

You are not searching for “Bright Data alternatives” because you want a slightly different proxy network. You’re searching because something has shifted in how you think about the job. The data started mattering more, the engineering hours stopped being available, the legal team raised a question that didn’t come up before, or the line item on the invoice grew faster than the team that owns it.
That shift is the real subject of this article. Most lists you’ll read on this keyword compare 10 or 15 self-serve scraping tools on success rate, price per gigabyte, and country coverage. Useful if you’re picking between two infrastructure providers. Not useful if you’re starting to suspect you no longer want to operate scraping infrastructure at all.
So we’ll do this differently. We’ll acknowledge what Bright Data does well, because it does several things very well. We’ll name the five reasons enterprises start looking, and the architectural divide most “alternatives” lists never mention: self-serve infrastructure versus a fully managed extraction partner. We’ll put Forage AI side-by-side with Bright Data on the dimensions that actually decide the buy. We’ll cover five other alternatives fairly. And we’ll close with a decision framework, so you can name which tier you’re actually in before you start vendor demos.
Quick Digest
- What Bright Data does well: it runs one of the largest residential proxy networks in the market, a mature self-serve developer surface, and a dataset marketplace, and it stays a strong fit for teams with in-house engineering depth.
- Why enterprises start looking: five signals recur, cost shock at scale, maintenance staying on your team, compliance friction, account-management responsiveness, and the job quietly becoming “deliver data” rather than “run scrapers.”
- The real divide: the choice is not between two proxy networks, it’s between two service models, self-serve infrastructure (you operate it) versus fully managed extraction (a vendor delivers data).
- Forage AI vs Bright Data: Bright Data wins on speed-to-trial and proxy breadth; Forage AI wins on who owns reliability, QA depth, and pipeline maintenance over the life of the contract.
- Five other alternatives: Oxylabs, Zyte, Apify, Decodo (formerly Smartproxy), and ScrapingBee with Scrape.do each fit a specific buyer inside the self-serve tier.
- A decision framework: three questions decide the tier, who owns reliability when a site changes, how much engineering time you can spend on extraction, and what your legal team needs to sign off on.
- Migrating off Bright Data: a real enterprise migration runs a quarter or two, inventory, shadow pipelines, schema consolidation, then cutover, not a one-week swap.
Where Bright Data Wins, and Where Teams Outgrow It
First, the honest part: Bright Data is a legitimate, well-resourced vendor, and pretending otherwise would only make the rest of this guide harder to trust. It runs one of the largest residential proxy networks in the public market, with strong anti-bot evasion against Kasada, DataDome, and PerimeterX, a dataset marketplace across common verticals, and a mature self-serve developer surface (web unlocker, scraping browser, SERP API). If your team has the engineering depth to own the parsing layer, the QA, and the on-call, Bright Data is one of the best options available, and staying on it is a defensible choice.
This guide is written for the other buyer: the one who discovered, sometime in the last few quarters, that the engineering bandwidth they were counting on is not there, and the question quietly shifted from “which scraping tool” to “do we want to be in the scraping business at all?”

When we look at why teams reach out, five signals come up repeatedly. None of them are about Bright Data being bad. They’re about the buyer’s job changing.
Cost shock at scale. Per-gigabyte pricing compounds in a way that stays invisible during a proof of concept. Residential proxy pricing in the public market sits around $5.88 to $10.50 per GB at standard tiers. At 500 GB per month, the line item is comfortable. At 10 TB per month, it’s a conversation with the CFO. Enterprise contracts negotiate that down, but the negotiation itself becomes a recurring tax on the data team’s calendar.
Maintenance still lives with your team. This is the cost nobody quotes upfront. Bright Data gives you proxy and browser infrastructure. The parser, the schema, the QA, and the on-call for when a critical extractor breaks at 2 a.m. all still belong to your engineering team. Industry surveys of data engineering organizations consistently find that pipeline maintenance, not initial build, consumes the majority of multi-year engineering hours. A single mature scraping pipeline often consumes one to two full-time engineers in pure maintenance.
Compliance friction. Enterprise legal teams are paying closer attention to commercial residential proxy use, third-party data handling, audit trails, and on-premises options. Some of our largest engagements started with a legal-team mandate: “We will not run scrapers internally; we need a vendor with a contract our counsel can defend.” Self-serve infrastructure doesn’t solve that. It shifts the same legal questions onto the buyer.
Account-management responsiveness at scale. Large customers of any self-serve provider eventually report multi-day response times on account issues. Competitor coverage of Bright Data relies heavily on this point. We’ll treat it as a real but variable factor rather than a Bright Data-specific problem.
The job stopped being “scraping.” Somewhere in the maturity curve, a data team realizes its job isn’t to operate scrapers. It’s to deliver clean, structured, validated data to a downstream system. Once the job is named that way, self-serve infrastructure feels like the wrong altitude. The team is solving a means-to-an-end they’d rather outsource.
Quick Summary
Q: Why do enterprises start searching for Bright Data alternatives?
A: Five signals recur, and none are about Bright Data being bad: cost shock as per-GB pricing compounds at scale ($5.88 to $10.50/GB at standard tiers), pipeline maintenance staying on your own engineers (often one to two FTEs per mature pipeline), compliance friction as legal teams scrutinize commercial proxy use, slower account-management responsiveness at scale, and the dawning realization that the team’s real job is delivering data, not operating scrapers.
Expert Insights
“The signal we trust most isn’t cost, it’s the sentence a team uses to describe its own job. The moment a data lead says ‘our job is to deliver clean data downstream’ instead of ‘our job is to run scrapers,’ the conversation has already moved. Everything after that is just confirming which tier they belong in.”
Forage AI solutions team, from enterprise scoping engagements
The Real Divide: Self-Serve vs Managed
Almost every article ranked for this keyword compares Bright Data to other self-serve vendors. Oxylabs. Decodo. Apify. Smartproxy. These are not Bright Data alternatives in the architectural sense. They are Bright Data substitutes inside the same service-model tier.
The actual choice for a decision-maker isn’t between two proxy networks. It’s between two service models.
Self-serve infrastructure gives you a tool. You log in, you configure, you write extraction logic, you handle parsing, you maintain the pipeline as source sites change, you own QA, you own on-call. The vendor provides the hard-to-build pieces: IP rotation, headless browsers, anti-bot evasion. The buyer provides everything else. Bright Data, Oxylabs, Apify, Decodo, ScrapingBee, Scrape.do, and Zyte’s API tier all sit here.
Fully managed extraction gives you data. You describe sites, fields, cadence, and delivery format. The vendor’s team builds the extractors, runs the infrastructure, maintains the pipelines through site changes, performs quality assurance, and delivers structured data into your warehouse, API, or feed. You don’t see, or maintain, the scraping logic. Forage AI, Ficstar, Zyte’s managed tier, and Bright Data’s own Managed Data Acquisition service sit here. We cover the three real categories of web data extraction in depth elsewhere.
The mistake teams make is searching laterally, for another infrastructure provider, when the upgrade they actually need is vertical, into a different service model entirely. Once you name that divide, the comparison stops being about features and starts being about who you want to own reliability.

Quick Summary
Q: What is the real divide between Bright Data and a true alternative?
A: The divide is service model, not proxy network. Self-serve infrastructure (Bright Data, Oxylabs, Apify, Decodo, ScrapingBee, Scrape.do, Zyte’s API tier) gives you a tool and leaves parsing, QA, maintenance, and on-call with your team. Fully managed extraction (Forage AI, Ficstar, Zyte’s managed tier, Bright Data’s Managed Data Acquisition) gives you delivered data and absorbs the operating burden. Searching laterally for another infrastructure vendor misses the vertical upgrade most maturing teams actually need.
Expert Insights
“Most buyers come in comparing IP pools and success rates. That’s a horizontal comparison, and it keeps them stuck in the tier they’re trying to leave. The question that actually reframes the decision is vertical: do you want to own the pipeline, or do you want the data? Naming that one divide saves teams a quarter of demos pointed at the wrong tier.”
Forage AI solutions team, from enterprise scoping engagements
Forage AI vs Bright Data: A Side-by-Side
Here’s an honest dimension-by-dimension comparison. We’ll mark our wins and theirs.
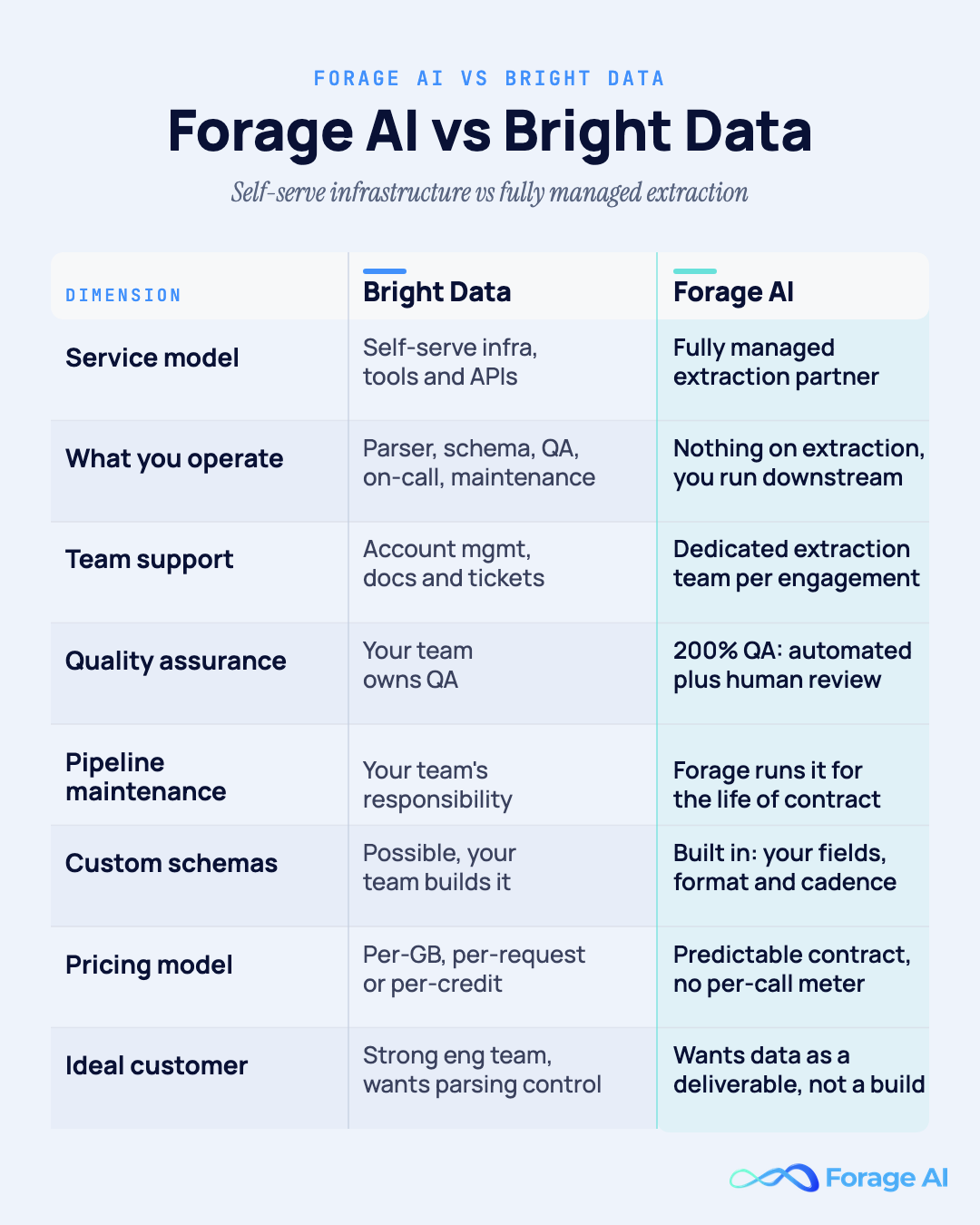
| Dimension | Bright Data | Forage AI |
|---|---|---|
| Service model | Self-serve infrastructure (tools + APIs) | Fully managed extraction partner |
| What you operate | Parser, schema, QA, on-call, maintenance | Nothing on extraction; you operate downstream |
| Team support | Account management + docs + tickets | Dedicated extraction team per engagement |
| Quality assurance | Your team owns QA | 200% QA approach: automated validation + human expert review on every extraction |
| Pipeline maintenance | Your team’s responsibility | Forage’s responsibility; we run the pipeline, forever |
| Custom schemas / business rules | Possible, your team builds | Built into the pipeline: your fields, your format, your cadence |
| Pricing model | Per-GB / per-request / per-credit | Predictable contract per scope, no per-call meter |
| Ideal customer | Teams with strong engineering bandwidth that want control of parsing | Teams that want data as a deliverable, not extraction as a capability |
Both are top players in what they offer.
Bright Data wins on speed-to-trial, proxy breadth, and anti-bot management through its self-serve platform. If you need to prototype against a wide set of geographies tomorrow, you can, and you can build a unit-cost model from their public pricing before you ever talk to a salesperson.
Forage AI wins when you need someone to own your end-to-end data extraction: crawling, scraping, QA, pipeline maintenance, and reliability over the life of the contract. That is the dimension that decides most enterprise renewals: who owns reliability when the source site changes, and who is accountable for the data your product depends on. Our QA team is roughly three times the industry average in size relative to delivery, and we run the pipeline for you. When something breaks, we fix it before your dashboards know.
Quick Summary
Q: How does Forage AI compare to Bright Data?
A: They sit in different service-model tiers, so the comparison is about ownership, not features. Bright Data wins on speed-to-trial, proxy network breadth, and transparent self-serve pricing. Forage AI wins on who owns reliability after a site changes, QA depth (a 200% approach with human review on every extraction, a QA team three times the industry average), pipeline maintenance owned for the life of the contract, custom schemas, and predictable contract pricing with no per-call meter.
Expert Insights
“The line that lands with our largest customers is the same one we put in the table: we run the pipeline, forever. That’s not a slogan, it’s the renewal logic. Enterprise contracts don’t turn on whose proxy pool is wider, they turn on who answers the page at 2 a.m. when the data your product depends on slips.”
Forage AI solutions team, from enterprise scoping engagements
Five Other Bright Data Alternatives, In Depth
If you’re shopping within the self-serve tier, here are the names worth considering, each with the buyer it fits and the watch-out to weigh. We’ll keep this fair. Every one of these is a named subject, not a source we’re citing.
Oxylabs
| Best for | Teams leaving Bright Data over service responsiveness, not service model |
| Service model | Self-serve infrastructure (residential proxies + scraper APIs) |
| Pricing model | Per-GB / subscription, in a comparable band to Bright Data |
| Standout strength | Broad residential network at near-Bright-Data scale, strong account responsiveness |
| Watch-out | Same service model, so parsing, QA, and maintenance still sit with you |
| vs Bright Data | The closest direct substitute on raw scale; a lateral move, not a tier change |
Oxylabs is the closest direct substitute to Bright Data on raw scale. It runs a comparable residential proxy network across a broad set of countries, sits in a comparable pricing band, and shows up in competitor coverage with stronger account-management responsiveness. If your reason for leaving Bright Data is service responsiveness rather than service model, Oxylabs is the first call to make.
What it won’t change is the altitude of the work. You still own the parser, the schema, the QA, and the on-call. Switching from Bright Data to Oxylabs swaps the infrastructure vendor without changing who’s accountable when a source site moves. That’s the right trade if the tooling is fine and only the support relationship has frayed.
Zyte
| Best for | Engineering teams wanting smarter parsing without going fully managed |
| Service model | Hybrid: API-tier infrastructure plus a managed-services arm |
| Pricing model | Usage-based on the API tier; scoped contracts on the managed tier |
| Standout strength | AI-assisted extraction and enterprise SLAs; one of the few real managed alternatives |
| Watch-out | The two tiers are different commitments; be clear which one you’re buying |
| vs Bright Data | Can meet Bright Data on the API tier and exceed it on managed services |
Zyte is the hybrid in this list. It offers both API-tier infrastructure and a managed-services arm, with strength in AI-assisted extraction and enterprise SLAs. For engineering teams that want better infrastructure and smarter parsing but aren’t ready to hand off the whole pipeline, the API tier is a good fit, and our roundup of the top Zyte alternatives breaks down where each one fits.
The managed tier is where Zyte becomes a genuine cross-tier alternative. It’s one of the few real alternatives to Bright Data’s own managed service, which makes Zyte worth scoping if you’re weighing managed options. The practical caution is to be explicit internally about which tier you’re buying, because the two carry very different operating commitments.
Apify
| Best for | Developer teams composing extractors quickly from pre-built components |
| Service model | Self-serve marketplace and APIs (“actors”) |
| Pricing model | Usage / subscription on platform and actor runs |
| Standout strength | Flexible, developer-friendly, fast prototype-to-production |
| Watch-out | Less suited to deeply custom enterprise schemas at scale |
| vs Bright Data | A composition layer rather than a raw proxy network; different shape of tool |
Apify is built around a marketplace of pre-built “actors”, reusable scrapers for common jobs, plus the APIs to run and chain them. For engineering teams that want to compose extractors quickly rather than build each one from scratch, it’s flexible and developer-friendly, with a good prototype-to-production path.
The watch-out shows up at enterprise scale. Apify is less suited to deeply custom enterprise schemas than to common, well-trodden scraping jobs. If your requirements are bespoke fields, strict validation, and high-cadence delivery into a warehouse, you’ll feel the edges of the actor model, and you’re likely closer to a managed-tier decision than a tooling one.
Decodo (formerly Smartproxy)
| Best for | Cost-pressured mid-market teams with predictable needs |
| Service model | Self-serve residential and datacenter proxies plus scrapers |
| Pricing model | Positioned below Bright Data on per-GB pricing (per their own marketing) |
| Standout strength | Cost efficiency on proxies and scrapers |
| Watch-out | Weaker on enterprise SLAs and large-legal-team compliance commitments |
| vs Bright Data | A cheaper substitute in the same tier, with thinner enterprise guarantees |
Decodo, formerly Smartproxy, is the cost-optimized option here. It offers residential and datacenter proxies plus scrapers, and positions itself in its own marketing as significantly below Bright Data on per-GB pricing. For a cost-pressured mid-market team with predictable volumes, that’s a real advantage.
The trade-off lands on the enterprise dimensions. Decodo is weaker on enterprise SLAs and on the compliance commitments large legal teams ask for. If your reason for leaving Bright Data is cost and your governance bar is modest, it fits. If a legal team is in the room asking about audit trails and no-resell guarantees, it’s the wrong size of vendor for that conversation.
ScrapingBee and Scrape.do
| Best for | Small and mid-sized engineering teams with predictable volumes |
| Service model | Self-serve per-request developer APIs |
| Pricing model | Per-request, entry tiers in the $29 to $49/month range |
| Standout strength | Simple, affordable, fast to integrate for bounded jobs |
| Watch-out | Not realistic substitutes at full enterprise scale |
| vs Bright Data | A different size of vendor for a different size of buyer |
ScrapingBee and Scrape.do are per-request developer APIs with entry tiers in the $29 to $49 per month range. For small and mid-sized engineering teams with predictable volumes and bounded jobs, they’re the right tool: simple, affordable, and fast to wire into an existing codebase.
They are grouped together here because they play the same role for the same buyer. Neither is a realistic substitute for Bright Data at full enterprise scale. They’re a different size of vendor for a different size of buyer, and naming that honestly matters: reaching for a small per-request API to cover enterprise volume is how teams end up rebuilding the reliability layer themselves.
For teams comparing visual or no-code tools rather than developer APIs, our Octoparse alternatives guide covers that tier in detail.

Quick Summary
Q: What are the other Bright Data alternatives worth considering?
A: Inside the self-serve tier, five names fit distinct buyers. Oxylabs is the closest direct substitute on scale, best when you’re leaving over service, not service model. Zyte is the hybrid, with a managed tier that’s a rare cross-tier alternative. Apify suits developers composing extractors fast but strains on bespoke enterprise schemas. Decodo (formerly Smartproxy) is the cost-optimized pick, weaker on enterprise SLAs. ScrapingBee and Scrape.do are affordable per-request APIs for smaller, predictable workloads, not enterprise-scale substitutes.
Expert Insights
“Almost every one of these is a lateral move inside the same tier. We tell teams to match the alternative to the actual reason they’re leaving: pick Oxylabs for a service problem, Decodo for a cost problem, Apify or the per-request APIs for a bounded-scope problem. Only Zyte’s managed tier and a managed partner cross the divide, and that’s the move that changes who owns reliability.”
Forage AI solutions team, from enterprise scoping engagements
A Decision Framework: Three Questions

The “which tool” question is the wrong starting point. These three questions are the right ones.
1. Who owns reliability when the source site changes? Modern e-commerce, marketplace, social, and SaaS sites continuously change their DOM, throttling, and anti-bot posture. If wrong or missing data forces a customer-facing apology, a bad trade, a stocked-out SKU, or a wrong number in an executive deck, you are in reliability territory. Self-serve infrastructure can’t answer the reliability question, because the answer is “you.” Managed extraction is the model in which the reliability obligation moves off your team and onto the vendor’s contract.
2. How much engineering time can you afford to spend on extraction? Add up the real cost: salary plus benefits for one to two engineers maintaining scrapers, plus QA review hours, plus on-call rotation, plus the opportunity cost of those engineers not building the product your data feeds. We’ve seen the math land between $400K and $700K annually for a serious internal extraction effort, and that’s before tool license fees. If that number is bigger than what a managed partnership would cost, the buy decision makes itself.

3. What does your legal and compliance team need to sign off on? Regulated buyers, healthcare, finance, legal, public sector, increasingly need vendor SLAs, on-premises options, no-resell guarantees, audit trails, and a single accountable contract. Self-serve infrastructure pushes those questions back onto your in-house counsel. A managed vendor with the right contract structure absorbs them. If your legal team has flagged web data acquisition at all, this question is doing more of the deciding than the technical comparison is.
For a structured way to walk vendors through these questions, our enterprise evaluation checklist is the companion piece.
Quick Summary
Q: How do you decide which Bright Data alternative tier fits your team?
A: Skip “which tool” and answer three questions. First, who owns reliability when a source site changes? If wrong data has real downstream cost, you’re in reliability territory and self-serve answers “you.” Second, how much engineering time can you spend on extraction? A serious internal effort runs $400K to $700K a year before licenses. Third, what does legal need to sign off on? If SLAs, audit trails, or no-resell guarantees are required, a managed vendor absorbs questions self-serve pushes back onto your counsel.
Expert Insights
“When a team can’t answer the reliability question without saying ‘us,’ the tier decision is already made, they just haven’t priced it yet. The $400K to $700K range isn’t a scare number, it’s what a serious internal extraction effort actually costs once you count QA and on-call. Put that next to a scoped managed contract and the decision usually stops being a debate.”
Forage AI solutions team, from enterprise scoping engagements
Migrating Off Bright Data: Practical Considerations
If you’ve decided the managed tier is the right destination, here’s the honest shape of the migration. It is a quarter or two of work, not a weekend.
Inventory current pipelines. Map every site you scrape today, every field you extract, every downstream consumer, every cadence. The act of inventorying alone usually surfaces 20 to 30% of pipelines nobody remembered to document.
Run shadow pipelines in parallel. For four to eight weeks, the managed vendor builds and runs extractors in parallel with your Bright Data flow. You compare outputs daily. Anomalies surface, schemas reconcile, edge cases get handled.
Consolidate schemas. Migration is the one moment when fixing accumulated schema drift is cheap, the team is touching every pipeline anyway. Most migrations end with cleaner data than they started.
Cutover and decommission. Once parity is proven, redirect downstream consumers, decommission the self-serve infrastructure, and lock the contract. Bright Data costs unwind as the GB counter stops rising.
Any vendor promising a one-week cutover is selling you a story. A real enterprise migration is multi-quarter, and the value is in doing it carefully, once.
Quick Summary
Q: What does migrating off Bright Data actually involve?
A: Plan for a quarter or two, not a weekend. Inventory every pipeline, field, consumer, and cadence (this alone usually surfaces 20 to 30% of undocumented pipelines). Run shadow pipelines in parallel for four to eight weeks and compare outputs daily. Consolidate schemas while every pipeline is already being touched. Then cut over, redirect consumers, decommission the old infrastructure, and let the GB meter wind down. Any vendor promising a one-week cutover is overselling.
Expert Insights
“The shadow-pipeline phase is where trust gets built or lost. We run in parallel for weeks precisely because no one should cut over on a promise. And the schema-consolidation step is the quiet win, most teams come out of a migration with cleaner data than they had going in, because it’s the one time fixing drift is cheap.”
Forage AI solutions team, from enterprise migration engagements
FAQ
Is Forage AI a direct Bright Data replacement? Not in the literal “swap the API key” sense, we’re a different service model entirely. We’re the right replacement when you’ve concluded you don’t want to operate scraping infrastructure; you want a partner who delivers data.
What does fully managed web scraping cost compared to Bright Data? It depends on the scope. The honest comparison is not Forage’s invoice versus Bright Data’s invoice. It’s Forage’s total against Bright Data’s invoice plus your engineering and QA costs to operate it. For most enterprise workloads, the totals land closer to buyers’ expectations.
How does Bright Data’s Managed Data Acquisition service compare to Forage AI? Both sit in the managed tier, so they are in the same conversation. Differences come down to QA depth, dedicated team model, custom-schema handling, and which industries each has accumulated expertise in. Demo both and ask each vendor to scope the same engagement, the answers reveal more than the marketing pages.
When does it actually make sense to stay on Bright Data? When your team has the engineering depth to own parsing and QA, your volumes are predictable, your compliance posture is comfortable with commercial proxy use, and you genuinely want a tool rather than a partner. That’s a real profile and a defensible choice.
Where to Start
The right Bright Data alternative depends entirely on what you’re trying to outsource. If you want a different proxy network, the self-serve tier offers good options like Oxylabs, Decodo, Zyte, Apify, and others, and surveying the top data extraction tools will help you sort them. If what you really want is to stop operating scraping infrastructure, the search you’re running is the wrong shape. The next step is a scoping conversation about what data you need, not a feature comparison about how to extract it.
If you’d like to talk through whether a managed model fits your workload, we’d be glad to scope it. Talk to our expert.
Related Articles
- Build vs Buy Web Data Extraction: when in-house extraction actually pencils out
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




