

Zyte is one of the best scraping APIs you can buy. It also has a habit of handing you an invoice that looks nothing like your estimate. If you have ever watched a crawl quietly switch a domain into premium-proxy territory mid-run, you already know the feeling, and you are probably here looking for somewhere to land.
The frustration is rarely about quality. Zyte clears anti-bot defenses that other tools choke on, and it bundles AI extraction into a single call so you skip per-site parsing. The trouble starts when the pricing turns unpredictable, when there is no spending cap to catch a runaway job, and when you remember that the API still leaves you holding the pipeline, the QA, and the 2 a.m. maintenance. Those are different problems, and they point to different replacements.
So this is not a generic “best scraping tools” roundup. There are six kinds of Zyte alternatives worth weighing, and each one fixes a specific limit Zyte runs into. We will name the limit, then name the tools that answer it, grounded in what real users report rather than what vendors claim.
Quick Digest
- Why teams leave Zyte: the anti-bot success and bundled AI extraction are excellent, but pay-as-you-go pricing swings from $0.13 to $16.08 per 1,000 requests with no spending cap, and you still own the pipeline.
- Managed / done-for-you: Forage AI is the top pick when you want the data delivered to your schema, not another API to operate and maintain.
- Enterprise proxy + API: Oxylabs and Bright Data match Zyte’s scale and anti-bot depth when cost on hard targets is the issue, not capability.
- AI-native extraction: Firecrawl, Apify, and ScrapeGraphAI return LLM-ready output for teams building agents and RAG pipelines.
- Flat-rate / predictable pricing: Scrape.do, ScraperAPI, Crawlbase, and Decodo trade Zyte’s variable bill for pricing you can forecast.
- No-code: Octoparse covers teams without engineers through a point-and-click builder.
- Open-source / DIY: Scrapy, which Zyte itself maintains, gives full control at zero license cost if you have the engineering hours.
- How to choose: match the replacement to your real constraint, price predictability, anti-bot strength, AI-readiness, team capacity, or data ownership, before you migrate.
Why teams use Zyte, and where it cracks
Zyte earns its reputation. In independent benchmarking it has posted the highest overall success rate among scraping APIs, clearing 90% and often 97% on protected targets, which is the top of the field. Its Zyte API folds proxy management, browser rendering, and AI-driven extraction into one request, so you get structured data back without writing selectors for every site. And the company maintains Scrapy, the open-source framework a large share of Python scraping teams already run, which buys real credibility.
The cracks show up at scale, and they are mostly commercial rather than technical.
Pricing is the recurring complaint. Zyte bills per successful response, but the rate depends on what the target needs, HTTP-only or full browser rendering. That spread runs from roughly $0.13 to $16.08 per 1,000 requests, and you do not know which tier a site lands in until you start scraping it. One Capterra reviewer reported waking to a bill around 40 times the estimate, because pay-as-you-go has no hard spending cap.
The second crack is ownership. An API gives you capability, not an outcome. Your team still builds the crawl logic, validates the data, and fixes the pipeline when a source changes. For a lot of operators, that maintenance load, not the per-request price, is the real cost.
That matters more every year. Bad bots now make up 40% of all internet traffic as of the 2025 measurement, the seventh straight year of growth, which means targets keep hardening and the maintenance never ends. As one 2026 bot-traffic report put it, “the challenge is no longer identifying bots. It’s understanding what the bot, agent, or automation is doing.”
We curated every option below against one of these cracks, so you are not trading Zyte’s problems for a fresh set.
Expert Insights
In production scraping, the bill is the failure mode nobody designs for. A crawl that silently escalates a target into browser-rendering tiers can multiply spend overnight, and without a spending cap there is no circuit breaker. Treat predictable cost as a reliability requirement, not a finance afterthought. The same discipline you apply to retry logic belongs on your billing model.
Quick Summary
Q: Why do teams look for a Zyte alternative if it performs so well?
A: Performance is rarely the reason. Teams leave over unpredictable pay-as-you-go pricing that can swing 100x per 1,000 requests with no spending cap, and over the fact that the API still leaves the pipeline, QA, and maintenance on their plate. Both are solvable, but by different kinds of replacement.
Zyte alternatives at a glance
Here is the full roster, what each one is best for, and the specific Zyte limit it answers. Providers come first; the decision framework comes after.
| Provider | Category | Pricing model | Best for / the Zyte limit it fixes |
|---|---|---|---|
| Forage AI | Managed | Scoped engagement | You want data delivered, not a pipeline to run |
| Oxylabs | Enterprise proxy + API | Per GB / subscription | Scale and anti-bot depth without cost spikes |
| Bright Data | Enterprise proxy + API | Pay per request | Largest proxy network, flexible billing |
| Firecrawl | AI-native | Flat per-scrape credit | LLM-ready output for agents and RAG |
| Apify | AI-native / marketplace | Per-actor / compute | A ready-made scraper already exists |
| ScrapeGraphAI | AI-native | Usage-based | LLM-driven extraction in code |
| Scrape.do | Flat-rate API | Per-request credits | Predictable price plus speed |
| ScraperAPI | Flat-rate API | Tiered credits | Simple, cheaper high-volume scraping |
| Crawlbase | Flat-rate API | Pay-per-success | Billing transparency, no bill shock |
| Decodo | Flat-rate API | Per-GB / per-1k | Best price-to-performance |
| Octoparse | No-code | Subscription tiers | Teams without engineers |
| Scrapy | Open-source | Free | Full control, no per-request cost |
How the Zyte alternatives compare
The roster above tells you who is on the list; this table tells you how they differ on the axes that actually decide a switch. Ratings are public review scores as of June 2026.
| Provider | Anti-bot strength | Pricing predictability | AI / LLM-ready | Free tier | Rating (June 2026) |
|---|---|---|---|---|---|
| Forage AI | High (managed, multi-method) | High (scoped, no per-1k) | Yes (AI + human) | No (managed service) | Service, not self-serve |
| Oxylabs | Very high (99.95% reported) | Medium (per-GB) | Yes (Scraper API) | Trial | G2 4.5 / TP 4.7 |
| Bright Data | Very high (150M+ IPs) | Medium (per-request) | Yes (120+ scrapers) | Trial | G2 4.6 |
| Firecrawl | Moderate | Medium (credit modifiers) | Native (markdown, MCP) | Yes (500 credits) | Strong dev sentiment |
| Apify | Varies by actor | Medium (compute-based) | Yes (LLM integrations) | Yes | G2 4.7 |
| ScrapeGraphAI | Moderate | Medium (usage-based) | Native (LLM extraction) | Yes | Early-stage |
| Scrape.do | High (110M proxies) | High (per-request) | Structured output | Yes | G2 4.6 |
| ScraperAPI | Solid on common targets | Medium (5-25x multipliers) | Structured endpoints | Yes (1K/mo) | G2 4.4 / TP 4.5 |
| Crawlbase | Good (weaker on hardest) | High (pay-per-success) | Structured endpoints | Yes | Solid, niche |
| Decodo | High (99.86% reported) | High (per-1k, drops at volume) | Limited parsers | Yes | G2 ~4.6, “Best Value” |
| Octoparse | Moderate | Medium (credits expire) | AI auto-detect | Yes (10 crawlers) | Liked by non-devs |
| Scrapy | DIY (you build it) | High (free) | Whatever you wire in | Free / open-source | Mature, huge ecosystem |

Quick Summary
Q: What is the single best Zyte alternative?
A: There isn’t one, and any list that names a universal winner is selling something. The right pick depends on your constraint: Forage AI if you want the pipeline off your plate, Oxylabs or Bright Data for enterprise proxy scale, Firecrawl for AI workflows, and Scrape.do or Decodo for predictable pricing.
The alternatives, by category

Forage AI
This is the category most Zyte users overlook, because Zyte trained them to think in API calls. The question is not which API to operate next. It is whether you should be operating one at all.
| Best for | Teams that want delivered data, not infrastructure |
| Pricing model | Scoped engagement, no per-1k surprise |
| Anti-bot | Handled for you (managed, multi-method) |
| AI / LLM | AI plus human-in-the-loop extraction |
| Standout | End-to-end ownership: discovery to delivery |
| Watch-out vs Zyte | A managed service, not a self-serve API |
Forage AI is the right move when the maintenance, not the request price, is what’s killing you. Where Zyte hands you a capability, Forage owns the whole lifecycle: source discovery, crawling, extraction, QA, and delivery in the schema and format you specify. The QA layer matters here, it runs roughly three times the size of a typical delivery team relative to headcount, with automated checks and human validation on every extraction, which is the part a raw API leaves to you.
Two things separate it from everything else on this list. Your data stays yours. Forage never resells it, which is not something proxy platforms can always say. And pricing is scoped to the project rather than metered per request, so the 40x-bill scenario cannot happen. The honest trade-off: this is a partnership model, not a self-serve dashboard you can build in an afternoon. If you want to keep your hands on the crawl, pick an API below. If you want the data to arrive, this is the category.
Better than Zyte when you would rather own the data than operate the pipeline.

Quick Summary
Q: When does a managed service beat a scraping API like Zyte?
A: When your bottleneck is engineering time, not extraction capability. A managed provider like Forage AI absorbs the pipeline, QA, and maintenance and delivers data to your schema, which is the work an API leaves on your team. If you have the engineers and want control, an API still wins.
Expert Insights
The build-versus-buy line moves the moment maintenance becomes a standing cost. We have seen teams spend 40-plus engineering hours a month keeping scrapers alive, rotating proxies, patching selectors, chasing anti-bot changes. That is the exact work a managed model removes, and it rarely shows up in the per-request price comparison that sends people to an API in the first place.
Oxylabs
When the problem is that Zyte gets expensive on hard targets rather than failing on them, a like-for-like enterprise provider is the cleaner swap.
| Best for | Large-scale, reliability-critical extraction |
| Pricing model | Bandwidth (per GB) and subscription |
| Anti-bot | Strong; 99.95% reported success |
| AI / LLM | Web Scraper API with structured output |
| Standout | Proxy depth and consistency at scale |
| Watch-out vs Zyte | Per-GB billing punishes many small pages |
Oxylabs reports a 99.95% average success rate with sub-second response times, and carries a 4.5-star G2 rating across 414-plus reviews plus a 4.7 on Trustpilot from a much larger pool. The pricing wrinkle is the mirror image of Zyte’s: bandwidth-based billing rewards large pages and gets expensive when you pull millions of tiny ones.
What users say: reviewers single out exemplary customer support and reliable IP quality, with one calling it “super easy to set up and integrate.” The recurring complaints are price (“quite expensive, but you appreciate the quality”) and a setup involved enough that some lean on support to get going.
Better than Zyte when you need comparable enterprise scale and want to escape per-request tier roulette.
Bright Data
| Best for | Widest proxy coverage, irregular workloads |
| Pricing model | Pay per request, no commitment |
| Anti-bot | Strong; 150M+ IP pool |
| AI / LLM | 120+ pre-built scrapers, structured feeds |
| Standout | Largest network, flexible billing |
| Watch-out vs Zyte | Sprawling product surface, learning curve |
Bright Data runs one of the largest proxy networks in the market, with 150 million-plus IPs, 120-plus pre-built scrapers, and pay-by-request billing that suits prototyping and bursty jobs. It holds a 4.6-star G2 average rating based on 323+ reviews.
What users say: reviewers praise easy implementation and responsive, clear support. The consistent gripe is cost on high-traffic projects, plus tooling that occasionally needs custom work to fit a specific use case.
Better than Zyte when you want maximum proxy reach with per-request flexibility instead of opaque tiering.
Quick Summary
Q: Are enterprise proxy providers actually cheaper than Zyte?
A: Not automatically. They remove Zyte’s per-tier unpredictability, but they introduce their own model, per-GB for Oxylabs, per-request for Bright Data. They win when your spend is unpredictable because of Zyte’s tiering, not when raw volume is the cost driver.
Expert Insights
Switching between metered providers is mostly a billing-model decision dressed up as a performance one. Per-request, per-GB, and per-success each reward a different traffic shape. Profile your real workload, page size, request volume, render ratio, before you assume the new tool is cheaper. The benchmark that matters is your own crawl, not the vendor’s.
Firecrawl
If you are scraping to feed a model rather than a database, this category exists for you, and it is where the “AI web scraping” conversation is genuinely moving. Our deep dive into the best AI web scraping tools walks through the leading options in this group and what AI actually changes about each.
| Best for | Agents, RAG, LLM-ready markdown |
| Pricing model | Flat 1 credit per successful scrape |
| Anti-bot | Moderate; weaker on the hardest targets |
| AI / LLM | Native; autonomous extract, MCP support |
| Standout | URL in, clean markdown out |
| Watch-out vs Zyte | Real credit cost can run 5-9x nominal |
Firecrawl was built for AI workflows: send a URL, get back clean markdown ready to drop into an LLM, with an autonomous extract mode and MCP integration that Zyte does not match. Pricing is a flat rate of 1 credit per successful scrape, which reads more simply than Zyte’s tiers.
What users say: developers report switching from other tools because it “benchmarked 50x faster” for agent workflows, and they love the clean markdown. The repeated complaints are that credits “add up fast” once you enable JSON and enhanced mode (effective cost climbs to 5-9x nominal), and that there is no built-in scheduling.
Better than Zyte when: your output target is a model, not a warehouse, and you want markdown over raw HTML.
Apify
| Best for | Reusing a pre-built scraper |
| Pricing model | Per-actor compute and usage |
| Anti-bot | Varies by actor |
| AI / LLM | LLM integrations, 35,000+ actors |
| Standout | Marketplace of ready-made scrapers |
| Watch-out vs Zyte | Community-actor quality is uneven |
Apify’s marketplace holds 35,000-plus ready-to-run “actors” plus support for Playwright, Puppeteer, Scrapy, and Crawlee, and it carries a 4.7-star G2 rating across 455-plus reviews, the highest volume in this set.
What users say: reviewers love that the Actor marketplace lets them scrape sites like Instagram or Google Maps “in minutes without building anything,” and data teams with complex needs gravitate to it. The flip side is that they flag uneven quality across community-built actors, so benchmark results swing depending on which one you run, which is the usual reason teams end up comparing Apify against managed and API alternatives.
Better than Zyte when someone has already built and maintained the exact scraper you need.
ScrapeGraphAI
ScrapeGraphAI rounds out the AI-native group with LLM-driven extraction you wire into code, useful when you want the model to interpret structure rather than maintain selectors. What users say: it is younger and thinner on third-party reviews, so early adopters treat it as a pilot-stage, they like LLM-interpreted extraction, but test on their real targets before committing volume.
Better than Zyte when you want LLM-interpreted extraction inside your own application logic.
Quick Summary
Q: What’s the best AI web scraping alternative to Zyte?
A: For AI-first workflows, Firecrawl leads on LLM-ready markdown and autonomous extraction, with Apify strongest when a maintained scraper already exists. Zyte does bundle AI extraction, but these tools are built output-first for agents and RAG.
Expert Insights
AI-native scrapers shift the maintenance burden rather than removing it. You stop writing selectors and start managing prompt drift, schema validation, and the silent failure where a model returns plausible but wrong fields. The win is real for LLM pipelines, but budget for output validation. Clean-looking markdown is not the same as correct data.
Scrape.do
This category is the direct answer to Zyte’s single biggest weakness: a bill you cannot forecast.
| Best for | Predictable cost plus speed |
| Pricing model | Per-request credits |
| Anti-bot | Strong; large rotating proxy pool |
| AI / LLM | Structured output options |
| Standout | Fast response, transparent pricing |
| Watch-out vs Zyte | Smaller brand, lighter ecosystem |
Scrape.do rotates a 110 million-strong proxy pool across datacenter, residential, and mobile, with forecastable per-request pricing, you know the cost before the crawl, not after.
What users say: independent testers flag it as among the best price-to-performance in the field, one comparison clocked 98.61% success at roughly $0.60 per 1,000 requests, “a fraction of any other top-tier provider’s cost.” The trade-off reviewers note is a smaller brand and lighter ecosystem than the incumbents.
Better than Zyte when: budget predictability and speed matter more than ecosystem breadth.
ScraperAPI
| Best for | Simple high-volume scraping |
| Pricing model | Tiered credits |
| Anti-bot | Solid on common targets |
| AI / LLM | Structured endpoints |
| Standout | Clean docs, fast setup |
| Watch-out vs Zyte | Credit multipliers: ecommerce 5x, SERP 25x |
ScraperAPI is the lighter-weight swap, with a 4.4 on G2 and 4.5 on Trustpilot (93% five-star). It lacks Zyte’s deepest AI features, but is cheaper and simpler for high volume.
What users say: reviewers praise the clean documentation and note that it “handles proxies and CAPTCHAs seamlessly,” saving hours of debugging. The repeated complaint is that credit costs are climbing with premium parameters, e-commerce targets cost 5x, and search engines cost 25x, so “flat” deserves a second read.
Better than Zyte when: you want straightforward, cheaper volume scraping with readable pricing.
Crawlbase
| Best for | Billing transparency, no surprises |
| Pricing model | Pay-per-success |
| Anti-bot | Good on common, weaker on hardest |
| AI / LLM | Structured scraping endpoints |
| Standout | Charged only when a request returns data |
| Watch-out vs Zyte | Not competitive on the toughest targets |
Crawlbase bills pay-per-success; you are charged only when a request actually returns data, with 99.9% uptime and round-the-clock support. That model is the cleanest antidote to Zyte’s bill-shock problem.
What users say: reviewers like the pay-per-success billing and dedicated endpoints for tricky targets, and rate support highly. The honest limit they note is that it falls behind the strongest providers on the most aggressively protected sites.
Better than Zyte when: transparency and success-only billing matter more than winning the hardest 7% of targets.
Decodo
| Best for | Price-to-performance |
| Pricing model | Per-GB / per-1k, drops at volume |
| Anti-bot | Strong; 99.86% reported success |
| AI / LLM | Limited dedicated parsers |
| Standout | Named “Best Value” five years running |
| Watch-out vs Zyte | Fewer ready-made parsers outside core targets |
Decodo, the rebrand of Smartproxy, has been named “Best Value” by an independent benchmarker for five consecutive years, with 115 million-plus IPs, a reported 99.86% success rate, and per-1k pricing that dips below $0.10 at high volume.
What users say: reviewers highlight exceptional proxy quality, high success, and minimal downtime, with pricing seen as fair and a free entry tier that appeals to smaller teams. The gap versus Zyte is parser breadth; outside of e-commerce and search, you write more of the parsing yourself.
Better than Zyte when you want the strongest price-to-performance and can handle some parsing.
ScrapingBee and ZenRows also sit in this band, both strong on anti-bot bypass for common protections, and worth a look if the four above do not fit.
Quick Summary
Q: Do flat-rate APIs fix Zyte’s pricing problem?
A: Mostly, with one caveat. They make spend forecastable by charging per request or per success instead of by site difficulty, which removes the bill-shock risk. The caveat is credit multipliers, some providers quietly charge 5-25x for ecommerce or search targets, so read the modifier table before you assume “flat” means flat.
Expert Insights
Predictable pricing is worth a few points of success rate for most teams. A provider that wins 92% of targets at a cost you can forecast beats one that wins 97% at a cost you discover after the invoice. The exception is the small set of must-have, heavily defended sources, where you pay for the top success rate because a missing record breaks the use case.
Octoparse
| Best for | Teams without engineers |
| Pricing model | Subscription tiers, free tier |
| Anti-bot | Moderate |
| AI / LLM | AI auto-detect for fields |
| Standout | Point-and-click, 500+ templates |
| Watch-out vs Zyte | Not built for high scale or speed |
If the real reason Zyte frustrates you is that it is API-only and your team does not write code, Octoparse is the category answer: a point-and-click builder with AI auto-detect, 500-plus templates, and a free tier covering up to 10 crawlers.
What users say: non-developers praise the point-and-click builder and template library for getting data flowing without code. Reviewers warn it is not built for high scale or speed, and that unused credits expire at the end of each billing cycle.
Better than Zyte when nobody on the team should have to touch an API.
Scrapy
| Best for | Full control, zero license cost |
| Pricing model | Free, open-source |
| Anti-bot | DIY, you build it |
| AI / LLM | Whatever you wire in |
| Standout | Mature framework, huge ecosystem |
| Watch-out vs Zyte | You own proxies, CAPTCHAs, fingerprints |
There is a quiet irony here: the strongest open-source Zyte alternative is Scrapy, which Zyte itself maintains. It is free, battle-tested, and endlessly extensible, and if you have the engineering hours, it gives total control with no per-request cost.
What users say: long-time users praise its maturity, plugin ecosystem, and ability to handle massive crawls. The universal caveat is the one this whole article circles: you own all the operational upkeep. By one hands-on estimate, managed infrastructure becomes cheaper than DIY “roughly when you start spending more than 5 hours a week on proxy rotation, CAPTCHA solving, and browser-fingerprint maintenance, and for most teams that hits within the first month at any real volume.”
Better than Zyte when you want full control and have the engineering capacity to run it.
How to choose without inheriting new problems
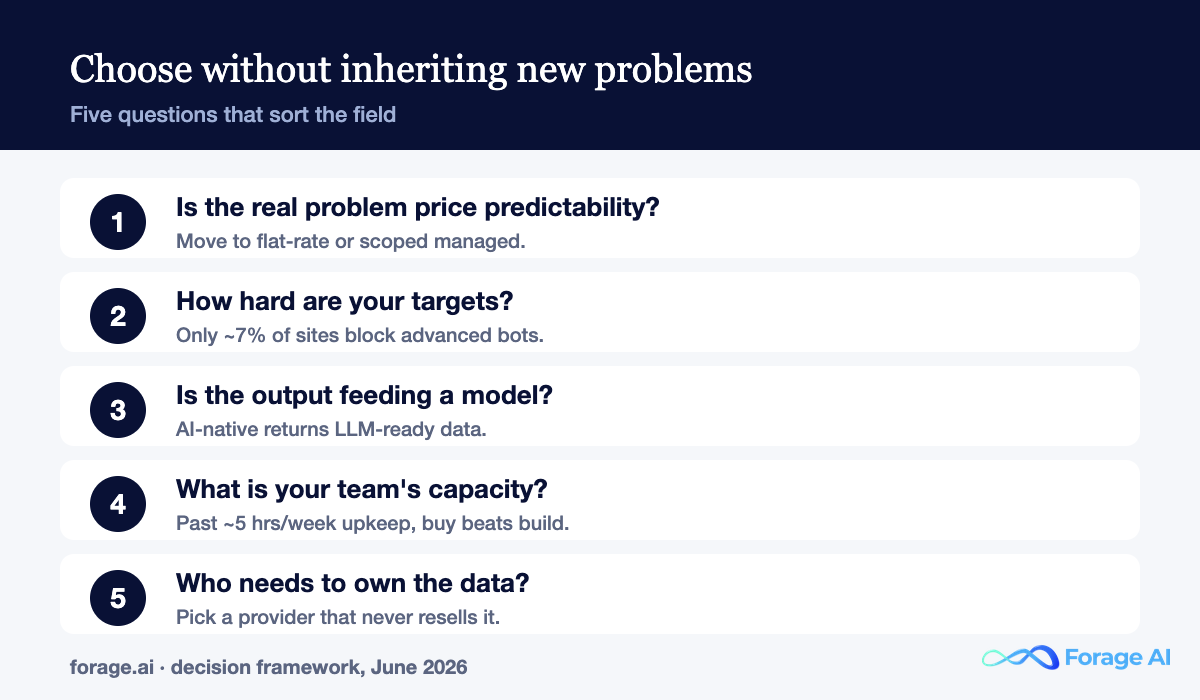
Choosing a Zyte replacement is where teams stumble. The fastest way to pick one badly is to chase the highest success rate on a benchmark. Start from your constraint instead. Five questions sort the field.
- Is the real problem price predictability? If finance cannot forecast your spend, move to flat-rate or pay-per-success (Scrape.do, Crawlbase, Decodo) or a scoped managed engagement. Raw success rate is not your issue.
- How hard are your targets? Only about 7% of websites block advanced anti-fingerprinting bots as of the 2025 measurement, so most teams do not need the absolute top-of-the-line anti-bot protection. If your must-have sources are in that 7%, pay for the strongest provider; otherwise, optimize for cost.
- Is the output feeding a model? If you are building agents or RAG, the AI-native group returns LLM-ready data directly, but budget for output validation.
- What is your team’s real capacity? Below the roughly five-hours-a-week maintenance line, DIY with Scrapy is fine. Above it, the math favors a fast, managed model.
- Who needs to own the data? If reuse, resale, or compliance is a concern, a managed provider that never resells your data clears a bar that shared proxy platforms cannot.
And the honest counter-case: sometimes Zyte is still the right call. If your workload is dominated by a handful of brutally defended sites where a missing record breaks the use case, Zyte’s top-of-field success rate can be worth the pricing volatility. The point is not that Zyte is bad. It is that “best anti-bot API” and “right tool for your operation” are different questions.
For the deeper build-versus-buy math, our guides on data extraction automation and on web scraping companies vs. tools work through the trade-offs.
Last updated June 2026. No vendor paid for placement in this comparison; rankings reflect public reviews, independent benchmarks, and fit against common Zyte limitations.
FAQ
What is the best free or open-source alternative to Zyte?
Scrapy is the strongest free option, maintained by Zyte itself, and it gives full control at no license cost if you have the engineering hours. Octoparse offers a no-code free tier of up to 10 crawlers for smaller, code-free jobs. Neither removes the operational work the way a paid managed service does.
Why is my Zyte bill so much higher than expected?
Zyte charges per successful response, and the rate depends on whether a site needs HTTP-only or full browser rendering, a spread from roughly $0.13 to $16.08 per 1,000 requests. Because pay-as-you-go has no spending cap, a crawl that escalates into premium tiers can produce a bill many times your estimate. Flat-rate and pay-per-success providers remove that risk.
How does Zyte compare to Bright Data and Apify?
Zyte leads on bundled anti-bot success and AI extraction in one call. Bright Data offers the largest proxy network with per-request billing, and Apify wins when a maintained, ready-made scraper already exists for your target. The right pick depends on whether your constraint is cost, proxy reach, or build speed.
Is there a Zyte alternative built specifically for AI workflows?
Yes. Firecrawl returns clean, LLM-ready markdown with autonomous extraction and MCP support, and ScrapeGraphAI offers LLM-driven extraction in code. Both are output-first for agents and RAG, with Zyte’s AI extraction as one feature within a general scraping API.
When should I move off a scraping API entirely?
When maintenance, not capability, is the cost. If your team spends more than about five hours a week on proxy rotation, CAPTCHA handling, and selector upkeep, a managed provider that delivers data to your schema usually costs less in total than the engineering time an API consumes.
Related Articles
- Custom Web Scraping: When Off-the-Shelf Tools Stop Scaling. The point where bespoke, managed extraction beats DIY tooling.
- Top Proxies for AI Data Extraction. Choosing and operating proxies when you run scrapers yourself.
- A Guide to Modern Data Extraction Services in 2026. How managed extraction fits into a wider data strategy.
- What Is Data as a Service (DaaS)?. The buying model behind done-for-you data delivery.
- Where you are on the data maturity curve
- Five roads that lead nowhere — and why each one breaks
- Three paths to data that scales, and what each one costs





