accounts before signing anything. This is the single best signal of real-world quality.
- Vertical depth. If you are in healthcare, real estate, finance, or another vertical with specialized firmographic needs, does the provider have a vertical-specific dataset, or are they bolting your vertical onto a general schema?
- Custom-field capability. Can you add fields that the off-the-shelf dataset does not have? Or are you stuck with the fixed schema?
- Sourcing transparency. Can the provider tell you where each field came from? If a provider cannot answer that question for their own data, that is a signal.
- Data ownership and reuse. Is the data you receive free to use, or are there restrictions? Does the provider resell aggregated derivatives of what they collect for you?
A practical way to run this evaluation is to take your hardest 1,000 target accounts, send them to two or three providers, and compare the match rate and field accuracy against what you already know. The complete guide to selecting a B2B data provider walks through the full process if you want a deeper framework.
Quick Summary
Q: How do you evaluate firmographic data quality?
A: The question is not “is the data right?” but “how do we know?”, and a good provider can answer that for every field they deliver. Work through a seven-point checklist: freshness (per-field timestamps), coverage in your ICP rather than the global aggregate, accuracy and match rate against your CRM, vertical depth, custom-field capability, sourcing transparency, and data ownership and reuse. The single best test is to take your hardest 1,000 target accounts, send them to two or three providers, and compare match rate and field accuracy against what you already know.
Expert Insights
“Accuracy and match rate against your own CRM is the single best signal of real-world quality, so ask for a sample on a known set of your own accounts before signing anything. Coverage at the global aggregate level is meaningless; what matters is coverage inside your ICP. If a provider cannot tell you where each field came from, that opacity is itself a signal about the rest of the data.”
Forage AI data team
Frequently Asked Questions
What is firmographic data in simple terms?
Firmographic data is descriptive information about a company, including its industry, size, revenue, location, technology stack, and other attributes. It is the company-level equivalent of individual demographic data, and it is what B2B teams use to segment, score, and target other businesses.
How is firmographic data different from technographic data?
Firmographic data describes the company itself, what it does, how big it is, where it is, and how it makes money. Technographic data is a subset focused specifically on the technology a company uses, its CRM, marketing automation, cloud provider, and other tools. Most B2B teams use both together; technographic data adds buying-signal context on top of the firmographic foundation.
Where do firmographic data providers get their data?
A combination of six layers: public web and company websites, business registries and government filings, news and press release feeds, social and professional platforms, third-party providers, and the buyer’s own CRM. The quality of a firmographic dataset depends less on any single source and more on how cleanly the layers are assembled and refreshed.
How often does firmographic data become outdated?
Industry research consistently shows B2B data decay rates of 20–30% per year. By twelve months after acquisition, a meaningful slice of any static firmographic database is wrong. The decay is uneven, HQ address moves slowly, headcount and technology stack move faster, funding stage and leadership changes move fastest.
What is real-time firmographic data?
Real-time firmographic data is a continuously refreshed dataset in which each field is re-verified at a cadence appropriate to how often it actually changes, often with per-field freshness timestamps. It is the alternative to the quarterly-snapshot model, and it is what makes firmographic data behave like infrastructure rather than inventory.
Should we build firmographic data in-house or buy it?
Build it in-house only if external data acquisition is a core competency you want to own, and you have the engineering and QA capacity to run a multi-source pipeline at scale. For most B2B teams, partnering with a managed firmographic provider is the right answer because the engineering effort sits outside their product roadmap. The honest answer depends on whether company data is your product or a supporting input.
Conclusion
Firmographic data is foundational, the substrate that segmentation, scoring, TAM analysis, and B2B AI models all rely on. The mistake most teams make is treating it as a one-time purchase rather than a continuously decaying asset. Static databases age out, vendor sprawl creeps in, and six to twelve months later, the team is back where it started.
The fix is not a new provider with the same product shape. The fix is treating firmographic data as infrastructure, continuously refreshed, custom-enriched, vertical-aware, and quality-assured at the field level. If you are weighing the build-versus-partner question for firmographic data, talk to our expert. We will walk through what your specific data layer would look like.
Related Articles
- Firmographic Intelligence: Why Static Data No Longer Cuts It, a deeper dive into real-time firmographic intelligence.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




