

By the time a healthcare data org gets serious about external data, its internal pipelines are already working. The EHR feeds run. The claims warehouse refreshes. Finance gets its month-end. What breaks quietly, on a Tuesday, is the third scraper that monitors competitor service-line pages, or the provider directory job that has been throwing 23% nulls for six weeks because a payer changed its portal layout.
This is the Scale Wall. You did not hit it because you lack engineers. You hit it because external healthcare data management is a different operational discipline from internal data management, and your team was hired to run internal data.
This guide is written for a VP or SVP of Data who already owns the internal stack and now needs to architect the external layer. It is the management lens — portfolio, governance, build/buy/blend, and where a managed acquisition layer fits. The source-by-source playbook lives in our companion healthcare data extraction guide.
What “Healthcare Data Management” Actually Means When You Already Have an EHR
The SERP collapses three distinct problems into a single phrase. Open the first ten results for “healthcare data management,” and you will find clinical pipeline architectures (HL7 v2, FHIR US Core, USCDI v3), Provider Data Management platform marketing, and trend essays about governance maturity. They are all valid. They are also all about different data buckets.

Every healthcare organization at scale runs three data buckets:
- Internal clinical — the EHR, HL7 v2 messages, FHIR APIs, lab feeds, imaging, device streams. This is where most “healthcare data” conversations live. It is governed by HIPAA, USCDI v3 (baseline January 2026 under ONC HTI-1), and increasingly the CMS Interoperability and Prior Authorization Final Rule (CMS-0057-F).
- Claims and transactional — 837/835 transactions, MLR filings, and finance feeds. PHI-adjacent. Governed by HIPAA + payer contracts, and increasingly automated through modern claims processing automation that reduces manual review and accelerates payouts.
- External — the universe of data your organization needs about the world outside its own walls: provider directories, competitor service-line pages, public regulatory transparency files, ClinicalTrials.gov, formulary publications, market intelligence, public reviews. This is the bucket every modern data org leans on more heavily each quarter, and it is the one this article covers.
The first two buckets are usually well-funded inside healthcare data orgs. They have vendor stacks, dedicated teams, and decade-old governance frameworks. The third bucket is where the Scale Wall hits, because the same team that built the EHR feeds is now being asked to also “go scrape” competitor sites, monitor 4,000 hospital provider directories, and pull Care Compare every quarter.
That request is the trigger for this article.
Expert insight: Stephen J. LeBlanc, Chief Strategy Officer at Dartmouth Health, on the broader healthcare data evolution: “It’s the execution that’s the challenge, it’s the investment in the infrastructure.” External data is where the execution challenge bites first, because the infrastructure that runs internal data is not architected to absorb thousands of volatile public sources.
Quick summary: healthcare data management at the VP level means running three distinct buckets. This guide is about the third — the external bucket — and the architectural pattern that makes it tractable.
The Five External Healthcare Data Domains a Modern Data Org Has to Run
Across healthcare data organizations operating at strategic enterprise scale, the external data portfolio almost always sorts into the same five domains:

- Provider directories and affiliation graphs — NPPES, hospital-published rosters, payer directories, system org charts, physician-to-hospital affiliation maps, telehealth networks. This is the foundation everyone uses, and almost nobody trusts. According to industry benchmarks, 4 out of 5 provider directory entries contain inaccuracies, 30% of records have inaccurate or missing NPI numbers, and 23% of addresses are incorrect. Provider information churns at roughly 5% per month.
- Market intelligence — competitor service-line expansion, M&A signals, hiring patterns, capability launches, vendor partnerships, press releases. This is what strategy and corporate development teams ask for, and it is almost always the last domain to be operationalized because it lacks an obvious owner.
- Regulatory and transparency feeds — Hospital Price Transparency machine-readable files, Care Compare, the Healthcare Cost Report Information System (HCRIS), No Surprises Act directories, and Transparency in Coverage payer cuts. Public by mandate, brutally inconsistent in practice. Our companion healthcare data extraction guide covers the seven sources in depth.
- Clinical adjacency — ClinicalTrials.gov hospital sites, public formularies, hospital service-line pages, public quality reports, FDA and NIH adjacent feeds. None of this is PHI. All of it is operationally awkward to ingest at scale.
- Patient-experience signals — public reviews, complaints, social posts, sentiment data, news mentions tied to facilities and physicians. Non-PHI, but reputation-sensitive, and increasingly fed into Net Promoter and retention models.
Stat callout: the cost of provider data mismanagement alone is estimated at $17 billion annually in unnecessary U.S. healthcare spend through claims errors and denials. That is just one of the five domains.
Each domain has its own publisher universe, format spread (PDF, HTML, JSON, bulk CSV, API), refresh cadence (real-time webhook to annual filing), and failure mode. No internal team should be asked to own all five at production quality without a partnership model behind them.
The Scale Wall: Why Your Internal Team Can Run Three of These Well, Then Stalls
In our pattern of working with healthcare data orgs, the consistent observation is what we call the Three Source Limit. A capable internal data team — say, four to eight engineers, a QA lead, and a DataOps function — can build and maintain roughly three production-grade external data sources before maintenance dominates the roadmap. Past that, every new source is a tax on the team’s ability to ship anything else.
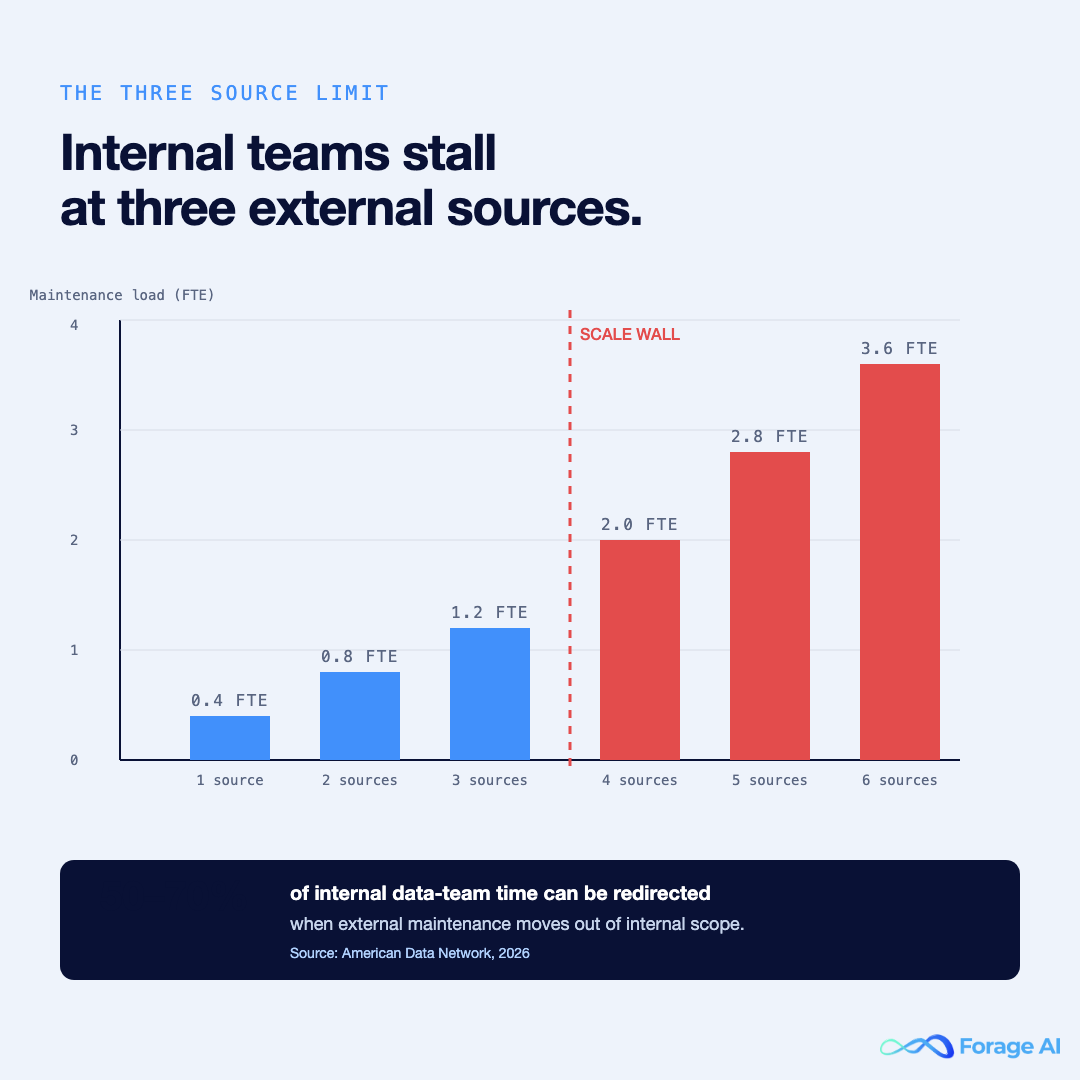
The mechanics are repeatable:
- Schema drift. Provider portals, MRF templates, and hospital service-line pages change on a cadence the publishers do not announce. Every change is a silent break.
- Anti-bot and ToS hygiene. Public sources are public; that does not make access frictionless. Rate limits, IP rotations, captcha gates, and terms-of-service changes are a constant operational layer that healthcare engineers were not hired to run.
- Vendor portal changes. Payer portals, hospital credentialing pages, and state licensure boards reskin without warning. A team can absorb one or two reskins a quarter, not eight.
- Escalating QA burden. A schema-valid file can still be wrong. Filler values (
5555, empty strings, default zeros) propagate silently. Once a source exceeds ~100k records per refresh, validation needs its own QA practice—not a side responsibility on a Jira ticket. - Lineage and audit fatigue. Every external source must be defensible to compliance. That is a parallel workload most internal teams underestimate at scoping.
Cost math, plainly: in practice, each new external source adds 0.3 to 0.5 FTE of permanent maintenance load after the initial build. Three sources is a person and a half of operational drag. Six sources are three people doing maintenance work instead of analytics, RAG, and product.
The reason this matters at VP altitude: this drag is invisible on the staffing plan. It shows up as “we are behind on the roadmap,” not as “we are spending half a team running break-fix on public scrapers.” Industry analysis suggests that healthcare data teams can redirect 50 to 70% of staff time when the manual abstraction and maintenance load is removed from internal scope. That number lines up with what we see when an acquisition layer is introduced.
HIPAA, Without the Hand-Wave: Where the Boundary Actually Sits
The single most common confusion in external healthcare data is the assumption that HIPAA applies to all of it. It does not. The legal anchor is 45 CFR §160 and §164. HIPAA governs covered entities and their business associates handling protected health information. Public, non-identifying, publisher-controlled data sources sit outside that boundary.

That includes:
- NPPES and public NPI rosters
- Hospital Price Transparency MRFs and shoppable services files
- Care Compare and the CMS Provider Data Catalog
- HCRIS cost reports
- ClinicalTrials.gov hospital site listings
- Public formulary publications
- Hospital service-line marketing pages
- Public reviews and complaints data
The compliance work for these sources is not PHI safeguarding. It is terms-of-service hygiene, accurate sourcing, lineage documentation, and audit log retention. Important, but not HIPAA.
The HIPAA boundary does still matter when:
- The acquisition layer ingests partner-shared rosters from a covered entity (a BAA is required)
- A source sits behind a payer portal that requires authenticated access to a covered entity’s system (BAA-territory; treat as PHI-adjacent)
- A downstream join links external public data to internal patient identifiers (the join, not the source, brings it inside HIPAA)
This is where the SOVEREIGN posture matters and is worth being explicit about in any vendor conversation:
- Client data is not resold or aggregated across clients. Full stop.
- External data sources are not fed into third-party large language models for retraining or shared inference.
- On-premise delivery is available for clients whose policy requires data to stay inside their own infrastructure.
- BAA coverage is in place where the acquisition layer touches covered-entity systems.
A VP of Data should expect all of these in writing before any external healthcare data is brought into their environment.
Build / Buy / Blend: A Portfolio Lens, Not a Source Lens
Most teams approach external data with a per-source build-vs-buy question. That is the wrong altitude. For a portfolio of five domains, the right frame is a 2×2 matrix of strategic value vs. volatility, applied across the whole portfolio at once.

| Low volatility | High volatility | |
|---|---|---|
| Strategic differentiation | Build internally. This is where your engineers create defensible IP. The maintenance load is sustainable. | Blend. Acquisition layer handles the volatility; your team owns the strategic enrichment and modeling on top. |
| Commodity | Buy a packaged dataset. Vendor coverage, freshness, and price are the only questions. | Buy or outsource. Internal build is almost never worth it; you are paying for an annuity of maintenance. |
Across the five domains:
- Provider directories: high volatility, mixed strategic value. Most orgs land in a blend: an acquisition layer for breadth, an internal team for affiliation modeling. When you do reach for a packaged feed here, our guide to evaluating healthcare data providers on coverage, compliance, and freshness is the scorecard to bring.
- Market intelligence: high volatility, high strategic value (this is competitive intel). Blend. Outsource the listening; keep the synthesis internal.
- Regulatory and transparency: medium volatility, commodity. Outsource. The maintenance load on MRFs alone is a permanent drag.
- Clinical adjacency: medium volatility, strategic. Blend. Outsource ingestion; keep modeling for quality and outcomes internal.
- Patient-experience signals: high volatility, mixed strategic value. Outsource unless reputation analytics is a product line in itself.
The implication: a healthy external healthcare data portfolio almost never lives entirely inside an internal team, and almost never lives entirely with a single vendor. Blend is the modal answer. For the full decision framework, see our build vs. buy guide for web data extraction.
Architecture: The Acquisition Layer Pattern
The reference architecture for a VP-level read of external healthcare data is three layers, in order:
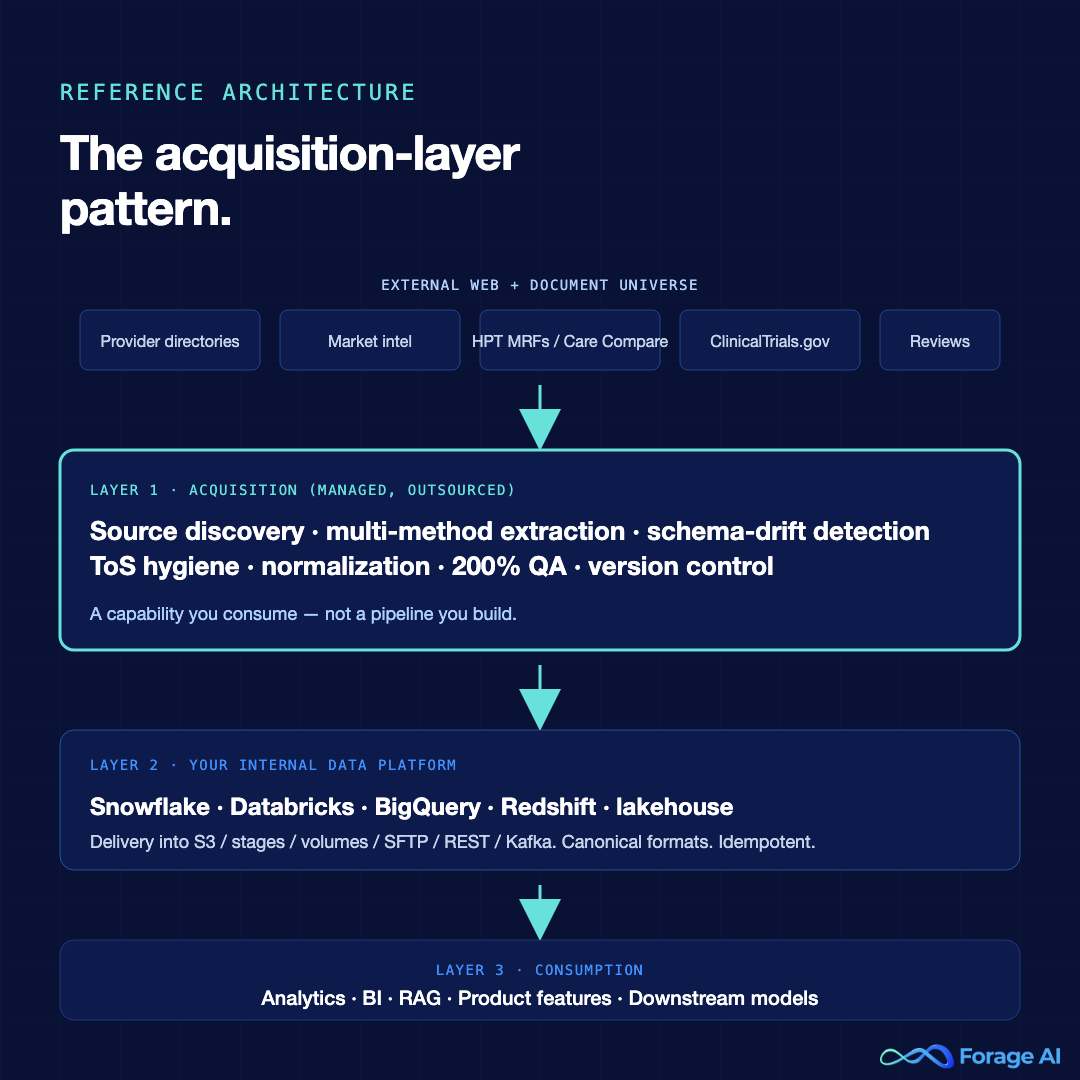
- Acquisition layer. Owns source discovery, extraction, schema-drift detection, ToS hygiene, raw normalization, and QA. This is the outsourced or partner-run capability. It is not a pipeline you build; it is a capability you consume.
- Internal data platform. Your existing Snowflake, Databricks, BigQuery, Redshift, or lakehouse. The acquisition layer delivers into it via the formats and cadences your platform already knows how to ingest.
- Consumption. Analytics, BI, RAG, product features, and downstream models — the healthcare data analytics layer where external signals finally turn into decisions. Owned by the internal teams who were hired to do exactly this work, not break-fix scraping.
The acquisition layer does the work that an internal team cannot sustainably absorb at scale:
- 24/7 monitoring across thousands of sources with alerting on drift, not on schema-validation pass/fail alone
- Multi-method extraction — XPath, NLP, and custom-trained ML in parallel, so a single method failing does not break the source
- 200% quality assurance — automated checks plus human-expert review on every delivery
- Source discovery — identifying new external data sources as your organization’s needs evolve
- Version control on every URL, every schema, every refresh
- Webhook + diff on every delivery so downstream consumers know exactly what changed
A capable acquisition layer integrates with your existing infrastructure rather than replacing any of it. Delivery into S3, Snowflake stages, Databricks volumes, SFTP, REST, or Kafka. Canonical formats. Idempotent refreshes. Lineage metadata attached to every record. The internal data platform is unchanged; what changes is who owns the painful upstream half.
This is the architectural answer to the Scale Wall.
Governance: What Has to Be in Writing Before Any External Data Lands
Architecture without governance is technical debt with a timeline. For any external healthcare data to enter the organization with audit defensibility, six artifacts have to exist in writing:

- Source catalog. Every URL or file the organization ingests, the refresh cadence, the data owner, the downstream consumer, and the legal basis (public, BAA-covered, contractual).
- Lineage map. Every downstream system, dashboard, model, and product feature that touches the source. When a source breaks or changes, lineage is the impact report.
- Compliance review. Terms of service captured for every source, PHI versus non-PHI classification, BAA references where required, and a refresh cadence on the review itself (sources change their terms; reviews go stale).
- SLA and escalation. What happens when a source breaks? Who owns recovery? What is the acceptable downtime? Whether the organization treats the source as Tier 1 (production-critical), Tier 2 (operational), or Tier 3 (advisory).
- Data ownership and sovereignty. Explicit confirmation that the client owns all extracted data, that data is not resold or aggregated across clients, and that no third-party LLM is being trained on the data without explicit consent. This is non-negotiable in a healthcare context.
- Audit log retention. The minimum is whatever regulatory environment your organization sits in (HIPAA-covered? state-specific? trial-related?). The practical minimum is a 7-year rolling log on every external ingestion.
The governance artifacts are the deliverable that lets a VP of Data answer a Chief Compliance Officer’s question on a Wednesday without panic. Without them, every external source is a quiet audit risk.
How Forage AI Fits: External Data Acquisition Layer for Healthcare
Forage AI is the managed external data-acquisition layer for healthcare organizations that have already built internal data infrastructure and are hitting the Scale Wall in the external bucket. We are not a tool. We are not an EHR vendor. We do not build your internal data pipelines — those are yours and they are working.
What we run, end-to-end, on your behalf:
- Provider directory monitoring at hospital-network and payer-network scale, with affiliation graph maintenance and freshness telemetry
- Competitive market intelligence — service-line monitoring, M&A signals, hiring patterns, capability launches across competitor sets you define
- Regulatory and transparency feed acquisition — HPT MRFs, Care Compare, HCRIS, No Surprises Act directories, monitored continuously with version control
- Clinical adjacency signals — ClinicalTrials.gov, public formularies, hospital service-line pages, public quality reports
- Patient-experience signals — public reviews, complaints, sentiment, non-PHI by design
What we operate behind it: 12+ years of healthcare-adjacent data automation, a 100-plus team of data engineers and QA specialists, a QA function sized at three times the industry average relative to delivery, multi-method extraction (XPath, NLP, custom-trained ML), and reinforcement learning from human feedback baked into every pipeline. Across the company, we have crawled 500M+ websites, parsed 10M+ documents, and monitored 5M+ professionals.
The HIPAA posture in plain terms: external public data is non-PHI by default. BAA coverage is available where partner-shared data is in scope. On-premises delivery is available when your policy requires the data to remain within your own infrastructure. Your data is yours — not resold, not aggregated, not used to retrain third-party large language models.
The outcome: your internal team stops running break-fix on volatile public sources. They have started shipping the work analytics, RAG, and the product requested last quarter. The acquisition layer runs, and stays running, with you — not for one quarter, forever.

Talk to a healthcare data automation expert when you are ready to scope the layer.
Frequently Asked Questions
Is “healthcare data management” the same as EHR data management?
No. EHR data management is the discipline of running internal clinical systems — HL7, FHIR, USCDI v3, HIPAA-bounded PHI. Healthcare data management at the VP level covers three buckets: internal clinical, claims, transactional, and external. This article focuses on the external bucket because it is most likely to be under-architected in organizations with mature EHR programs.
Does HIPAA apply if the data is public?
Generally no. HIPAA at 45 CFR §160 and §164 governs PHI handled by covered entities and business associates. Public sources — NPPES, HPT MRFs, Care Compare, ClinicalTrials.gov, formularies, public reviews — sit outside that boundary because they are not PHI. The boundary returns when the acquisition layer touches partner-shared rosters from a covered entity, or when external data joins internal patient identifiers downstream.
Should I build provider directory monitoring in-house?
Almost never, if it is your only external source. Provider directories are high-volatility, high-volume, and have a 5% per-month churn rate. A single internal team typically saturates at three external sources before maintenance dominates. Directories are usually the source that should sit in a managed acquisition layer with your team handling the affiliation modeling on top.
How is this different from a Provider Data Management (PDM) platform?
A PDM platform is a destination — it stores, normalizes, and distributes provider data inside a health plan or system. An acquisition layer is the upstream capability that feeds it. The two are complementary. If you operate a PDM platform internally, the acquisition layer hands you clean, monitored, version-controlled provider data on the cadence your platform expects.
Can a managed acquisition layer integrate with our existing Snowflake or Databricks lake?
Yes. Delivery into S3, Snowflake stages, Databricks volumes, SFTP, REST, Kafka, or webhook is standard. The acquisition layer is in canonical format and idempotent on refresh, with lineage metadata attached to every record. Your internal data platform does not change; what changes is who owns the volatile upstream work.
Conclusion
External healthcare data is its own operational discipline. The Scale Wall is not a sign that your internal team is under-resourced — it is a sign that the work in front of them was never the work they were hired for. The architectural answer is an acquisition layer that sits alongside your internal data platform, owned by a partner whose entire operational practice is built around volatile public sources, governance defensibility, and HIPAA-aware delivery.
The VP-altitude move is to stop debating per-source builds and start architecting the portfolio: three buckets, five external domains, a managed-acquisition layer for the volatile work, and clean governance for every artifact. That is what makes healthcare data management actually run.
Related Articles
- Healthcare Data Extraction: How Health Data Teams Automate Provider, Claims, and Clinical Data — the companion tactical deep dive on the seven hospital data sources
- Build vs. Buy: Web Data Extraction — the decision framework behind any external data acquisition portfolio
- Data Observability for Extraction Pipelines — the monitoring layer that keeps any acquisition strategy honest
- Firmographic Data — how provider and practice firmographics fit a healthcare data portfolio
- Data Extraction Automation — automation patterns that apply across verticals
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




