

AI conversations often focus on models, architectures, benchmarks, and parameters. While these are great performance evaluators, you cannot really use any model for any use case. The training data largely determines how the model will perform in your projects.
So today, I want to talk about the fuel that powers the AI engine: data.
As organizations scale AI initiatives in 2026 and beyond, the central challenge is no longer model selection; it is whether the underlying data for AI is accurate, current, and usable in production. Many AI systems underperform not because of technical limitations, but because the data feeding them is incomplete, outdated, or misaligned with the use case.
This has pushed enterprises to rethink how they source AI training data, moving beyond ad-hoc datasets toward AI-ready data pipelines, alternative data feeds, and continuously refreshed inputs. For AI to work reliably, data must be treated as infrastructure, not as a one-time asset.
Teams that treat data as long-term infrastructure tend to scale AI faster and with fewer production failures.
In this blog, we’ll break down:
- What “data for AI” actually means
- The different types of AI data
- Sources of data to train your AI
- How it’s used in real systems
- How teams operationalize it
- How to access your data
- Practical steps to get started
Modern AI systems are built on data for AI, not just models. From AI training data used to teach systems patterns, to AI-ready data that powers production workflows, success depends on how data is collected, prepared, and maintained over time. As organizations scale, AI data collection increasingly relies on automation, including automated data extraction for AI, external signals, and web data for AI models. These inputs flow through data pipelines for AI, often forming RAG-ready data feeds that keep AI systems accurate, contextual, and up to date.
What Does “Data for AI” Really Mean?
In simple terms, data for AI is any information used to train, evaluate, or power AI applications. This includes inputs for traditional machine learning models, large language models (LLMs), predictive systems, and retrieval-augmented generation (RAG) architectures.
In practice, AI systems rely on three broad categories of data:
- Structured data: Databases, tables, transactional records
- Unstructured data: Documents, PDFs, emails, images, videos, and web content
- Semi-structured data: JSON, XML, logs, and event streams
These data types originate from multiple data sources, including internal systems, third-party providers, and increasingly, alternative data feeds for AI companies that provide real-world signals unavailable in traditional datasets.
As AI use cases mature, organizations are increasingly turning to scraping their own data for AI to ensure their models stay aligned with their goals and rapidly changing environments.
The most resilient AI systems are built on data sources designed to evolve and expand, not remain static.
Why Data Is the Most Critical Component of AI
Your data actually defines your model.
AI systems learn statistical patterns directly from historical data. If the quality of AI training data is poor, biased, incomplete, inconsistent, or stale, the resulting models inherit those weaknesses.
This is why AI-ready datasets are essential. High-quality data improves:
- Predictive accuracy
- Model generalization
- Stability in production environments
- Trust and explainability
Improving model performance often starts with improving the data feeding the model, not retraining it.
Types of Data Used in AI Systems
AI systems consume many kinds of information. Understanding different types and formats helps you design better pipelines.
Structured Data
Structured data includes:
- SQL databases
- CRM and ERP(Customer Relationship Management and Enterprise Resourse Planning) systems
- Financial and operational records
Because it follows predefined schemas, structured data is ideal for:
- Predictive analytics
- Risk scoring
- Forecasting and optimization models
This data remains foundational for enterprise AI, especially in regulated domains. Because the data is already structured, it is easy to import into your training systems.
Unstructured Data
Unstructured data includes:
- Emails and chat logs
- PDFs and reports
- Images, audio, and video
- Websites and public web content
This is now the fastest-growing source of AI training data, particularly for LLMs and RAG systems. Unlocking its value demands robust enterprise-level scraping for RAG datasets, efficient document parsing, and conversion into structured formats.
Unstructured data becomes valuable only when it can be reliably transformed into model-consumable formats.
Labeled vs. Unlabeled Data
AI systems also differ based on supervision:
- Labeled data for AI enables precise supervised learning
- Unlabeled data supports unsupervised and generative systems
Accurate data annotation for AI is especially important in domain-specific and high-risk use cases.
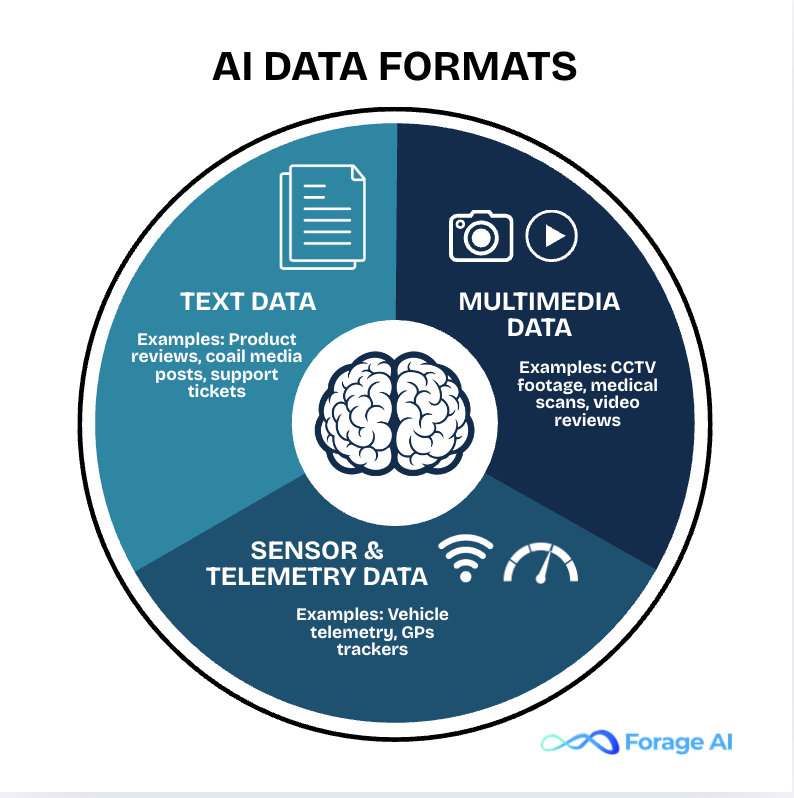
Before discussing how organizations collect different types of data, it’s important to understand the formats AI systems actually consume. While data is often categorized as structured or unstructured, AI pipelines are ultimately designed around data formats and how information is represented, processed, and fed into models.
In most enterprise AI systems, unstructured data must be converted into more digestible, structured, or semi-structured formats before it can be used reliably. This transformation step is critical when designing scalable AI pipelines, especially for machine learning, LLMs, and RAG-based systems.
Below is an overview of the most common data formats used in AI systems, along with real-world examples and AI use cases.
| Data Format | Description | Examples | Common AI Use Cases |
| Text Data | Natural language data extracted from documents, websites, or user-generated content. Often requires cleaning, tokenization, and embedding before use. | Articles, product descriptions, product reviews, emails, support tickets, social media posts | Sentiment analysis, product review analysis, document classification, topic modeling, search & retrieval, LLM training, RAG systems |
| Multimedia Data (Images, Audio, Video) | Visual and auditory data that requires preprocessing such as resizing, frame extraction, or feature encoding. | Product images, CCTV footage, medical scans, call recordings, video reviews | Visual inspection, object detection, content moderation, product classification, speech recognition, call analysis |
| Sensor & Telemetry Data | Time-series data generated continuously from devices, machines, or systems. Often high-volume and real-time. | IoT sensors, GPS trackers, machine logs, vehicle telemetry | Predictive maintenance, logistics optimization, anomaly detection, demand forecasting, real-time monitoring |
Where Does Data for AI Come From?
Now comes the key question: where to actually get data from?
Your actual data sources depend on your use case. Eg, if you are building an object classification project on clothes/merchandise, you will need to train your project on millions of images scraped from the web. Modern AI data collection strategies typically combine:
- Internal business systems
- Public web data
- IoT and sensor-generated data
- Synthetic data
To augment internal datasets, many organizations work with web scraping companies for AI data, enabling continuous ingestion of external signals. These sources often power RAG-ready data feeds that keep AI systems contextually relevant.
| Data Source | Description | Examples | Common AI Applications |
| Internal Data | Trusted, proprietary data generated within the organization. Highly reliable but limited to internal context and historical scope. | CRM records, transaction logs, support tickets, operational systems | Customer churn prediction, sales forecasting, internal analytics, process optimization |
| Web Data | External, publicly available or permissioned data collected from websites and online sources. Adds real-world context and market awareness. | Product listings, reviews, news articles, competitor websites, pricing pages | Market intelligence, RAG systems, sentiment analysis, competitive benchmarking, trend detection |
| Synthetic Data | Artificially generated data designed to simulate real-world scenarios. Useful for testing and model training, but rarely a full replacement for real data. | Simulated transactions, synthetic images, generated user behavior | Model stress testing, data augmentation, edge-case simulation, privacy-safe experimentation |
| Sensor Data | Continuous, time-series data generated by physical devices or systems. Often high-volume and real-time. | IoT sensors, GPS data, machine telemetry, environmental sensors | Predictive maintenance, logistics optimization, anomaly detection, real-time monitoring |
The Role of Automated Data Extraction in AI
Given the volume and complexity of the data, manual collection is out of the question in most scenarios.
Automated data extraction for AI enables organizations to:
- Extract unstructured data from websites, documents, and PDFs
- Build continuously updating training datasets, and improve performance based on fresh data
- Scale automated data pipelines without linear cost increases
Many enterprises now partner with automated AI training data feed providers like Forage AI, which deliver structured, compliant, and continuously refreshed data streams.
This is especially critical for RAG systems, where enterprise scraping for RAG datasets ensures retrieval accuracy remains high as source data changes.
How to Prepare Data for AI (Preprocessing & Readiness)
Extraction alone does not make data usable. To support AI systems, data must be prepared deliberately.
Data preprocessing for AI includes:
- Cleaning inconsistent records
- Removing duplicates
- Handling missing values
- Normalizing schemas and formats
- Converting unstructured data into structured, model-ready representations
These steps transform raw inputs into AI-ready data. If you work with experienced data providers, their QA processes include these basic steps. For example, at Forage AI, we implement a thorough QA process that involves automated, semi-automated, and human-in-the-loop validation techniques by default so you can directly feed the data into your AI system.
How You Can Use Data for AI: Practical Applications
Once data is collected and prepared, its value becomes measurable through application. Most Most AI applications use data in three major ways:
- Training & Fine-Tuning: Teaching models how to understand language, images, or patterns.
- Retrieval-Augmented Generation (RAG): Instead of memorizing everything, modern AI systems retrieve fresh information when answering questions. Eg: A research agent pulls current market data from structured reports. This requires reliable, constantly refreshed data pipelines.
- Monitoring & Improvement: Models degrade over time. Data must be regularly updated, cleaned, revalidated, and reprocessed.
Industry Applications
Finance: Fraud Detection and Credit Risk Modelling
In finance, AI systems rely heavily on structured data such as transaction logs, account activity, payment histories, and behavioral signals. By analyzing patterns across millions of transactions, AI models can identify anomalies that may indicate fraud in real time. Historical data is also used to train credit risk models that assess the likelihood of default by examining spending behavior, repayment history, and external economic signals. High-quality, continuously updated data is critical here, as outdated or incomplete data can lead to false positives, missed fraud cases, or inaccurate risk assessments.
Healthcare: Clinical Analytics and Patient Insights
In healthcare, AI is used to support clinical decision-making and operational efficiency by analyzing both structured and unstructured data. This includes patient records, lab results, clinical notes, medical images, and device-generated data. AI systems can surface patterns that help clinicians identify risk factors, predict patient outcomes, and optimize treatment pathways. Because healthcare data is sensitive and highly regulated, accuracy, data quality, and compliance are essential. Well-prepared, AI-ready data enables healthcare organizations to generate insights while maintaining patient privacy and regulatory standards.
E-commerce: Product Intelligence and Pricing Analysis
In e-commerce, AI systems combine internal data such as sales transactions and inventory levels with external signals like product listings, reviews, and competitor pricing. This data is used to power product intelligence systems that analyze demand trends, customer preferences, and market positioning. AI-driven pricing models use these insights to recommend dynamic pricing strategies, optimize promotions, and improve margins. The effectiveness of these systems depends on access to fresh, comprehensive data that reflects real-time market conditions.
These are just a few examples; with AI, the possibilities are endless. A strong enterprise AI data strategy ensures each use case is supported by the right data pipelines.
Checklist: Building an AI-Ready Data Pipeline
What makes your data “AI-ready”? AI-ready data typically meets these standards:
| Requirement | Why It Matters |
| Structured format | Models need consistency |
| Clean & deduplicated | Prevents bias and noise |
| Accurate & validated | Bad data = bad AI |
| Fresh & updated | Stale data breaks RAG, provides inaccurate results |
| Properly labeled | Enables training |
| Traceable source | Compliance & governance. |
Common Challenges in Sourcing Data for AI
Most AI teams don’t struggle with models, they struggle with getting reliable data at scale. Despite its well-known importance, collecting and extracting data for AI introduces persistent challenges like:
- Biased or incomplete datasets
- Ongoing AI data quality issues due to layout changes
- Data cleaning and normalization complexity
- Governance, privacy, and compliance constraints
- Difficulty scaling AI data pipelines
This is why many organizations move away from ad-hoc solutions toward expert data providers specializing in data for AI
Build vs Buy Data for AI
Every organization at some point faces this question: Should we build our own data pipelines or partner with a provider? Well, the simple answer is don’t re-invent the wheel. Find experts who can manage the data collection for you so you can work on what you are good at – building AI. However, let’s look at the pros and cons.
| Approach | Build In-House | Partner with Data Providers |
| When It Makes Sense | Build In-House when: – Data needs are simple – Volume is low – Sources are stable – You have dedicated engineers | Buy or Partner when: – You need ongoing freshness – Sources change frequently – Multiple formats are involved – Compliance matters – Time to market is critical |
| Pros | – Full control over data pipelines – Custom-built for internal needs – No dependency on external vendors | – Faster deployment – Access to scalable, production-ready data feeds – Built-in compliance and governance – Reduced operational burden on internal teams |
| Cons | – High engineering and maintenance cost – Hard to scale as sources change – Slower to adapt to new formats – Compliance and monitoring become your responsibility | – Less low-level control over pipelines – Ongoing vendor cost – Requires clear alignment with data requirements |
How to Operationalize Data for AI
If you do decide to build in-house, here are a few steps you can follow to operationalize your data for AI pipeline.
- Identify and prioritize AI data sources
- Use automation and scraping for external data
- Clean, validate, and monitor data quality
- Transform data into model- and RAG-ready formats
- Continuously refresh and audit pipelines
Well-designed enterprise data pipelines allow AI systems to scale safely and predictably.
Hope this helps! As AI adoption accelerates, data, not algorithms, remains the most durable competitive advantage. Organizations that invest in data will see clear benefits.
About us:
Forage AI is a leader in automated data extraction. Our state-of the-art technology and expertise fuels data pipelines built specifically for modern AI systems.
Frequently Asked Questions (FAQs)
AI training data is the dataset used to teach an AI model how to recognize patterns, make predictions, or generate outputs. The quality, scale, and relevance of this data directly affect how well an AI system performs in real-world conditions.
AI-ready data is data that has been cleaned, structured, validated, and formatted so it can be reliably used by AI models. Raw data often needs preprocessing before it becomes AI-ready.
Most organizations use a combination of AI data collection methods, including internal business systems, public web data, third-party data providers, sensor data, and sometimes synthetic data. The exact mix depends on the AI use case.
Automated data extraction for AI uses software and AI-driven systems to collect and structure data from sources like websites, documents, and PDFs at scale. Automation helps keep data fresh and reduces manual effort.
RAG-ready data feeds are continuously updated data sources prepared specifically for Retrieval-Augmented Generation (RAG) systems. They ensure AI models retrieve accurate, up-to-date information when generating responses.




