You have spent six to nine months on a self-service web scraping tool. Your team owns the selectors, the proxy rotation, and the on-call rotation when something breaks. The third silent-failure incident this quarter just landed in your inbox, and leadership is asking whether to keep building or buy. You open another vendor comparison article and find a feature grid: IPs, countries, certifications, and pricing tiers. None of them answers the actual question.
Most articles on this topic compare features. This one compares failure modes.
The decision between web scraping companies and web scraping tools is not really a vendor choice. It is an operational shape choice. The two tiers address different reliability problems, and the answer for your team depends on how many sources you run, how fresh the data needs to be, the anti-bot pressure you face, and how much engineering capacity you can dedicate. Get the shape wrong, and you either pay for reliability you do not need or absorb a maintenance burden that quietly consumes your roadmap.
This piece walks through the four failure modes that decide the tier, the quantified thresholds for each, a four-question decision test you can run on Monday morning, the hybrid architecture most production systems actually converge to, and a vendor-evaluation playbook for the shortlist call.
Quick Digest
What you get: a failure-mode comparison framework, quantified switching thresholds tied to source count and anti-bot pressure, an original four-question decision test, a hybrid-architecture pattern, and a vendor-evaluation question list. What you do not get: a vendor ranking, a feature-by-feature comparison grid, or “depends on your needs” hedging. The four-question test in section five produces a tier recommendation you can defend in a 30-minute review with your CTO or CFO.
The Two Lanes: What Web Scraping Tools and Companies Actually Deliver
Before comparing them, we have to be precise about what web scraping actually is and what we are comparing. The phrase “web scraping companies” is loaded. It can mean a self-service platform you log into, an API you call from your code, a fully managed pipeline that delivers structured data to a bucket, or a data product where you buy the dataset directly. These are four different ownership models, and conflating them is the first mistake most evaluations make. If you want the wider category map before drilling into the tiers, the data extraction services overview lays out how these models fit into the broader 2026 services landscape.
The four ownership models, from highest internal ownership to lowest:
- Tools tier (DIY libraries and self-service platforms). You own selectors, proxy rotation, infrastructure, scheduling, schema validation, and quality assurance. The category includes open-source frameworks such as Scrapy, headless browser stacks such as Playwright, no-code scrapers, and cloud scraping IDEs.
- Scraping API tier. The vendor owns the request-layer infrastructure (proxies, anti-bot evasion, rendering). You still own extraction logic, schema, validation, retries, and delivery. Zyte is a well-known example here; if you are weighing it, our roundup of the best web scraping services and tools compared against Zyte maps the API-tier and managed options.
- Managed services tier. The vendor owns the full pipeline, including extraction logic, monitoring, schema management, and delivery validation. You own the consumption layer and any data-use compliance.
- Data-as-a-Service (DaaS). The vendor owns everything. You purchase pre-compiled data access on a subscription model.
The market that sits behind these tiers is real. Web scraping itself reached roughly $1.17 billion in 2026 and is on track to reach roughly $2.00 billion by 2030 at a 14.2 percent CAGR. The alternative-data market it feeds, where investment and trading firms are the dominant buyers, is now around $17.78 billion, with web-scraped data accounting for roughly 29 percent of the spend. Gartner predicts that by 2027, IT spending on multistructured data management will reach 40 percent of the total data-management budget, and the share of AI spend on data readiness will grow sevenfold from 2025 to 2029.
Tools optimize for self-service speed and control. Services optimize for reliability and operational accountability. The choice ultimately comes down to how much extraction automation your team can defensibly own end-to-end. APIs sit in the middle, replacing one layer (the request stack) without replacing the pipeline. When the decision is platform-specific, the same logic applies to choosing between managed, API, and self-serve scraping. None of these is universally “better.” They solve different problems at different volumes and stakes.
Expert Insights. Treat the four ownership models as a single decision axis rather than a continuum. The boundary between “tools” and “services” is sharper than it looks because the failure modes each tier exposes to your team are categorically different, not just bigger or smaller.
Quick Summary. Tools, APIs, managed services, and DaaS are four distinct ownership models. The right one depends on how many failure modes you can absorb internally and at what cost.
For a build-burden-focused take on the same comparison, see our companion piece.
The Four Failure Modes That Decide the Tier
Feature grids are a misleading axis because they catalog what each tier offers when everything works. Production scraping decisions are about what happens when things break. Across hundreds of production pipelines, the failures cluster into four categories. Every tier handles each category differently, and the cost of mismatching a tier to a failure mode is what shows up on your roadmap two quarters later.

1. Silent failures. The scraper keeps running. Requests return 200. Selectors still match. The dataset slowly degrades. A field that used to be populated comes back blank, or a price field captures the strike-through instead of the live price, or a regional result silently collapses into a generic page. The detection pattern is consistent across practitioner reports: silent failures are typically discovered days later through downstream reporting discrepancies, not by the monitoring stack itself. Even specialized scraping services routinely report success rates well below 100 percent on popular sites, with most of the gap attributable to soft failures rather than hard ones. This is the category that does the most damage because confidence in the dataset stays high while accuracy decays.
2. Schema drift. Sites change their markup. New fields appear. Types shift, often a number becomes a string. Old fields move under different parents in hydrated React or Next.js layouts. Your extraction logic keeps running, and downstream transforms keep going, but the meaning is now wrong. Roughly 70 percent of the modern web is JavaScript-rendered, which means schema drift is no longer an edge case. It is a recurring incident category, and reliable teams treat schema as a contract, not a suggestion.
3. Anti-bot escalation. This is the category that shifted hardest in 2024 and 2025. Cloudflare, Akamai Bot Manager, DataDome, HUMAN, and Imperva all rolled out machine-learning-based detection that collapsed datacenter-proxy success rates on the top thousand sites. Residential and ISP proxies are now table stakes for any aggressively defended target, and even these require coordinated rendering, fingerprinting, and behavioral analysis. Anti-bot is no longer a proxy problem. It is a stack problem.
4. Integration boundary breaks. Your delivery layer is not idempotent. Replays produce duplicates. The schema is right, but the consumer expects a different shape. The pipeline runs to completion, but downstream systems silently choke. This is the failure mode that gets the least attention in vendor pitches because it lives at the contract between your scraper and your data warehouse.
The numbers behind the maintenance reality:
- 30 to 60 percent of in-house engineering time is consumed by scraper maintenance at scale, depending on which industry source you read. Multiple practitioner surveys consistently report this band.
- 90 days is roughly the window in which production scrapers develop reliability problems.
- 12 to 18 months is the typical rebuild cycle for in-house scraping projects.
- Three to six times the initial build estimate is the realistic two-year true total cost of ownership.
- 10 to 20 engineering hours per week is what teams typically reclaim when they migrate from in-house scraping to managed services.
Expert Insights. The four failure modes are not weighted equally. Silent failures and schema drift compound because the dataset remains plausible while it rots, delaying detection by days. Anti-bot escalation is loud and obvious; integration boundary breaks are loud and embarrassing. Silent and drift are the ones that hurt your reputation with the consuming team.
Quick Summary. Four failure modes drive every tier decision. Silent failures and schema drift are the dangerous ones because they preserve the appearance of working pipelines. Anti-bot pressure is the one that has shifted most in the last two years. Integration boundary breaks live between your scraper and your warehouse.
For the deeper failure-mode catalog, see why pipelines break and why teams regret in-house.
When Web Scraping Companies Win: The Reliability Path
Once you accept that the comparison axis is failure-mode absorption, the services-tier value proposition becomes legible. You are not buying features. You are transferring four categories of operational risk to a vendor whose entire engineering organization is built around absorbing them.
Here is the absorption matrix that maps each failure mode to who handles it across the three tiers:

| Failure Mode | Tools tier (DIY) | API tier | Services tier (managed) |
|---|---|---|---|
| Silent failures | You own detection and fix | You own | Vendor owns, you verify |
| Schema drift | You own | You own | Vendor owns with SLA-bound recovery |
| Anti-bot escalation | You own (proxy plus render plus fingerprint) | Partial (request layer) | Vendor owns end-to-end |
| Integration boundary | You own | You own | Vendor owns delivery layer |
The services tier comes with table-stakes that are required by enterprise procurement: ISO 27001, SOC 2 Type II, GDPR, CCPA, and, increasingly, EWDCI (Ethical Web Data Compliance Initiative) attestations. The 2026 procurement reality is that compliance posture is risk transfer, not a certification scorecard. A vendor that holds the attestations absorbs the audit burden when your legal team raises a question. A vendor that does not, makes you the audit surface.
When does the math actually flip? The services tier wins on total cost of ownership when one or more of these conditions hold:
- More than 50 dynamic sources in active production rotation.
- Daily or sub-daily freshness requirements on any meaningful portion of those sources.
- Aggressive anti-bot exposure (Cloudflare standard tier or above, DataDome, HUMAN, fingerprinting).
- Data in the consumed product or decision path, not just internal analytics. The bar for reliability rises sharply when an external customer or a financial decision depends on the data.
- Regulated workloads where per-record provenance, audit trails, and jurisdictional handling matter.
Below those thresholds, the services tier is over-engineered. Above them, the tools tier silently runs up a maintenance bill that exceeds the subscription cost and shows up as engineering time you cannot reallocate. At that point the in-house build stops being data collection automation and starts being a permanent maintenance contract your team signed without realizing it.
For organizations that have crossed those thresholds, managed extraction services handle the absorption layer end-to-end: managed proxy and rendering escalation, completeness and freshness SLAs, per-record provenance, and dedicated reliability engineering that does not compete with your roadmap for attention. That is the actual deliverable. Everything else is implementation detail.
Expert Insights. Three SLA red flags to watch in services-tier evaluation. (1) An SLA that bounds only uptime, without completeness, freshness, or distribution metrics, is uptime theatre. (2) A vendor that cannot quantify completeness per source-tier is selling a feel. (3) A contract that lacks data-portability and exit clauses creates lock-in that makes the migration you are trying to make today harder to reverse later.
Quick Summary. Services-tier value is failure-mode absorption with operational accountability, backed by compliance posture that satisfies enterprise procurement. The thresholds where services-tier TCO beats tools-tier TCO are 50+ dynamic sources, daily-or-faster freshness, aggressive anti-bot, or data-in-product workloads.

For the services-tier shortlist, see our top services breakdown. For enterprise-scale evaluation, the enterprise buyer’s guide covers SLA structure, infrastructure, and compliance in more depth. For the underlying infrastructure question, see enterprise reliability.
When Web Scraping Tools Still Win
Counter-positioning matters here. The tools tier is genuinely the right answer for a meaningful set of cases, and pretending otherwise damages the credibility of every other section.
The tools tier wins when:
- Source count stays below ten. The maintenance overhead is small enough that a single engineer can keep the lights on without sacrificing strategic work.
- Targets are static or near-static. Older HTML pages, government data, simple e-commerce category pages without aggressive defenses. The schema-drift pressure is low and the anti-bot pressure is negligible.
- The use case is exploratory or short-lived. Proofs-of-concept, internal analytics on a handful of sources, dev/research scraping, one-off datasets to support a single decision. Buying a managed service for a temporary need is over-engineering.
- The data is not in the product or in a regulated decision path. The cost of an occasional silent failure is bounded.
- The team has, and will continue to have, dedicated capacity. A senior engineer with bandwidth, fluency in Python, BeautifulSoup, Playwright, and proxy management, who actually wants to do this work. That last clause is the one most teams get wrong.
A practical reference price for the tools tier is roughly $3.75 per thousand pages on hosted scraping APIs, with open-source frameworks effectively free at the platform level (real cost lives in proxies, infra, and engineering time). Adoption data tracks the practitioner reality: Python is used in roughly 70 percent of scraping stacks, and BeautifulSoup is the most-cited parsing library at around 43 percent, with Crawlee, Playwright, and Selenium clustered together as the dominant rendering options.
What makes the tools tier the wrong answer is not size by itself. It is the combination of size, anti-bot exposure, and stakes. If you score zero on three of the four questions in the next section, stay on tools.
Expert Insights. “We will graduate when we need to” is the most common operational debt pattern in this space. The signal that you needed to graduate already is usually visible six to nine months earlier in the rate of recurring four-to-six-week failure cycles per source. Watch the cycles, not the headcount.
Quick Summary. The tools tier is correct for under ten sources, static or near-static targets, weak anti-bot pressure, and use cases that are exploratory or have bounded reliability stakes. Below those bands, services-tier reliability is over-engineering.
For the manual baseline that tools improve on, see manual vs automated.
The Four-Question Decision Test
This is the section your CTO or CFO will use as the artifact when you defend the tier choice. The framework has four questions, each scored on a zero-to-three band, summed into a tier recommendation with one tie-breaker.
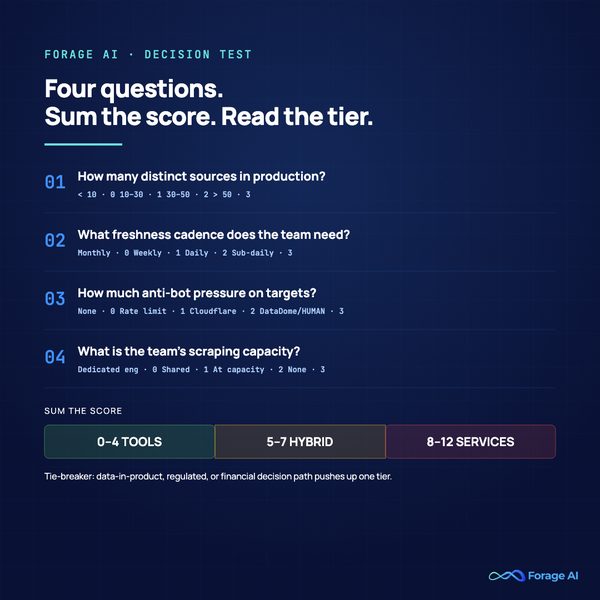
Question 1: How many distinct sources are you running in production?
- Fewer than 10 sources: 0
- 10 to 30 sources: 1
- 30 to 50 sources: 2
- More than 50 sources: 3
The threshold logic. Under ten, the maintenance overhead per source is absorbable. Above fifty, the surface area exceeds what a single engineer can keep current without sacrificing the rest of the data roadmap.
Question 2: What freshness cadence does your consuming team need?
- Monthly or slower: 0
- Weekly: 1
- Daily: 2
- Sub-daily (hourly or faster): 3
The threshold logic. Each freshness step roughly doubles the surface for failure detection. Daily extraction has to detect and recover from a schema-drift incident in under 24 hours, which is a different operational shape than monthly.
Question 3: How much anti-bot pressure are your targets putting on you?
- None or static HTML: 0
- Basic rate limiting only: 1
- Cloudflare standard, Akamai standard, or equivalent: 2
- DataDome, HUMAN, advanced fingerprinting, or behavioral detection: 3
The threshold logic. Anti-bot pressure is the failure mode that has shifted most in the last two years. A target that scored a 1 in 2023 may score a 2 or 3 in 2026 without any change on your end.
Question 4: What does your team’s scraping capacity actually look like?
- A dedicated scraping engineer with more than half their time available: 0
- A shared engineer with consistent capacity: 1
- A shared engineer at or near capacity: 2
- No dedicated engineering capacity: 3
The threshold logic. This is not a question about whether your engineers are capable. It is a question about whether your roadmap can absorb the variance.
Sum the four scores and read the recommendation:
- 0 to 4 points: tools tier. The maintenance burden is low, the stakes are bounded, and the team has capacity. Stay on the tools tier and invest in observability before you invest in vendor switching.
- 5 to 7 points: hybrid architecture. The next section is for you. Routing your hard sources to a services tier and keeping easy sources on tools is the cost-optimal end state.
- 8 to 12 points: services tier. The cumulative failure-mode exposure exceeds what an in-house tools-tier setup can sustainably absorb. The TCO math has flipped.
Tie-breaker. If any of the data flowing through the pipeline is in the product, in a regulated workload, or in a financial decision path, push the recommendation up one tier. The tail risk of a silent failure on data-in-product justifies the reliability premium.
Expert Insights. The most common scoring failure is reflexive maximization. Teams that want to justify a managed-services budget score everything 3; teams attached to their in-house build score everything 0. The test only works if you score honestly. If your gut answer differs from the test answer by more than two tiers, go back and recheck which question you flinched on.
Quick Summary. Four questions, scored 0 to 3, are summed into a tier recommendation. Score 0 to 4: tools. Score 5 to 7: hybrid. Score 8 to 12: services. Data-in-product or regulated workload pushes up one tier. The framework runs in about 15 minutes and produces an artifact you can review with your CTO.
For the broader build-vs-buy frame, see build or buy.
The Hybrid Architecture: Where Most Production Systems Land
If your test score falls in the 5-7 band, the answer is not “buy both vendors and hope.” It is to architect a routing layer that sends each source to the tier that fits it.
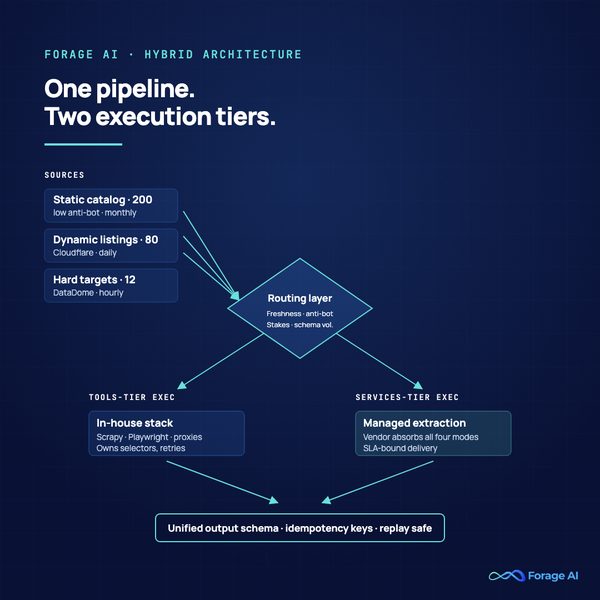
Hybrid is not a compromise. It is the cost-optimal end state for most teams with twenty or more sources. The reasoning is straightforward: paying services-tier prices for static, low-stakes sources is wasteful, and exposing high-stakes, anti-bot-protected sources to tools-tier maintenance is risky. Hybrid lets you pay for reliability where reliability matters and let speed and control dominate where they matter. The routing rule is really a policy for when to hand extraction to a managed provider versus keeping it in-house, applied source by source.
The architecture has three layers:
- Source classification and routing. Per-source metadata that captures freshness requirement, anti-bot tier, schema volatility, and stakes. Routing logic sends each source to the appropriate tier. This metadata is the architectural keystone; without it you have two parallel pipelines, not one architecture.
- Tier-specific execution. Tools-tier sources run on your in-house stack. Services-tier sources are handled by your managed vendor. Each tier produces records in a unified output schema.
- Unified output normalization. Both tiers feed a single schema contract that downstream consumers join against. Idempotency keys live at this boundary. Replay and dedup logic live here. Your warehouse only knows about the unified schema, not which tier produced any given record.
The migration path is the welcome surprise of this architecture. You can move sources up-tier as failure-mode pressure increases without rewriting your pipeline. A source that scored a 1 on anti-bot last year and a 3 this year graduates from tools to services with a routing-layer change, not a code rewrite.
Expert Insights. The 2026 trend that is starting to bite this section is agentic AI source classification. Several teams are now using LLMs to automatically score new sources against the four-question criteria and route them accordingly, compressing the human decision into a review step. Worth tracking, not yet table-stakes.
Quick Summary. Hybrid is the cost-optimal architecture for most production systems with 20 or more sources. Three layers: source classification and routing, tier-specific execution, unified output schema. Migration up-tier becomes a routing change, not a rewrite.
For the deeper architecture lens, see enterprise reliability.
The Vendor-Evaluation Playbook
Once the test points at the services tier or hybrid, you have a vendor selection problem. The vast majority of evaluations get sucked into feature-grid demos that showcase the easy 80 percent of the work and skip the production 20 percent that decides whether the vendor will survive your real workload. These six questions are designed to surface the production of 20 percent.
1. What is your completeness SLO per source-tier, and how is it measured? A vendor that can quantify completeness per tier (say, 99.5 percent for static sources, 98 percent for dynamic, 95 percent for aggressively defended) is operating like an engineering organization. A vendor that hedges or talks only about uptime is selling uptime theatre.
2. What is your median time-to-recovery on a schema-drift incident? This is the single best signal of internal reliability engineering maturity. Mature vendors track it as a primary SLO. Immature vendors will not have a number.
3. What does your audit trail look like per record? You should hear: URL captured, timestamp captured, access method captured, retention policy applied, all queryable from the consumer side. If the answer is “we have logs,” it is not enterprise-grade.
4. What is your anti-bot escalation playbook on Cloudflare and DataDome? The answer should describe layers (residential rotation, ISP fallback, browser fingerprint normalization, request-rate shaping) and decision criteria. If the answer is “our infrastructure handles it,” push for specifics.
5. What is the contract exit and data-portability clause? Mature vendors will already have this in the master agreement. Look for: 30-to-60-day exit notice, full schema export, no termination fee for SLA breach.
6. What is your typical onboarding time-to-stable for a 50-source pilot? The industry baseline is 2 to 4 weeks for a pilot and 6 to 12 weeks for a full production rollout. A vendor that quotes much faster is likely cutting corners on validation; one that quotes much slower is showing operational immaturity.
Expert Insights. Two questions to ignore in vendor calls: (1) how many proxies they have (volume is a feature, not an outcome) and (2) what Fortune 100 customers they have without quantified outcomes (logos are not SLAs). The substitute for both is a single reference call in which the customer discusses their last incident.
Quick Summary. Six evaluation questions optimized for surfacing operational maturity. Completeness SLO, schema-drift recovery time, audit trail, anti-bot playbook, exit clause, and onboarding time-to-stable. Skip the feature demo. Spend the whole shortlist call on these.
For the broader provider-selection lens, see B2B provider selection.
Frequently Asked Questions
When should we switch from a web scraping tool to a managed web scraping company?
When the source count crosses roughly 50 dynamic sources, when any source becomes data-in-product or regulated, or when anti-bot pressure escalates beyond standard rate limiting. The four-question test in section five is the systematic version of this answer. The earlier signal, before the test, is recurring four-to-six-week failure cycles on the same sources, which usually appear six to nine months before teams formally re-evaluate.
What is the real maintenance burden of in-house web scraping?
Industry estimates put it at 30 to 60 percent of relevant engineering time at scale, with the upper end of that band common in enterprise cohorts. Teams migrating from in-house to managed services typically reclaim 10 to 20 engineering hours per week. The hidden cost is not the absolute number; it is that the work is rarely strategic, which makes recruiting and retention harder.
What is the difference between a scraping API and a managed web scraping service?
Scraping APIs replace the request-layer infrastructure: proxies, rendering, and anti-bot evasion. You still own extraction logic, schema validation, retries, and delivery. Managed services replace the full pipeline, including extraction logic, schema management, and delivery validation. APIs absorb one of the four failure modes (anti-bot escalation, partially). Services absorb all four.
How long does onboarding to a managed scraping service typically take?
Industry standard is 2 to 4 weeks for a small pilot and 6 to 12 weeks for a 50+ source production rollout. The single best vendor-evaluation question is “What is your median time-to-stable on a 50-source pilot?” Vendors who quote much faster than two weeks are usually cutting corners on validation.
Can we use web scraping tools and services together?
Yes, and most production systems with more than 20 sources do. The hybrid architecture in section six routes hard or dynamic sources to services and static or low-stakes sources to tools, with a unified output schema underneath both. It is the cost-optimal end state for most teams once they pass the four-question test’s score-of-five threshold.
The Real Question Is Not Which Vendor
Stop comparing features. Compare failure modes. The right tier is not a vendor decision; it is an operational shape decision tied to your source count, your freshness needs, your anti-bot pressure, and your team’s capacity to absorb variance. Run the four-question test on Monday. The score will defend itself in front of your CFO, and the recommendation will hold up in front of your CTO.
The teams that get this wrong are not the teams that pick the wrong vendor. They are the teams that pick the wrong tier and then spend two years rationalizing the choice while the maintenance bill compounds and the silent failures eat into product credibility. The tier choice is the load-bearing decision. The vendor choice rides on top of it.