

What is Enterprise Web Scraping and Why Does it Matter?
Enterprise-level web data extraction services goes beyond basic scraping tools. It enables organizations to reliably process millions of web pages each day. While simple scraping methods work for small projects, enterprise-level web scraping requires a larger infrastructure, support, and expert skill level.
High-volume web scraping involves gathering large amounts of data from multiple sources simultaneously, typically aiming to extract millions of web pages daily. This requires a strong infrastructure that can handle multiple requests, work with various data formats, circumvent advanced anti-bot technologies, have QA capabilities, and use advanced AI for data extraction.
Let’s review the top ten dependable web data extraction service providers for enterprises that fit the above criteria. We’ll evaluate their scalability, ease of integration, data accuracy, and impact on business strategies.
Quick Digest
The ten scalable web scraping services that consistently handle enterprise volumes, at a glance, each with what it is best for:
- Forage AI: best for custom, AI-driven, fully managed extraction at enterprise scale, with human-in-the-loop QA.
- Bright Data: best for high-volume, always-on pipelines that need the largest proxy network and ready-made datasets.
- Oxylabs: best for high-concurrency, low-latency scraping with AI-driven unblocking and global coverage.
- Zyte: best for compliance-sensitive, regulated industries that need data extraction with managed legal risk.
- Apify: best for developer teams that want customizable workflows and a large library of pre-built actors.
- ScraperAPI: best for teams that want a simple pay-per-successful-request scraping API without managing proxies.
- Nimble: best for data and engineering teams that want AI-structured web data delivered through purpose-built APIs.
- ZenRows: best for engineering teams scraping protected sites that need anti-bot bypass in a single API call.
- Decodo (formerly Smartproxy): best for teams that want strong proxy quality and a scraping API at an accessible entry price.
- Crawlbase: best for developers running high-volume standard scraping on a budget-friendly, usage-based plan.
How to Choose the Right Enterprise Web Scraping Service?
Before diving into specific providers, consider these critical factors when evaluating enterprise web scraping services:

- Scalability: Can the service handle your current and future volume requirements?
- Reliable Quality of Data: What uptime guarantees and success rates does the provider offer? And how accurate is the extracted data, and what validation processes exist?
- Compliance: Does the provider address legal considerations, such as GDPR and CCPA?
- Customization Capabilities: How easily does the service connect with your existing data infrastructure?
- Support: What level of technical assistance is available when issues arise?
- Experience – this means how efficiently you can provide data
Q: What is enterprise web scraping, and why does it matter?
A: Enterprise web scraping is high-volume web data extraction built to process millions of pages a day reliably, not the occasional small project a basic tool handles. It matters because it demands real infrastructure that can manage concurrent requests, handle many data formats, get past advanced anti-bot defenses, and run QA on the output. The right service judged on scalability, data quality, compliance, customization, and support turns raw web data into a dependable input for business decisions.
Expert Insights
The choice rarely comes down to a single feature. The five criteria above tend to trade against each other in practice. A provider built around a massive proxy pool will often win on raw scale and speed but ask more of your engineering team for custom work, while a managed, compliance-first service trades some flexibility for lower legal risk. The most useful question is not which provider is best overall, but which one matches your volume, your data complexity, and the regulations you operate under.
Top 10 Web Data Extraction Services for Enterprise-Level Scraping
1. Forage AI: For custom AI-powered scraping at a Large Scale for Enterprises
Forage AI is an experienced data provider in enterprise-level, custom AI-driven web scraping solutions. Over 500 million websites are frequently crawled, with data extraction accuracy of 99%. They enable businesses to scale and automate their data extraction pipelines using advanced technologies, such as AI Agents and Retrieval-Augmented Generation (RAG), for improved data processing.
| Attribute | Detail |
|---|---|
| Best for | Custom, fully managed AI-driven extraction at enterprise scale |
| Service model | Fully managed, done-for-you data pipeline |
| Scale / proxy pool | 500M+ websites crawled regularly; infrastructure scales to demand |
| Pricing model | Custom enterprise pricing by volume, complexity, and frequency |
| Compliance | Custom SLAs; structured, client-specific datasets |
| Standout strength | 99% accuracy with human-in-the-loop QA on unstructured data |
| Watch-out | Built for large-scale projects; less suited to small one-off needs |
Key Features:
- Custom AI Agents: Forage AI utilizes navigation and data collection agents and unstructured document extraction agents, which are tailored to each client’s specific needs.
- 99% Accuracy: The company boasts an impressive 99% accuracy in data extraction, especially for unstructured data (e.g., PDFs, images, and complex web structures)
- End-to-End Solution: Forage AI manages your complete data pipeline from crawling to integration, making it a one-stop shop for large-scale data extraction.
- HITL Quality Assurance and round-the-clock support: In addition to advanced AI, Forage AI uses a multi-step QA process to ensure the reliability and quality of the extracted data.
- Versatile Applications: The platform’s flexibility and rapid adaptability enable it to address virtually any data extraction need across various industries. Whether it’s e-commerce, finance, healthcare, media, or real estate, Forage AI’s infrastructure can scale to meet the specific demands of any sector.
Why choose Forage AI
For organizations that aim to extract large volumes of structured data from various sources to meet their specific needs, Forage AI proves to be especially advantageous. The company provides datasets that are structured and directly usable for clients’ purposes, ensuring that the data is meticulously curated to meet those specific needs efficiently.
Pricing Structure: Custom enterprise pricing based on volume, complexity, and data frequency requirements. Includes dedicated account management and custom SLAs.
Common Challenges: Implementation may require an initial consultation to customize extraction solutions for specific use cases, although this investment typically yields higher accuracy in the long term. It is ideal for large-scale projects but may be expensive for small-scale, limited data needs.
What reviewers say: Forage AI is positioned as a managed, white-glove service rather than a self-serve tool, so it carries fewer public G2 and Capterra entries than the proxy vendors. Where it is discussed, buyers point to the value of handing off the full pipeline and the consistency of the delivered datasets, with the main caveat being that it suits ongoing, higher-volume programs more than small one-time pulls.
Real-World Use Case: A major healthcare organization leveraged Forage AI to crawl over 1 million doctor profiles across 350,000 practices, reducing data collection time by 90% while significantly improving data quality and completeness.
2. Bright Data: The Speed Leader
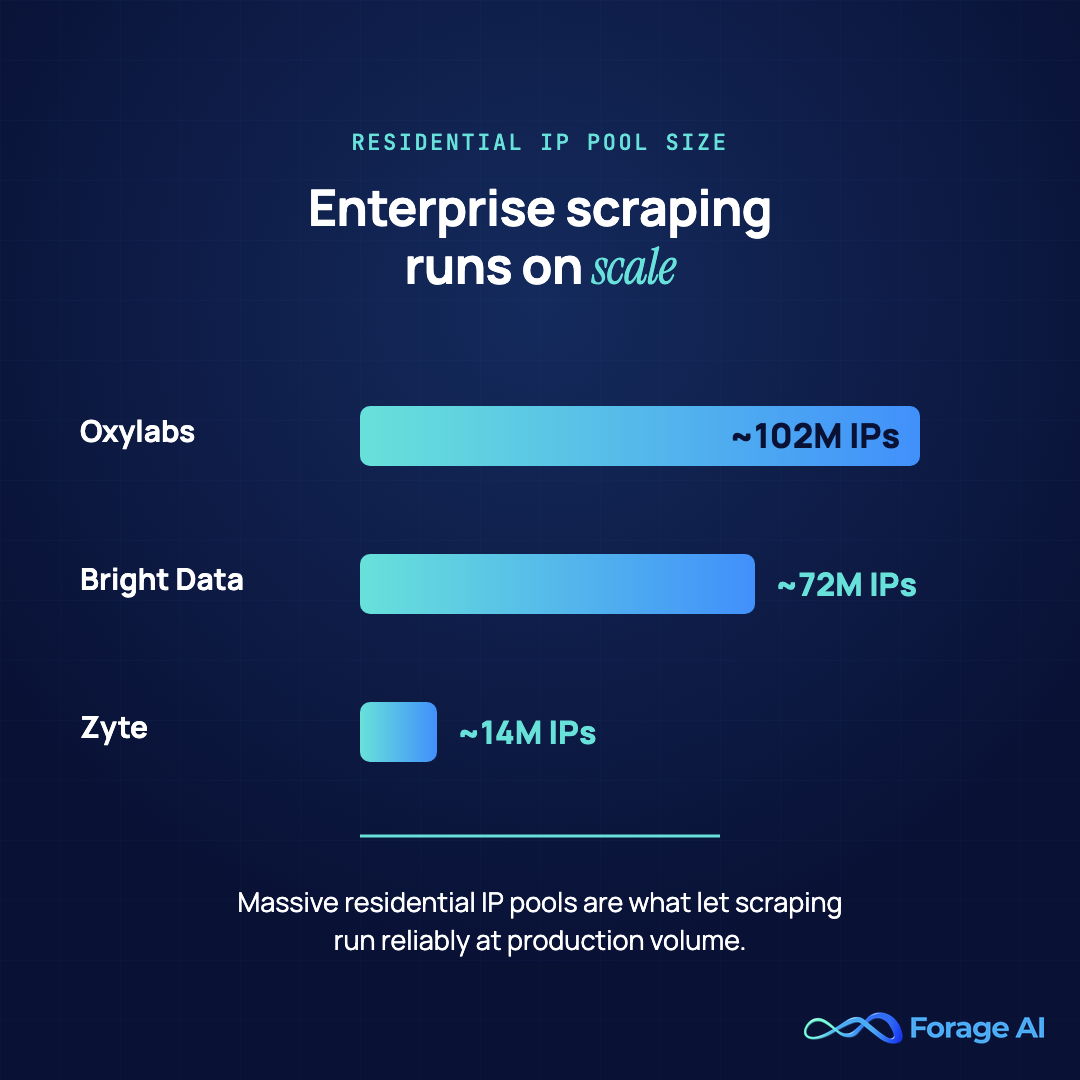
Bright Data (formerly Luminati) is one of the well-known players in the web scraping world, offering unparalleled scale and low-latency performance. Their vast proxy pool, including over 72 million IP addresses, ensures high availability and geographic diversity. Bright Data’s Datasets-as-a-Service provides turn-key solutions for businesses looking to bypass crawling altogether.
| Attribute | Detail |
|---|---|
| Best for | High-volume, always-on pipelines and ready-made datasets |
| Service model | Self-serve proxy network, scraping APIs, and datasets |
| Scale / proxy pool | 72M+ residential IPs with broad geographic coverage |
| Pricing model | Volume-based; pay-as-you-go and commitment tiers |
| Compliance | Public emphasis on ethical and compliant collection |
| Standout strength | Largest proxy network and Datasets-as-a-Service |
| Watch-out | Higher cost and a steeper learning curve for new teams |
Key Features:
- The company has access to 72 million residential IPs and offers large-scale data collection capabilities.
- As noted in the Proxyway Benchmark 2024, they report a global success rate of 98.96% and an average response time of 0.26 seconds.
- Additionally, their Datasets-as-a-Service allows businesses to subscribe to pre-collected datasets rather than having to build their own scraping infrastructure.
Why Enterprises Choose It
Bright Data’s infrastructure-first approach makes it the best option for enterprises requiring high-volume, always-on data pipelines. Bright Data’s network ensures that enterprises can scale their data collection without performance degradation. Its ease of use and excellent support ensure rapid deployment in high-demand environments.
Pricing Structure: Volume-based pricing with enterprise tiers available. Offers both pay-as-you-go and commitment-based pricing models.
Common Challenges: Higher cost structure than some alternatives. Their unique selling proposition lies in proxies, which may not fit custom data extraction needs best.
What reviewers say: On G2 and Trustpilot, reviewers consistently praise the reliability and scale of the proxy network and call out responsive, knowledgeable support. The most common complaint is a steep learning curve, and several reviewers note the pricing does not fit smaller projects well.
Real-World Use Case: A global e-commerce company uses Bright Data for continuous price monitoring across 50,000 competitor websites, enabling real-time pricing adjustments and improved competitive positioning.
3. Oxylabs: Massive Proxy Pool
Oxylabs is another heavy-hitter, recognized for its high success rates and AI-powered scraping tools. The platform’s real-time crawling capabilities and AI-driven unblocking make it a top choice for high-concurrency use cases.
| Attribute | Detail |
|---|---|
| Best for | High-concurrency, low-latency scraping at global coverage |
| Service model | Self-serve proxies and scraper APIs with enterprise SLAs |
| Scale / proxy pool | 102M+ residential IPs across 200+ countries |
| Pricing model | Tiered enterprise plans by request volume and IP needs |
| Compliance | Custom SLAs available for enterprise accounts |
| Standout strength | AI-powered crawling that adapts to CAPTCHAs and JS challenges |
| Watch-out | Advanced features need technical expertise; premium pricing |
Key Features:
- 102 million residential IPs with access to over 200 countries.
- Up to 99% success rate and a 0.41-second median latency (Proxyway Benchmark, 2024).
- AI-powered crawling that automatically adjusts to site changes (e.g., CAPTCHAs, JS challenges).
- Excellent support and custom Service Level Agreements (SLAs) for enterprise accounts.
Why Enterprises Choose It:
Oxylabs is ideal for companies that need high concurrency and low latency. It’s best for retail, travel, and finance industries, where fast data extraction and quick response times are crucial for making real-time decisions.
Pricing Structure: Tiered enterprise plans based on request volume and IP requirements. Custom pricing available for specialized needs.
Common Challenges: Advanced features may require technical expertise to be fully utilized. They are suitable for standardized extraction but may not meet the needs of highly customized projects.
What reviewers say: Reviewers on G2 and Trustpilot rate Oxylabs highly for IP quality, success rates, and dedicated account management. Recurring criticisms are the price at larger volumes and a setup process that can feel unintuitive for beginners.
Real-World Use Case: A multinational retail corporation uses Oxylabs to monitor pricing for over 100,000 products from more than 500 suppliers, ensuring they maintain competitive pricing strategies in real-time.
4. Zyte: Compliance-First Web Scraping Service for High-Risk Industries
Zyte (formerly Scrapinghub) is a web scraping platform known for its legal compliance features and enterprise-grade security. It offers services for businesses that must adhere to strict data protection regulations. Zyte’s Smart Proxy Manager enables seamless data collection even from sites with strict anti-scraping measures.
| Attribute | Detail |
|---|---|
| Best for | Compliance-sensitive scraping in regulated industries |
| Service model | Managed scraping platform with Smart Proxy Manager |
| Scale / proxy pool | 14M+ IP addresses with AI-based unblocking |
| Pricing model | Subscription-based with premium and volume add-ons |
| Compliance | ISO 27001 certified; in-house legal team for GDPR |
| Standout strength | Legal-first posture for high-risk data extraction |
| Watch-out | Conservative methods can lower success on some targets |
Key Features:
- 14 million IP addresses with built-in AI-based unblocking
- ISO 27001 certification, with an in-house legal team to ensure compliance with GDPR and other data privacy regulations
- Custom SLAs for high-risk industries requiring data extraction at scale while managing legal risk
Why Enterprises Choose It:
Zyte’s focus on compliance makes it the go-to option for industries like finance, media, and government, where privacy laws and regulations play a critical role. The platform’s ability to scale scraping efforts while ensuring data privacy compliance makes it a trusted solution for highly regulated sectors.
Pricing Structure: Subscription-based with additional charges for premium features and higher volume requirements. Enterprise plans include custom compliance provisions.
Common Challenges: A more conservative approach to certain extraction methods might impact success rates for some targets, though this tradeoff often benefits compliance-sensitive operations.
What reviewers say: On G2 and Capterra, reviewers praise Zyte for reliability, low latency, and responsive support, even on weekends. The recurring frustration is around pricing and billing, where some reviewers report costs rising faster than expected at higher volumes.
Real-World Use Case: A prominent media company utilizes Zyte to crawl public court records and legal documents, ensuring full GDPR compliance while minimizing legal exposure and maintaining data provenance.
5. Apify: Developer-Centric Web Scraping for Custom Workflows
Apify stands out as a developer-first solution that provides highly customizable scraping workflows. With over 4,500 pre-built actors in its marketplace, Apify allows developers to rapidly deploy low-code web scraping solutions while maintaining complete control over data extraction processes.
| Attribute | Detail |
|---|---|
| Best for | Developer teams building tailored scraping workflows |
| Service model | Low-code platform with actor marketplace, API, and SDK |
| Scale / proxy pool | 4,500+ pre-built actors; managed proxies and compute |
| Pricing model | Team and enterprise plans by compute units and usage |
| Compliance | Custom enterprise agreements for large deployments |
| Standout strength | Fast concept-to-production with full developer control |
| Watch-out | Compute-unit pricing and plan caps need close watching |
Key Features:
- 4,500+ ready-made actors that automate various scraping tasks (e.g., web crawling, data extraction, data transformation).
- Low-code platform with full API and SDK support for developers.
- Customizable workflows using Apify’s Actor SDK and integration with GitHub CI/CD pipelines.
Why Enterprises Choose It:
Apify is perfect for companies with strong internal development teams that want to create tailored scraping solutions. The platform’s flexibility and scalability make it suitable for businesses that require high-level customization and rapid deployment.
Pricing Structure: Team and enterprise plans are available, with pricing based on compute units and platform usage. Custom enterprise agreements are available for large-scale implementations.
Common Challenges: Requires some technical expertise to maximize value, although the extensive actor marketplace significantly reduces development overhead.
What reviewers say: Reviewers on G2 and Capterra like the intuitive interface, the breadth of pre-built actors, and how fast they can get from concept to production. The common watch-outs are the compute-unit learning curve and plan caps that can halt jobs once monthly limits are hit.
Real-World Use Case: A technology startup leveraged Apify to create a comprehensive social media intelligence tool that tracks real-time brand mentions, analyzes sentiment patterns, and delivers actionable marketing insights.
6. ScraperAPI: Simple Pay-Per-Request Scraping at Scale
ScraperAPI is a request-based scraping API that handles proxies, browsers, and anti-bot challenges behind a single endpoint. It appeals to teams that want to send a URL and get structured HTML back without building or maintaining their own proxy rotation, so engineering effort stays focused on using the data rather than fetching it.
| Attribute | Detail |
|---|---|
| Best for | Teams wanting a simple API without managing proxies |
| Service model | Self-serve scraping API with automatic proxy handling |
| Scale / proxy pool | Large rotating proxy pool with retries handled server-side |
| Pricing model | Pay per successful request, credits scaled by site difficulty |
| Compliance | Targets publicly accessible data; standard usage terms |
| Standout strength | Pay-only-for-success model and approachable documentation |
| Watch-out | Credit costs for premium parameters can be confusing |
Key Features:
- Automatic proxy rotation and retries, so requests that fail are handled without manual intervention.
- JavaScript rendering and geotargeting for sites that need a real browser or specific regional access.
- Pay per successful request, with credit cost scaled to how protected the target domain is.
Why Enterprises Choose It:
ScraperAPI is a strong fit for teams that want predictable, usage-based scraping without operating proxy infrastructure. The pay-per-successful-request model keeps costs tied to results, which makes it straightforward to budget for steady extraction workloads across many sites.
Pricing Structure: Credit-based, charged per successful request, with harder-to-scrape domains consuming more credits. Plans scale from a free tier up through higher-volume monthly tiers.
Common Challenges: The credit cost of premium parameters can be hard to predict, so teams should model their request mix before committing to a plan.
What reviewers say: On G2 and Capterra, reviewers highlight the ease of use, clear documentation, and responsive support. The most common gripe is that the credit breakdown for premium parameters can be confusing.
Real-World Use Case: A data team uses ScraperAPI to pull product listings across many retail domains, leaning on the pay-per-success model to keep extraction costs aligned with the records they actually collect.
7. Nimble: AI-Structured Web Data Through Purpose-Built APIs
Nimble is a web data platform that uses AI to extract and structure information, built for data, engineering, and business teams that need dependable access to external web data. Rather than returning raw HTML alone, Nimble leans on purpose-built APIs for different targets, which suits use cases like market intelligence, competitive benchmarking, and AI model training.
| Attribute | Detail |
|---|---|
| Best for | Teams wanting AI-structured web data via dedicated APIs |
| Service model | Web data platform with target-specific APIs and dashboard |
| Scale / proxy pool | Managed proxy and platform infrastructure across regions |
| Pricing model | Pay-as-you-go per GB plus tiered monthly platform plans |
| Compliance | Built around publicly accessible data with GDPR/CCPA in mind |
| Standout strength | AI structuring and a clear monitoring and analytics dashboard |
| Watch-out | Premium pricing; some reviewers cite uneven support |
Key Features:
- Purpose-built APIs for web, search, and other targets, so each use case has a fitted endpoint.
- AI-driven structuring that turns pages into usable, organized output rather than raw markup.
- Monitoring dashboard for tracking requests, spend, and scraper performance in one place.
Why Enterprises Choose It:
Nimble is a good fit for teams that want structured output and clear observability without stitching together separate tools. The dashboard and AI structuring reduce the post-processing work that usually follows raw scraping, which matters when data feeds analytics or model training directly.
Pricing Structure: A pay-as-you-go per-GB rate alongside tiered monthly platform plans, with custom enterprise pricing available on request.
Common Challenges: It is positioned as a premium platform, so cost can be a factor, and teams should confirm support expectations during evaluation.
What reviewers say: On G2, reviewers value the monitoring dashboard, the fitted APIs, and the ease of integration in Python. The recurring criticisms are the premium price point and, for some reviewers, slow or unresponsive support.
Real-World Use Case: A market intelligence team uses Nimble to collect and structure competitor and pricing data across regions, feeding the cleaned output straight into their analytics workflow.
8. ZenRows: Anti-Bot Bypass in a Single API Call
ZenRows is a scraping API focused on getting past anti-bot defenses, bundling CAPTCHA handling, JavaScript rendering, and proxy rotation into one request. It targets engineering teams whose hardest task is not parsing data but reaching protected sites in the first place.
| Attribute | Detail |
|---|---|
| Best for | Engineering teams scraping heavily protected sites |
| Service model | Self-serve Universal Scraper API |
| Scale / proxy pool | 55M+ residential IPs with anti-bot technology |
| Pricing model | Usage-based per-1,000-request rate, scaled by difficulty |
| Compliance | Targets publicly accessible data; standard usage terms |
| Standout strength | CAPTCHA, JS rendering, and proxy rotation in one call |
| Watch-out | Cost rises for premium proxies; very robust sites can still fail |
Key Features:
- Universal Scraper API that bundles unblocking, rendering, and proxy rotation into a single endpoint.
- Network of 55M+ residential IPs paired with anti-bot technology for protected targets.
- Transparent usage-based pricing with rates that scale to how difficult the target is.
Why Enterprises Choose It:
ZenRows is a practical choice when the main obstacle is anti-bot protection rather than volume alone. Folding CAPTCHA solving, rendering, and rotation into one call removes a lot of the plumbing that engineering teams would otherwise build and maintain themselves.
Pricing Structure: A pay-as-you-go model priced per thousand requests, with the rate increasing for targets that need JavaScript rendering and premium proxies.
Common Challenges: Costs climb for the most demanding targets, and the most heavily fortified sites can still produce occasional failures.
What reviewers say: On G2, reviewers describe the API as easy to use, well documented, and quick to learn, with reliable handling of protected sites. The watch-outs they raise are occasional failures on the most robust systems and rising costs for advanced scraping.
Real-World Use Case: An engineering team uses ZenRows to collect product and listing data from sites with strong anti-bot defenses, relying on the single-call API to handle rendering and unblocking.
9. Decodo (formerly Smartproxy): Proxy Quality at an Accessible Entry Point
Decodo, formerly Smartproxy, is a proxy and scraping provider known for reliable performance and an approachable entry price. It pairs residential, datacenter, and mobile proxies with a scraping API, which makes it a flexible option for teams that want strong proxy quality without a steep starting commitment.
| Attribute | Detail |
|---|---|
| Best for | Teams wanting proxy quality at an accessible entry price |
| Service model | Self-serve proxies plus a scraping API |
| Scale / proxy pool | Large residential, datacenter, and mobile proxy pools |
| Pricing model | Per-GB proxy pricing and per-request scraping API tiers |
| Compliance | Targets publicly accessible data; standard usage terms |
| Standout strength | High proxy quality with easy setup and responsive support |
| Watch-out | Cost can climb for the largest-scale projects |
Key Features:
- Residential, datacenter, and mobile proxies covering a wide range of collection needs.
- Scraping API with per-request pricing for teams that want managed extraction.
- Intuitive dashboard and quick setup suited to both newer and experienced users.
Why Enterprises Choose It:
Decodo is a sensible option for teams that want dependable proxies and a gentle on-ramp. The accessible entry pricing and easy setup let teams validate a use case before scaling, while the proxy quality holds up as volume grows.
Pricing Structure: Per-GB pricing for residential and mobile proxies, monthly datacenter plans, and a scraping API priced per block of successful requests.
Common Challenges: As with most proxy vendors, costs can rise for the largest-scale projects, so teams should size their plan against expected volume.
What reviewers say: On G2 and Trustpilot, reviewers consistently praise proxy quality, high success rates, easy setup, and responsive support. The main caveat raised is that pricing can run high for larger-scale work, though many reviewers still call the quality-to-price ratio strong.
Real-World Use Case: A growth-stage team uses Decodo to run regional price and availability checks, starting on an entry plan and scaling proxy usage as their monitoring expanded.
10. Crawlbase: Budget-Friendly High-Volume Crawling
Crawlbase, formerly ProxyCrawl, is a scraping platform built for developers pulling standard data at high volume. Its suite includes a crawling API, a smart rotating proxy, a leads API, and cloud storage, and its per-request pricing gets cheaper as monthly volume rises, which makes it attractive for steady, large-scale jobs.
| Attribute | Detail |
|---|---|
| Best for | Developers running high-volume standard scraping on a budget |
| Service model | Crawling API, smart proxy, leads API, and cloud storage |
| Scale / proxy pool | Thousands of residential and datacenter proxies worldwide |
| Pricing model | Per-request pricing that drops as monthly volume grows |
| Compliance | Targets publicly accessible data; standard usage terms |
| Standout strength | Competitive cost per request at high volume |
| Watch-out | Dated dashboard; heavily protected sites can be tough |
Key Features:
- Crawling API and smart rotating proxy built on thousands of worldwide proxies.
- Leads API and cloud storage for teams that want collection and retention in one place.
- Volume-tiered per-request pricing, where the cost per request falls as monthly usage climbs.
Why Enterprises Choose It:
Crawlbase is a cost-effective pick for steady, high-volume scraping of standard sites. The volume-tiered pricing rewards consistent workloads, which suits teams whose targets are not the most heavily defended and whose priority is predictable cost at scale.
Pricing Structure: Per-request crawling pricing that decreases with monthly volume, separate proxy plans, and storage tiers, with a small free allowance to start.
Common Challenges: The dashboard feels dated, and the most heavily protected sites can be harder to handle, so teams with those targets may need a more specialized option.
What reviewers say: Across G2, Capterra, and Trustpilot, reviewers call Crawlbase affordable, reliable, and fast, and competitive at high volumes, though sample sizes are small. The watch-outs they note are a dated dashboard and weaker performance against heavily protected sites.
Real-World Use Case: A development team uses Crawlbase to run ongoing, high-volume collection across standard catalog and directory sites, taking advantage of the volume-tiered pricing to keep cost per record low.
Q: Which web data extraction services scale best for enterprise-level scraping?
A: Ten services consistently handle enterprise volume, each with a different center of gravity. Forage AI leads for fully managed, custom AI-driven extraction with human-in-the-loop QA. Bright Data and Oxylabs win on raw proxy scale and speed; Zyte leads on compliance; Apify, ScraperAPI, ZenRows, and Crawlbase serve developer and API-first teams at different price points; Nimble and Decodo sit between, pairing proxies or AI structuring with accessible entry tiers. The right pick depends on whether you want a managed pipeline or self-serve infrastructure, and on your volume, data complexity, and compliance needs.
Expert Insights
A pattern runs through the public reviews of every provider here. The proxy-led platforms draw the strongest praise for scale and reliability and the most consistent complaints about a steep learning curve and pricing that surprises smaller teams. The API-first tools win on ease of use but ask buyers to model their request mix carefully, because usage-based credits can drift. That is the real tradeoff in this category: the more infrastructure a provider hands you to operate, the more capability you get and the more engineering ownership you take on. A managed approach moves that ownership off your team.
Choosing the Right Enterprise Web Scraping Solution
When selecting an enterprise web scraping service, organizations must prioritize three critical factors: scale, reliability, and flexibility. These elements form the foundation of any successful enterprise data extraction strategy. The table below compares all ten providers on the dimensions that usually decide the choice.
| Provider | Service model | Best for | Scale | Pricing model | Compliance |
|---|---|---|---|---|---|
| Forage AI | Fully managed, done-for-you | Custom AI extraction at enterprise scale | 500M+ sites crawled regularly | Custom enterprise by volume/complexity | Custom SLAs, structured datasets |
| Bright Data | Self-serve proxies, APIs, datasets | High-volume, always-on pipelines | 72M+ residential IPs | Volume-based, PAYG and commitment | Ethical-collection emphasis |
| Oxylabs | Self-serve proxies and scraper APIs | High concurrency, global coverage | 102M+ IPs, 200+ countries | Tiered enterprise plans | Custom enterprise SLAs |
| Zyte | Managed scraping platform | Regulated, compliance-sensitive work | 14M+ IPs | Subscription with add-ons | ISO 27001, in-house legal |
| Apify | Low-code platform, actor marketplace | Developer-built custom workflows | 4,500+ pre-built actors | Compute-unit and usage based | Custom enterprise agreements |
| ScraperAPI | Self-serve scraping API | Simple API without managing proxies | Large rotating proxy pool | Pay per successful request | Public-data focus, standard terms |
| Nimble | AI web data platform with APIs | AI-structured data via dedicated APIs | Managed multi-region infrastructure | Per-GB plus tiered platform plans | Public-data focus, GDPR/CCPA aware |
| ZenRows | Self-serve scraper API | Scraping heavily protected sites | 55M+ residential IPs | Usage-based per 1,000 requests | Public-data focus, standard terms |
| Decodo | Self-serve proxies plus scraping API | Proxy quality at an accessible entry | Large residential/datacenter/mobile pools | Per-GB and per-request tiers | Public-data focus, standard terms |
| Crawlbase | Crawling API, proxy, storage | High-volume standard scraping on budget | Thousands of worldwide proxies | Per-request, cheaper at volume | Public-data focus, standard terms |
Each of the providers we’ve examined offers distinct advantages:
Forage AI excels with its customization approach and reliability, which makes it scalable to meet business needs. It offers a highly flexible infrastructure that adapts to various industry use cases. Its human-in-the-loop quality assurance ensures high accuracy and reliability, even when processing complex unstructured data.
Bright Data offers a reliable solution for data collection. It features a large IP pool and prompt response times, making it suitable for ongoing tasks.
Oxylabs balances a massive proxy network with AI-powered unblocking capabilities, making it suitable for businesses that need high concurrency and global coverage.
Zyte focuses on compliance and security, offering a safer option for highly regulated industries with legal risks.
Apify offers a developer-centric approach with extensive customization options, which is ideal for organizations with technical teams seeking tailored solutions.
ScraperAPI, ZenRows, Decodo, and Crawlbase serve API-first and proxy-first teams that want self-serve, usage-based scraping, ranging from anti-bot bypass to budget-friendly high-volume crawling. Nimble sits alongside them with AI-structured output for teams that want clean data rather than raw HTML.
The actual value of enterprise web scraping lies not just in the volume of data collected but also in its ability to scale reliably as business needs evolve. Solutions like Forage AI demonstrate scalability without sacrificing quality, using flexible infrastructure that expands based on actual requirements while maintaining data accuracy through human oversight.
As web data becomes increasingly crucial for business intelligence, competitive analysis, and strategic decision-making, investing in the proper enterprise-grade scraping infrastructure is no longer optional but essential. The right provider will deliver reliable data at scale and free your engineering resources to focus on extracting valuable insights rather than maintaining complex extraction pipelines.
When selecting, consider your organization’s specific requirements, including volume needs, data complexity, industry regulations, and integration capabilities. With the right enterprise web scraping partner, your organization can transform raw web data into a sustainable competitive advantage.
Q: How do you choose the right enterprise web scraping solution?
A: Start with three factors: scale, reliability, and flexibility. Then match a provider to your own situation. If you want the pipeline handled end to end with high accuracy on complex data, a managed service like Forage AI fits. If you have an engineering team and want to run your own infrastructure, the proxy and API providers give you more control at the cost of more ownership. Weigh volume, data complexity, industry regulations, and integration needs together rather than choosing on price or proxy count alone.
Expert Insights
The most expensive part of web scraping is rarely the data itself. It is the engineering time spent keeping pipelines alive as sites change and defenses tighten. That is why the choice between a self-serve platform and a managed service is the decision that matters most. A self-serve tool gives you control and a lower sticker price; a managed approach trades that for freeing your engineers to work on insight rather than maintenance. For high-volume, complex, or regulated work, the team you do not have to staff is often worth more than the per-request rate you save.
Frequently Asked Questions
What is the difference between a managed scraping service and a scraping API?
A managed service runs the full pipeline for you, from crawling to delivery of clean, structured data, with its own QA. A scraping API gives you the fetching layer and leaves your team to handle parsing, scheduling, and integration. The first trades cost for less engineering ownership; the second trades engineering ownership for more control.
Which provider is best for compliance-heavy industries?
Zyte is built around compliance, with ISO 27001 certification and an in-house legal team, which makes it a fit for finance, media, and government work. For fully managed programs in regulated sectors, Forage AI offers custom SLAs and structured, client-specific datasets. The right choice depends on whether you want to run the extraction yourself or hand it off.
Do these services work for scraping sites with strong anti-bot protection?
Yes, though they differ in how well. Bright Data and Oxylabs lean on large proxy networks and AI-driven unblocking, while ZenRows bundles CAPTCHA handling, JavaScript rendering, and proxy rotation into a single call for protected targets. Budget-focused options can struggle with the most heavily defended sites, so match the tool to your hardest target rather than your average one.
How is pricing usually structured for these providers?
Most fall into three patterns. Proxy vendors charge per GB of traffic, API providers charge per request or per successful request, and managed services price by volume, complexity, and frequency under a custom agreement. Because credit and per-request costs can scale with how protected a target is, model your expected request mix before committing to a plan.




