
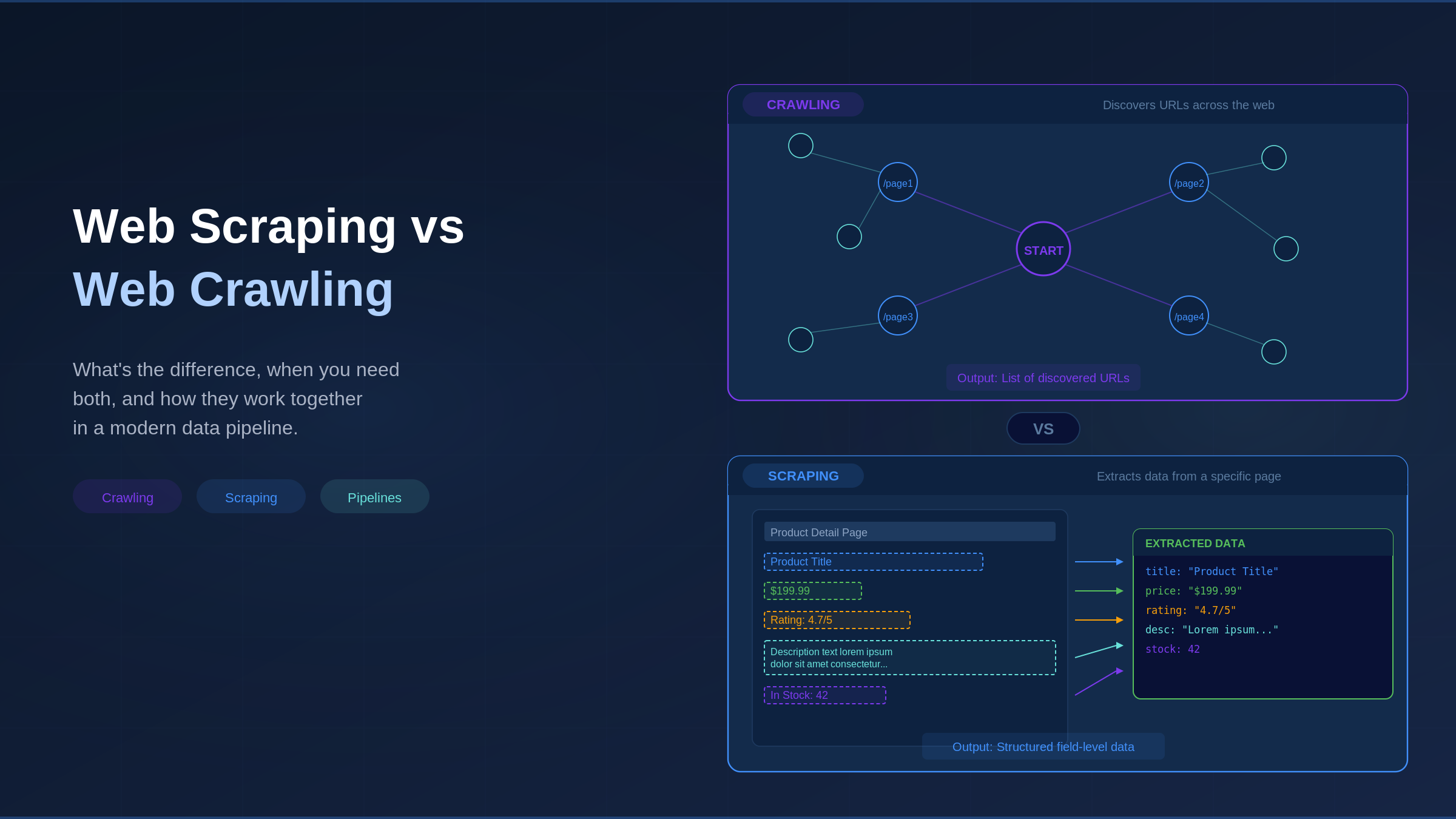
Imagine you are in a giant library with millions of books and no catalog, and you want a single ingredient list from one specific cookbook, but have no idea where to find it.
You must first walk the aisles and locate the right books. That is like web crawling. Once you find the right book, you open it to the recipe and copy down exactly what you need. That is like web scraping.
People use these terms interchangeably, but they do very different things, and mixing them up is one of the most common reasons data projects fail. The web scraping market reached $1.03 billion in 2025 and is on track to hit $2.00 billion by 2030, while 65% of enterprises used web scraping specifically for AI and machine learning projects in 2024. This is infrastructure that companies depend on.
This guide covers what each one does, how they differ, how they work together, and how to decide which one you need.
What Is Web Scraping and What Is Web Crawling?
The two terms sound similar, but each one does a different job. Here are the simplest definitions to start with.
Web Scraping: Targeted Data Extraction
Web scraping means pulling specific data from web pages, much like highlighting just the details you want and ignoring everything else.
A scraper loads a web page, reads its underlying code (called HTML), and extracts the fields you care about: prices, review scores, and stock levels. The result is structured data in a spreadsheet, database, or JSON file (a common data format).
To find the right data, scrapers use CSS selectors (rules that point to specific parts of a page, like “grab the price”), XPath (a way of navigating a page’s code structure), or AI models that understand plain-language instructions. For websites that load content on the fly, scrapers use headless browsers (browsers that run silently in the background) like Playwright or Selenium to load the page first.
In short, scrapers go deep, covering hundreds of pages and pulling many data points from each one.
Web Crawling: Automated URL Discovery
Web crawling finds and maps the addresses of web pages, known as URLs. A crawler starts with a handful of known addresses, visits each one, collects every link it finds, and then follows those links to discover new pages.
The result is a map of the web: a list of page addresses, a picture of how pages link to each other, or a searchable index. Common Crawl, the nonprofit behind the largest open web archive, has collected over 9.5 petabytes of crawl data, with its August 2025 crawl alone adding 2.42 billion pages. Googlebot’s crawl traffic grew 96% year over year in 2025.
Where scrapers go deep, crawlers go wide, covering millions of pages but collecting only addresses and basic metadata rather than the actual content on each page.
Why the Distinction Matters for Data Teams
Crawling produces the map, and scraping reads that map to extract what you need. When teams treat these as the same process, things break: scrapers without a crawling step miss pages entirely, while crawlers without a scraping step collect addresses but never retrieve the actual data behind them.
| Dimension | Web Scraping | Web Crawling |
| Purpose | Extract specific data fields | Discover and index URLs |
| Scope | Deep: targeted pages, many fields per page | Wide: many pages, minimal data per page |
| Output | Structured data (JSON, CSV, database rows) | URL lists, website graphs, content indexes |
| Page logic | Page-specific (CSS selectors, XPath) | Minimal (parse links, follow them) |
| Maintenance | Breaks when a page’s layout changes | Breaks when a website’s navigation changes |
| Typical tools | Playwright, Selenium, Beautiful Soup | Scrapy, Apache Nutch, custom crawlers |
| Example | Extract pricing from 500 product pages | Discover all product pages across 50 websites |
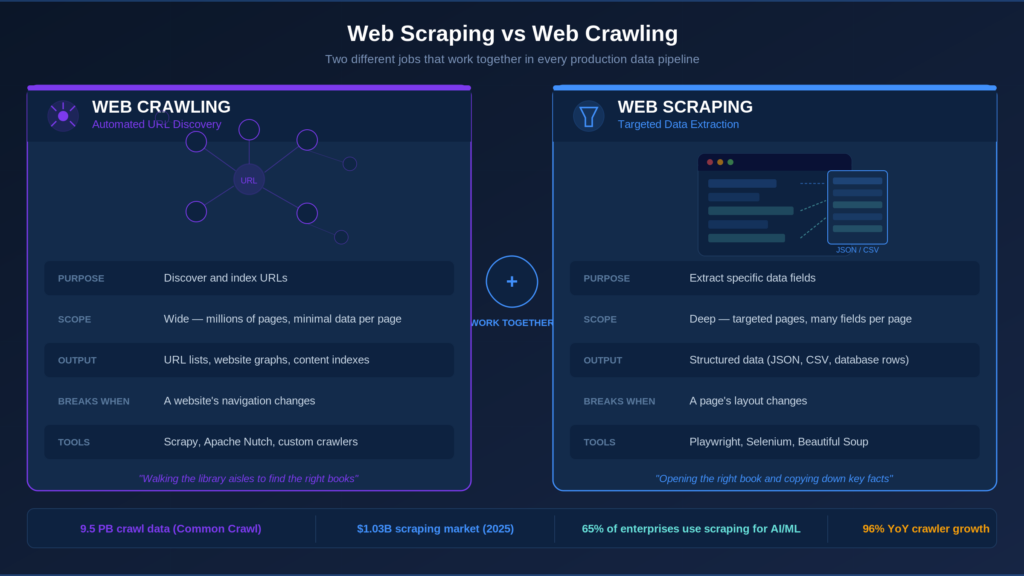
Key Differences Between Web Scraping and Web Crawling
The table above covers the basics, but the real differences go deeper, and understanding them helps you avoid the mistakes that slow most data teams down.
Scope and Depth: Wide Discovery vs Deep Extraction
Crawlers are relatively low-maintenance because they visit pages, read the links, and move on without caring about the page’s visual design. As long as the navigation links still work, the crawler keeps going.
Scrapers are more demanding. They need to know the exact layout of each page, so if a website changes even one section, a scraper that worked yesterday can break today. Industry data shows 10–15% of scrapers in some fields need weekly fixes, and engineers spend roughly 40% of their time dealing with broken feeds. That is two full working days per week lost to upkeep.
Infrastructure and Maintenance: Two Different Operational Profiles
When you are working across thousands of websites, crawling and scraping need their own separate systems. Think of it like this: the team that maps the roads is not the same team that delivers the packages.
Crawlers need: URL frontier management, de-duplication, politeness policies (rate limiting), robots.txt compliance (robots.txt is a file websites use to tell bots which pages to visit or avoid), proxy rotation, and scheduling.
Scrapers need: page-specific parsing logic, JavaScript rendering, anti-bot evasion, data validation, and constant selector updates when target websites change layout.
A tool like Scrapy can handle both on a small-to-medium scale, but at an enterprise scale, these become distinct infrastructure stacks that require different teams and different expertise.
| Expert Insight: A web crawler and a web spider are the same thing: both discover and traverse URLs. A web scraper extracts specific data from pages. The terminology overlap trips people up, but the engineering distinction is real. If someone says “spider,” they mean crawler. |
How Web Scraping and Web Crawling Work Together in a Data Pipeline
In most real data projects, you need both. The pattern is simple: crawl to find the pages, then scrape to pull the data from them.
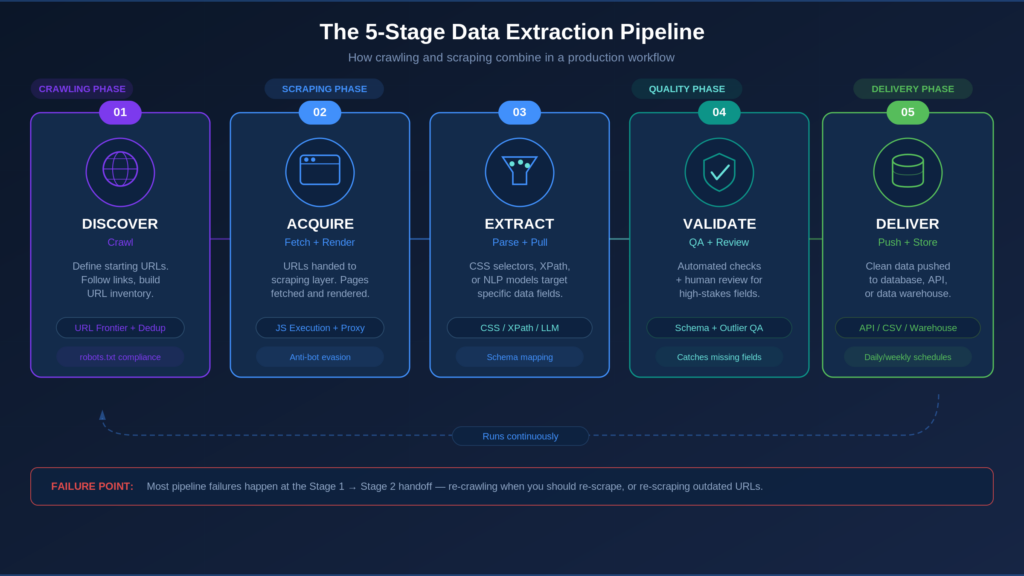
The 5-Stage Data Extraction Pipeline
A production pipeline runs in five stages that cycle continuously, each one feeding into the next.
Stage 1: Discover. Define starting URLs and crawl scope. The crawler visits target websites, follows links, and builds a URL inventory. De-duplication prevents repeat processing.
Stage 2: Acquire. Discovered URLs get handed to the scraping layer. Pages are fetched and rendered (including JavaScript execution for dynamic websites).
Stage 3: Extract. Scrapers apply parsing logic to each page using CSS selectors (rules that pinpoint specific elements on a page), XPath (a language for navigating a page’s underlying structure), or NLP (Natural Language Processing), where AI models interpret pages from plain-language descriptions rather than hard-coded rules.
Stage 4: Validate. Extracted data goes through automated quality checks and human review for high-stakes fields.
Stage 5: Deliver. Clean, structured data is pushed to your system, such as a database, a CSV file, an API (Application Programming Interface, a connection that lets software systems share data), or a data warehouse.
These stages run as a continuous loop. Re-crawl schedules keep URLs current. Scraper maintenance keeps extraction aligned with website changes.
To make this concrete, imagine you need competitor pricing from 50 e-commerce websites. Crawling first discovers all the relevant product pages, then scraping extracts the price, availability, and SKU data from each one. QA catches missing fields and outlier prices, and delivery pushes the structured data into your analytics platform daily.
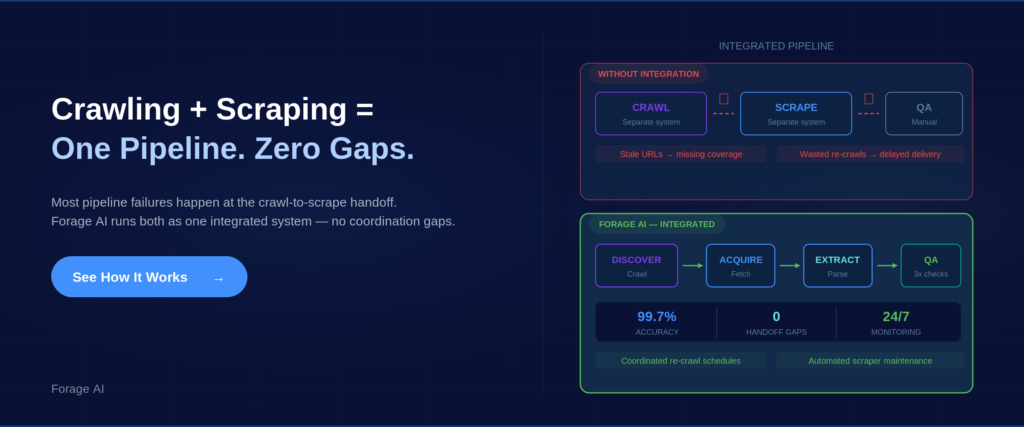
Where Pipelines Break: Handoff Failures Between Crawling and Scraping
Most failures happen at the point where crawling hands off to scraping, and the same two mistakes come up again and again.
Re-crawling when you should be re-scraping. The URLs have not changed, but the data on those pages has, so running a full crawl wastes resources and delays data freshness when simply re-scraping the existing URL set would do.
Re-scraping outdated pages because the crawler has not kept up. New pages exist but the crawler has not found them yet, so your scrapers are working from an incomplete list and you quietly lose coverage without any warning.
The teams that avoid these failures treat crawling and scraping as one integrated system with coordinated schedules.
What Enterprise-Scale Operations Actually Look Like
To put the scale in perspective, most enterprises run over 10,000 crawlers that process 10 billion products per day with 50 dedicated specialists. Tools like Scrapy combine crawling and scraping into a single framework, feeding cleaned data into storage systems such as BigQuery or Snowflake.
Managed data extraction partners like Forage AI handle the full pipeline from source discovery through delivery, eliminating the coordination failures that happen when crawling and scraping are managed separately.
| Quick Summary: Do I need both crawling and scraping? If your target URLs are unknown, change frequently, or span more than a handful of sources, yes. The crawl stage feeds the scrape stage. Skipping crawling means incomplete coverage. Combining them poorly means wasted compute and stale data. |
Do You Need a Web Crawler, a Web Scraper, or Both? A Decision Framework
The practical question is: what do you actually need, and should you build it yourself, buy a tool, or bring in outside help?
When Crawling Alone Is Enough
You need to map a website’s structure, monitor for new pages, or build an index, without extracting specific data fields. Examples: SEO audits, content freshness monitoring, and website migration planning. Over 80% of GPT-3’s training tokens came from Common Crawl, a pure crawl with no scraping.
When Scraping Alone Works
You have a known, stable set of URLs and need specific data fields extracted from them. Examples: Government databases with fixed URL structures, a known set of 200 product pages, and quarterly investor relations data.
81% of US retailers now use automated price scraping for dynamic repricing, up from 34% in 2020, and many target known product URLs that need no crawling layer at all.
When You Need Both (and Why Most Enterprise Teams Do)
You need structured data from a large or changing set of sources where URLs are not known in advance, which is the most common enterprise scenario. Examples: Competitor pricing across entire catalogs, professional directory monitoring, and market intelligence across hundreds of sources.
Financial services alone account for 30% of all web scraping spending, driven by demand for alternative data for trading, credit risk, and market intelligence. Nearly all of these operations require crawling before scraping can begin.
Scrape Decision Matrix
| Known, Stable URLs | Unknown or Dynamic URLs | |
| Small Scale (under 1,000 pages, monthly refresh) | Scrape only. A lightweight library like Beautiful Soup or a no-code tool will do the job. Minimal infrastructure needed. | Crawl + Scrape. Use a framework like Scrapy. One engineer can manage both layers at this scale. |
| Enterprise Scale (thousands of sources, millions of pages, weekly+ refresh) | Scrape only, but invest in monitoring. Stable URLs still need scraper maintenance as websites change their layouts. Anti-bot evasion becomes the main challenge. Consider a managed service if maintenance exceeds team capacity. | Crawl + Scrape + dedicated operations. This is a full pipeline problem. Crawl management, scraper maintenance, QA, and delivery all need dedicated resources. Build in-house only if data extraction is a core competency. Otherwise, a managed service is the more practical choice. |

Build, Buy a Tool, or Hire a Managed Service?
Small-scale scraping is a tool problem where a Python library and a scheduled job can handle it, but enterprise-scale crawling and scraping are operational problems that require dedicated infrastructure, QA, and ongoing maintenance.
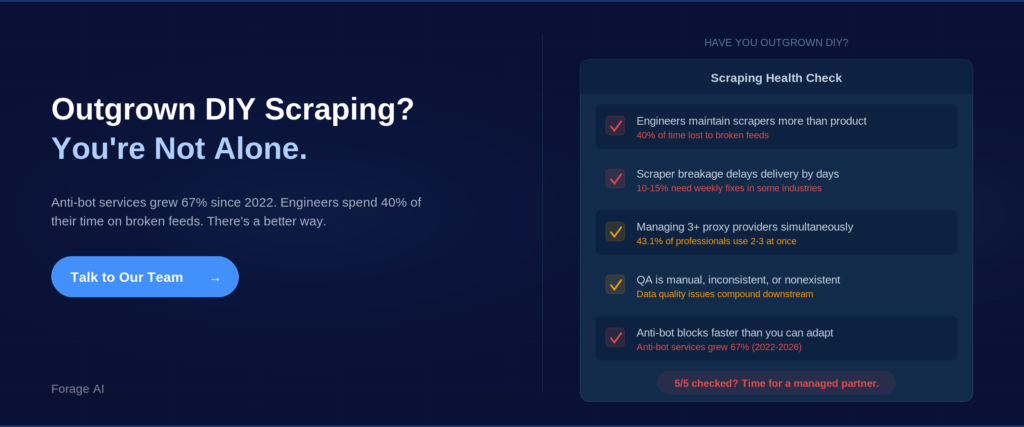
Signs you have outgrown DIY scraping:
- Engineers spend more time maintaining scrapers than building product features.
- Scraper breakage delays delivery by days, not hours
- You manage 3+ proxy providers (43.1% of professionals now use 2–3 simultaneously)
- QA is manual, inconsistent, or nonexistent.
- Anti-bot measures block you faster than you can adapt (anti-bot services grew 67% from 2022 to 2026)
A common mistake is buying a scraping tool when the real problem is not knowing which pages to scrape. If you do not know where your data lives, no scraper will help. You need to crawl first.
For teams that need both at scale, managed extraction partners like Forage AI own the full pipeline from source discovery to delivery, with QA teams 3x the industry average, so internal teams can focus on using the data rather than maintaining the infrastructure.
| Expert Insight: Should I build or buy? If data extraction is your core competency, build. If it supports your core product but is not the product itself, buy a tool for small scale or hire a managed service for enterprise scale. The dividing line is whether you can sustain the maintenance burden indefinitely. |
Legal and Compliance Considerations for Crawling and Scraping
The legal picture is more nuanced than the headlines suggest. Understanding a few key distinctions covers most of what data teams need to know.
How Legal Risk Differs for Crawling vs Scraping
Crawling open pages is generally accepted. The hiQ v. LinkedIn court ruling found that scraping publicly available data does not break the CFAA (the Computer Fraud and Abuse Act, a US law that covers unauthorized access to computer systems).
Scraping raises additional considerations, including what data you extract (personal data triggers GDPR, the EU’s General Data Protection Regulation, and CCPA, the California Consumer Privacy Act), how you access it (bypassing anti-bot measures may raise DMCA, or Digital Millennium Copyright Act, concerns), and whether the website’s terms of service prohibit it.
The Regulatory Landscape in 2026
France’s CNIL clarified in 2025 that GDPR applies to scraped personal data regardless of public accessibility, with fines up to 20 million EUR or 4% of annual global revenue. Reddit filed suit against Perplexity AI in late 2025 under Section 1201 of the DMCA, alleging that Perplexity AI circumvented anti-bot systems. The EU AI Act introduces new transparency requirements for training data sourced via scraping.
5 compliance practices for enterprise crawling and scraping:
- Respect robots.txt directives for all crawling operations
- Avoid scraping personal data without GDPR/CCPA safeguards in place.
- Do not circumvent access controls (CAPTCHA, authentication walls, rate limits)
- Document data provenance for audit trails
- Monitor evolving regulations, particularly the EU AI Act and DMCA case law.
The core principles are transparency, respect for boundaries, and recordkeeping. Organizations should consult legal counsel to evaluate their specific data collection practices and jurisdictional requirements.
How AI Is Changing Web Scraping and Crawling in 2026
With the fundamentals covered, it is worth looking at how artificial intelligence is changing both crawling and scraping right now.
LLM-Powered Extraction: Less Maintenance, New Trade-offs
Scrapers powered by LLMs (Large Language Models, the same technology behind ChatGPT) require approximately 70% less maintenance than traditional scrapers when websites change their design. Instead of brittle CSS selectors, users describe the desired data in plain language, and early results show accuracy up to 99.5% on dynamic, JavaScript-heavy websites. However, these AI scrapers still struggle with tabular data and can sometimes generate fields that look real but are not, especially when no quality checks are in place.
According to the 2026 State of Web Scraping survey, 54.2% of scraping professionals have not yet adopted AI. Among those who have, 72.7% report productivity gains. The technology works; the industry is catching up.
This hybrid approach, combining AI extraction with human quality assurance, is the model Forage AI uses across its managed data pipelines, with a QA team 3x the industry average to catch the edge cases models miss.
AI Crawlers Are Reshaping Web Traffic
GPTBot’s crawl traffic tripled between 2024 and 2025, and AI-focused crawlers as a group came close to matching Googlebot’s traffic volume for the first time. More bots mean stronger defenses: roughly half of all internet traffic now comes from bots, which is pushing websites to build detection systems that can block legitimate data collection, not just AI training crawlers.
AI is not eliminating the need for crawling and scraping expertise. It is shifting what that expertise looks like, because LLM extraction replaces brittle selectors on the scraping side while crawl infrastructure still requires traditional engineering skills.
| Expert Insight: Will AI replace traditional scraping? Not yet, and not entirely. AI reduces scraping maintenance significantly, but crawling still requires traditional engineering and AI extraction still needs human QA for production-grade accuracy. |
Frequently Asked Questions
What is the difference between a web crawler, a web spider, and a web scraper?
A web crawler and a web spider are the same thing: software that discovers and follows URLs. A web scraper extracts specific data from individual pages. The crawler finds pages; the scraper reads them.
Can you scrape data without crawling?
Yes, if you have a stable, known set of URLs. Government databases, curated product page lists, or investor relations pages with predictable URLs can all be scraped directly. For enterprise use cases where URLs are numerous or changing, crawling is needed first.
Is web scraping legal in 2026?
It depends on what you scrape, how you access it, and what jurisdiction applies. Scraping publicly available data is generally legal under US precedent (hiQ v. LinkedIn), but GDPR, DMCA, and the EU AI Act add complexity. Consult legal counsel for your specific use case.
What happens when you need both scraping and crawling at enterprise scale?
You need an integrated pipeline infrastructure: crawl management feeding into extraction logic, followed by QA and delivery. Scraper breakage rates alone (10–15% weekly in some industries) demand dedicated resources. Many enterprises choose managed extraction partners for this reason.
Do scraping services differ from web scraping tools?
Tools give you capabilities (APIs, libraries, proxy networks), but you maintain the pipeline. Services take full operational ownership of the entire process: crawling, extraction, QA, maintenance, and delivery.
The Real Question Is Not “Which One?” It is “Who Runs the Pipeline?”
Like the difference between walking the library aisles and copying from the right book, the crawling-vs-scraping distinction is not just academic. It is a pipeline architecture decision that determines how reliable your data operations will be.
The Crawl-Scrape Decision Matrix can help you figure out what you need, and the 5-Stage Pipeline shows how the pieces fit together. But the real question underneath both is simpler: can your team sustain the maintenance, quality assurance, and coordination burden of running both at scale, indefinitely?
As anti-bot defenses grow, AI reshapes extraction tooling, and regulations tighten, the case for managed end-to-end pipelines gets stronger. The question is not whether to invest in data extraction. It is whether to own that complexity internally or partner with a team that already has it.
Related Articles:
- News Crawler — Extract & Analyse Data for Insights
- Web Data Extraction — Techniques, Tools, and Applications
- Switch from Manual Web Scraping to Automated Web Scraping
- How AI Agents Solve Data Extraction Challenges
- Best AI Agent Solutions for Large-Scale Web Data Extraction
- Top Data Extraction Tools in 2026: A Modality-Segmented Buyer’s Guide




