

A legal ops team at a mid-market BFSI firm moved 4,000 vendor contracts through a generic IDP pipeline last quarter. Clean extraction reports; 93% field match on the sample audit. Six months later, an intercreditor dispute surfaced a liability cap discrepancy: the extraction had captured the original cap, not the amended one from Amendment #2. The metadata never linked the amendment back to the parent agreement. Extraction accuracy on that field, by every dashboard metric, was 100%.
That failure pattern isn’t a tooling bug. It’s a structural limitation of how most IDP systems treat contracts. This article is for data-ops leads and engineering evaluators in legal ops, procurement, or compliance who already run contract extraction at scale and want to understand why the reliability gap they’re seeing is architectural, not configuration.
Quick Digest
- Contracts are the hardest document type to extract automatically. Five technical challenges break the generic IDP.
- Stanford RegLab 2024 research finds that general-purpose LLMs exhibit legal hallucination rates of 58–88%; even specialized legal AI hallucinates at 17–34%+.
- Purpose-built contract extraction requires four architectural layers, not a “legal mode” toggle on a generic tool.
- A 7-question evaluation matrix at the end lets you audit any contract extraction system, including your own.

Why Contracts Are the Hardest Document Type for Extraction
Every top-ranking article on contract data extraction treats contracts as a generic IDP use case. Invoices, receipts, reports, and contracts all become “unstructured documents” handled by the same OCR + NLP pipeline. However, generic pipelines fail to correctly reconcile amendments to parent agreements, leading to missing or incorrect metadata.
The reality is different. Invoices follow templates. Receipts are short and consistent. Forms have fixed fields. Contracts have none of those anchors. Contracts are negotiated. Layouts vary by counterparty. Signed contracts. Scanned copies often have faded toner, double-sided bleed-through, and handwritten margin notes. Amendments may reference the original by number, not by inclusion, so the governing value for any field can be separated from the main document.
The economic stakes match the structural complexity. The International Association for Contract and Commercial Management (IACCM, now World Commerce & Contracting) puts contract value leakage at an average 9% of annual revenue, with best-in-class companies at 6.2% and the rest at 12.4%. Corporate legal GenAI adoption more than doubled in one year, from 23% in 2024 to 52% in 2025 (ACC + Everlaw Generative AI’s Growing Strategic Value for Corporate Law Departments 2025). And per Gartner 2026, 50% of CLM implementations are still failing.
What Top Articles Get Wrong About Contracts
The common vendor framing, “AI reduces contract review time by 50%,” treats extraction as a speed problem. It isn’t. It’s an accuracy-under-semantic-complexity problem. A system that extracts faster but misses the amended liability cap is worse than manual review, because it fails with false confidence. This failure mode isn’t unique to legal ops; the insurance-claims parallel shows the same dynamic, where extraction pipelines confidently process claims while missing the rider or endorsement that determines the actual payout.
Worth knowing:
- 59% of CLOs report workloads increased year-over-year; 28% of legal professionals rate contract review as the most impactful AI use case (2026 industry surveys)
- Deloitte + World Commerce & Contracting research puts average contract value erosion at 8.6% of total spending, tied directly to extraction and tracking gaps.
- IACCM finds 40% of contract value leakage is attributed to poor management practices, most of which trace to data-quality issues at the extraction layer
Why is contract extraction harder than invoice or receipt extraction?
Invoices follow templates, and receipts are short and consistent. Contracts are negotiated (variable layout), signed (degraded files), amended (cross-document linkage), and written in legal terminology, where the same word can carry different meanings across jurisdictions. No single component of a generic IDP stack handles those four realities simultaneously. For the templated end of the spectrum, see how AP teams approach this when invoices flow through purpose-built extraction.
The Five Technical Challenges Unique to Contracts
This article uses a named framework. Every remaining H2 maps to one of these challenges.
| # | Challenge | What breaks generic IDP |
| 1 | Variable Layouts | Negotiated contracts differ per counterparty; templates fail on non-standard structures |
| 2 | Nested Clauses | Sections within sections, recursive definitions, sub-sub-clauses with exceptions |
| 3 | Cross-References | “As defined in Section 4.3” requires resolving the reference, not just capturing the text |
| 4 | Amendments | Amendment #2 modifies the parent agreement by reference; without linking, parent metadata stays stale |
| 5 | Legal Terminology | “Reasonable efforts” ≠ “best efforts” ≠ “commercially reasonable efforts”; jurisdiction-specific meanings |
What Generic Tools Claim to Solve vs What They Actually Solve
Vendors often claim that “AI-powered extraction handles legal documents.” Most tools solve two of the five challenges. Enhanced OCR handles variable layouts at the pixel level. General-purpose LLMs process legal terminology to a limited extent. Neither system handles cross-references, amendments, or nested-clause semantics without explicit architectural support.
Gartner’s 2026 finding that 50% of CLM implementations fail stems from this. The failure isn’t the CLM platform. It’s the extraction feeding it. A clean CLM system on dirty extraction data is a well-organized archive of wrong numbers.
Worth knowing:
- The five challenges compound rather than add. A contract that combines variable layout with amendments is harder than either challenge individually.
Which of the five challenges breaks extraction most often?
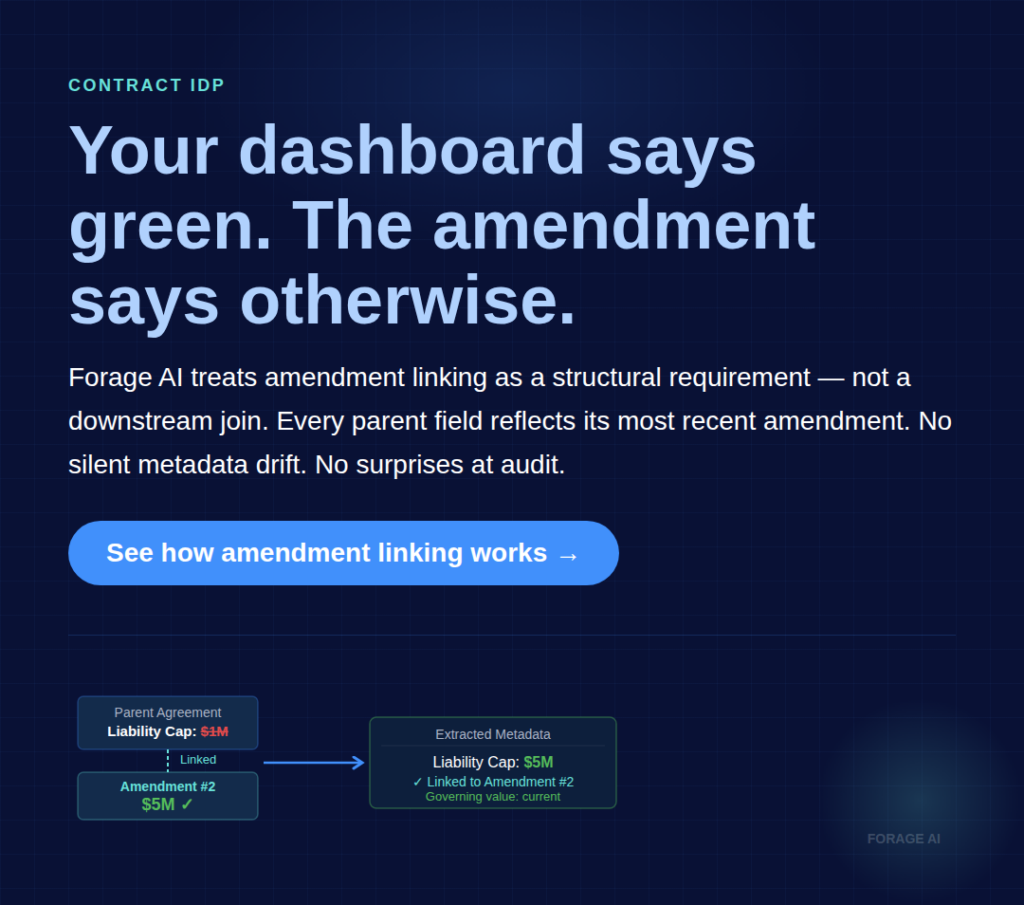
Amendments. Teams that capture amendments but don’t structurally link them to parent agreements experience silent metadata drift. Dashboards look right. The audit surfaces the gap months later.
Why Generic IDP and General-Purpose LLMs Fail on Contracts
Generic IDP was designed for invoices, receipts, and forms that share significant template overlap. General-purpose LLMs were trained on broad web corpora with minimal filtering for legal domains. Neither was designed for contracts.
The Stanford Evidence
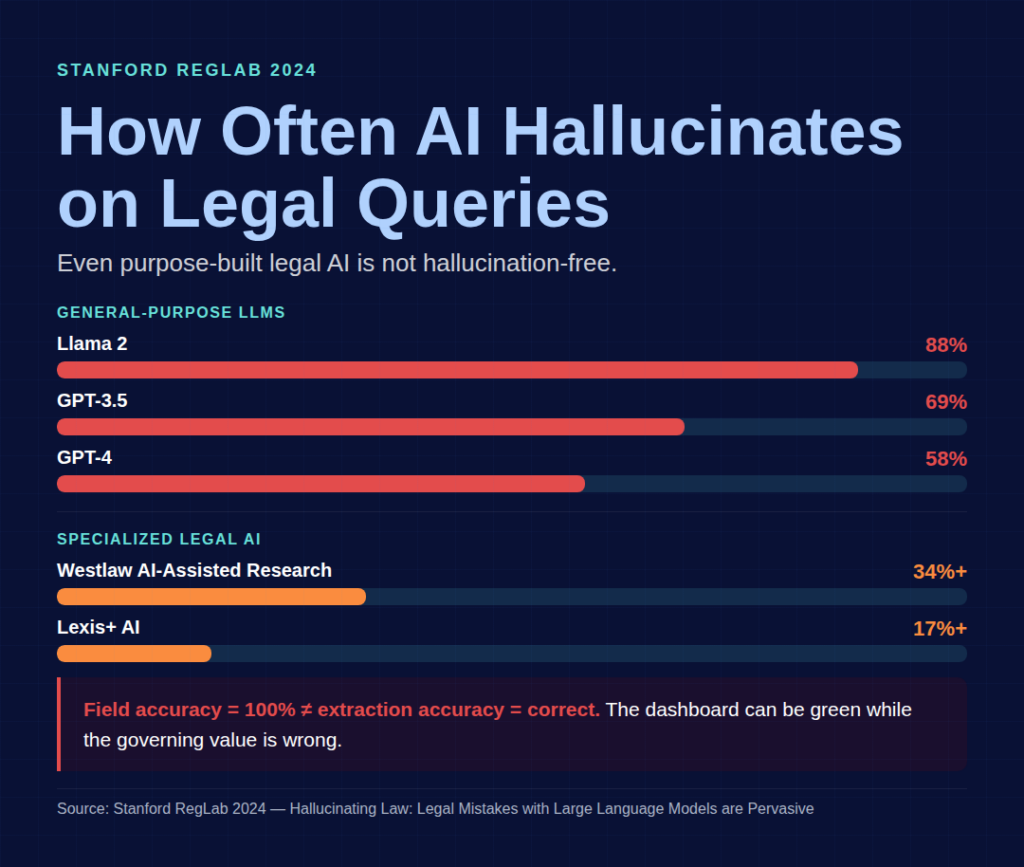
The definitive research comes from Stanford RegLab and Stanford Institute for Human-Centered AI. Their 2024 study, Hallucinating Law: Legal Mistakes with Large Language Models are Pervasive, found legal hallucination rates of 69% for GPT-3.5, 58% for GPT-4, and 88% for Llama 2 on specific legal queries. The follow-up paper, Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, tested specialized legal AI tools: Lexis+ AI and Ask Practical Law AI hallucinated more than 17% of the time; Westlaw’s AI-Assisted Research hallucinated more than 34%.
The paper also notes: “Most LLMs performed no better than random guessing in tasks measuring the precedential relationship between two different cases.” Legal reasoning is fundamentally harder than pattern matching, even for well-trained, purpose-built tools.
The accuracy gap between purpose-built and general-purpose systems also shows up in clause-extraction benchmarks. 2026 industry benchmarks consistently show purpose-built contract extraction at ~94% clause accuracy vs ~85% for general-purpose LLMs on the same test sets.
The Amendment Cross-Reference Failure
The most common silent failure mode: Amendment #2 changes a liability cap from $1M to $5M. The extraction system captures Amendment #2 as its own document, correctly extracts the new $5M value, and stores it. The parent agreement’s extraction still shows $1M. Without explicit amendment-to-parent linkage as a first-class extraction output, your metadata shows the wrong number.
The system reports success on both documents. The dashboard is green. The error surfaces when the dispute does.
What Field Accuracy Doesn’t See
Confidence scores in individual fields can be high even when the meaning is wrong. An extractor can correctly identify “the liability cap is $1M” in the parent agreement and be structurally correct about what the sentence says, yet be operationally wrong because the governing value has been amended. Field accuracy is not the same as extraction accuracy. For how this propagates downstream into review queues, approvals, and broader process automation, see the operations side of this.
For the OCR-vs-IDP distinction underlying this, see OCR vs IDP — Why Intelligent Document Processing Is the Future.
Worth knowing:
- Stanford 2024: specialized legal AI systems are not hallucination-free. Even Lexis+ and Westlaw fail 17–34%+ on legal research.
- Jones Walker 2026 legal prediction: “Legal will own AI policy, compliance, information security, and privacy,” raising the bar for extraction systems feeding legal workflows
- The cost of a missed clause commonly exceeds $6,900 (IACCM per-contract review cost estimate), making human-in-the-loop economically justified at far lower error rates than generic IDP produces
Can ChatGPT analyze a contract accurately?
For internal review or summarization tasks with heavy human oversight, sometimes. For production extraction, feeding compliance or contractual workflows, no. Stanford’s 58–88% hallucination rates on legal queries mean you’re effectively running a 40–60% error-rate system without guardrails.
What Purpose-Built Contract Extraction Actually Looks Like
Purpose-built extraction is not a “legal mode” toggle on a generic tool. It’s a layered architecture designed for the specific challenges mentioned above.
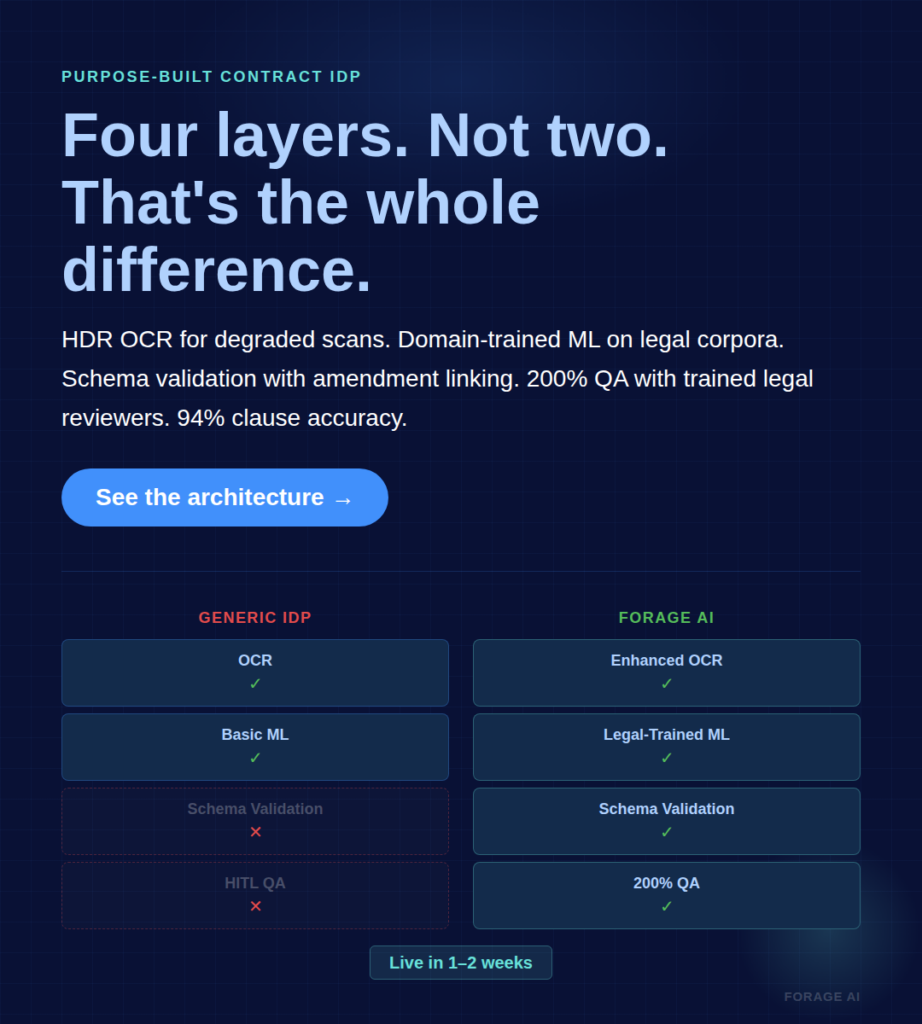
The Four Architectural Layers
Layer 1: Enhanced OCR. Not just text recognition. HDR image processing for faded text and handwritten annotations common in signed scanned contracts. Standard OCR reports ~95% character accuracy on clean business documents and drops to 85–94% on faded or aged scans, with steeper drops on sub-300 DPI or skewed scans (industry benchmarks); enhanced OCR closes most of that gap.
Layer 2: Domain-trained ML for clause classification and entity extraction. Legal-grade Named Entity Recognition distinguishes “governing law” from “venue,” “reasonable efforts” from “best efforts.” Models trained on legal corpora rather than general-web corpora. Clause classification treats indemnification, limitation of liability, and termination rights as first-class entities with their own schemas.
Layer 3: Schema validation at extraction time. Every extraction is validated against a declared schema before writing. Cross-reference resolution as a first-class check. Amendment linking as a structural requirement, not a downstream join. If the schema fails, nothing is written.
Layer 4: Human-in-the-loop validation. Covered in detail in the Layered QA section below. For contracts, this is architectural, not optional.

Practical Example: Forage’s IDP Architecture
Forage’s IDP Pillar is a working example of this architecture. 95% table-detection accuracy across all table types, including fee schedules, SLA tables, and nested pricing structures that break generic extraction. Document handling over 2,000 pages supports master service agreements and M&A data rooms. HDR OCR handles the scanned-signed-contract reality. Reinforcement learning from human feedback improves extraction with every correction, so the pipeline gets better on specific contract types over time.
What “AI-Powered Contract Extraction” Does Not Guarantee
Labeling a tool “AI-powered” does not guarantee legal-domain training, schema validation, or human review. “AI” is a capability marketing claim. What matters architecturally is whether the four layers are present and distinct. A pipeline that collapses them into “run the LLM and hope” is a Tier 2 extraction system with better branding.
For the underlying IDP technology deep-dive, see IDP Solutions Leveraging the Latest AI and Decoding Data Extraction — Forage AI’s IDP System Solutions.
Worth knowing:
- 2026 ContractEval and similar benchmarks are standardizing clause-extraction measurement; expect to see F1 scores rather than “accuracy” claims in vendor materials this year
- Template-based extraction is Layer 2 pretending to be purpose-built. It works with documents that match known layouts, which most negotiated contracts don’t.
What’s the difference between generic IDP and purpose-built contract extraction?
Generic IDP handles templated documents (invoices, receipts) well. Purpose-built contract extraction handles variable layouts, cross-references, amendments, legal terminology, and file degradation across four architectural layers, versus one or two in a generic IDP.
Handling the Hardest Contract Types
Enterprise contracts aren’t clean native PDFs. They’re signed, scanned, faxed, refiled, amended, and OCR’d from whatever source happened to be closest to a scanner. The extraction pipeline that looks great on a demo often breaks on the archive.
The File-Degradation Reality
Signed contracts arrive with faded toner, skewed scans, double-sided bleed-through, and handwritten margin notes or initialed corrections. Standard OCR reports ~95% character accuracy on clean business documents and drops to 85–94% on faded or aged scans, with steeper drops on sub-300 DPI or skewed documents (industry benchmarks). Enhanced OCR with HDR image processing closes most of that gap; low-confidence extractions route to human review.
Handwritten annotations need a separate classification layer. Is a handwritten margin note a material change to an obligation, or a signature-block flourish? A generic OCR pipeline treats both as text. A purpose-built pipeline classifies them and routes them accordingly.
Master Service Agreements and M&A Data Rooms
Master service agreements run 500–2,000+ pages with exhibits, schedules, amendments, and side letters. Standard extraction pipelines break at the ~200-page limit imposed by context windows and processing timeouts. Chunked processing with cross-chunk reference resolution is required; without it, the pipeline extracts cleanly in pieces, missing relationships.
M&A data rooms compound the problem: thousands of contracts under a 3–6 week deadline with portfolio-wide analysis requirements. At IACCM’s $6,900 per low-risk contract for two hours of manual review, a 5,000-contract data room costs $34.5M at legal rates. Automated extraction is the only economically viable path, provided the extraction system can actually handle the scale.
For the technical mechanics of table extraction specifically, see Tabular Data Extraction from PDF.
What Standard OCR Stacks Miss
Faded scans, handwritten annotations, cross-page references, footnotes in amendments, and initialed changes mid-paragraph. These aren’t edge cases. In enterprise contract archives, they’re the silent 20% that gets routed back to manual review by a pipeline that looks automated.
Worth knowing:
- Growing 2026 M&A deal volume is creating sustained pressure on contract-extraction capacity across the Finance and Tech sectors.
Can AI handle handwritten annotations on signed contracts?
Yes, with the right stack. HDR OCR handles most printed and neatly written annotations; a separate classification layer distinguishes material changes from signature-block marks; low-confidence extractions route to human review. Cursive handwriting and heavily degraded margins still require expert validation. Standard OCR stacks miss this entirely.
Layered QA: Why Contract Extraction Requires Human-in-the-Loop Architecture
For a contract, the cost of a wrong extraction isn’t a bad dashboard. It’s a missed renewal, a wrong obligation booked to the P&L, or a failed audit. Layered QA (automated validation plus human expert review) isn’t a feature choice. It’s an architectural requirement for legal stakes.
The Five-Layer QA Stack
- Automated extraction with confidence scores per field
- Schema validation at write time (the Pydantic/Zod discipline from Layer 3 above)
- Confidence-threshold routing, where low-confidence extractions queue for human review
- Human expert validation by trained legal QA reviewers, not generalists
- Feedback loop, where every correction feeds back into the model (RLHF)
Forage runs this architecture at a scale most vendors can’t match. Every extraction passes through automated checks and human expert verification, a 200% QA approach. The QA team is three times the industry average for its size relative to the delivery team. Feedback loops compound over 12 years of contract domain expertise. For high-stakes contracts, that ratio isn’t excessive. It’s the minimum viable bar.
Why Layered QA Only Works at Scale
A dedicated legal QA team requires volume. One reviewer typically validates several dozen contracts per day, depending on the complexity of the clauses and the depth of review required. Feedback loops require enough correction volume to improve model accuracy. Organizational separation between extraction operators and QA reviewers requires staffing that smaller vendors can’t sustain. This is why “AI + human review” as a bullet point often doesn’t survive contact with production.
For a deep dive into the HITL architecture, see Human-in-the-Loop Data Extraction.
What “Human-in-the-Loop” Doesn’t Mean
Having a lawyer glance at low-confidence outputs once in a while is not HITL architecture. HITL requires explicit routing rules, trained reviewers, and closed-loop feedback. Without all three, you’re running occasional human spot-checks on a pipeline that still writes wrong data to storage by default.
Worth knowing:
- IACCM charges ~$6,900 for low-risk contract review, including 2 hours of legal time. At portfolio scale, this is what automated extraction replaces; at production-failure scale, it’s the floor on remediation cost.
- Industry best-practice (consistent across 2026 analyses): AI handles 80–90% of ongoing contracts; humans review legacy documents and complex terms
Do I really need human review for every extraction?
No. You need confidence-score routing that sends low-confidence extractions to trained human reviewers and feeds corrections back into the model. Reviewing every extraction is wasteful; reviewing none of them is reckless. The architecture is between the two.
Compliance Architecture: SOC 2, GDPR, HIPAA, and the EU AI Act
Contracts contain the most regulated data enterprises handle: PII, financial obligations, PHI, intercompany agreements, and party identifiers. Extraction systems processing contracts inherit all of that regulatory scope.
What 2026 Compliance Actually Requires
SOC 2 mandates access controls, audit logging, and encryption at rest and in transit. GDPR covers data subject rights, the right to deletion, and lineage tracking for cross-border data. HIPAA applies to PHI in healthcare provider agreements and insurance contracts. And the EU AI Act’s remaining provisions apply from August 2, 2026, with penalties up to €15M or 3% of global annual turnover for high-risk AI violations (rising to €35M or 7% for prohibited AI practices, per DLA Piper’s 2026 enforcement analysis
Extraction systems feeding high-risk AI need automatic tamper-resistant logging, Article 11 technical documentation tying each output to source material and model version, and transparency obligations to downstream deployers. Raconteur’s 2026 audit guide puts it directly: “In the 2026 compliance environment, screenshots and declarations are no longer sufficient. Only operational evidence counts”
How Compliance Shapes Extraction Architecture
Encryption keys must operate in the extraction pipeline, not just the warehouse. Audit trails must tie every extracted field back to the source page, model version, confidence score, and (where applicable) the human reviewer who validated it. On-premises deployment must be available for clients with data residency requirements, which are common in BFSI and Healthcare. Data not for resale must be contractual: client data must never be used to train models for other clients.
Forage operates SOC 2, GDPR, and HIPAA-compliant IDP workflows with built-in validation, audit trails, and encryption. On-premise deployment is available for sensitive data environments.
Compliance Gaps in Generic IDP
Most general-purpose IDP platforms treat compliance as configuration: toggle on encryption, check a SOC 2 box, done. The gaps show up in audit granularity (can you trace a specific field back to a specific model version?), data subject rights support (can you actually delete PII from training data?), and tamper-resistance of logs (are they cryptographically signed?). For regulated industries, these are hard failures under the 2026 audit frameworks.
Worth knowing:
- Jones Walker 2026 predicts legal ops will own AI governance across the enterprise, advantaging in-house teams with context over outside counsel.
- €15M or 3% turnover is the relevant penalty tier for contract extraction feeding high-risk AI. Don’t plan around the larger €35M/7% number, which applies only to prohibited practices.
What compliance do I need for automated contract extraction in 2026?
SOC 2 for access controls and audit logging, GDPR for data subject rights (including in-scope contract data), HIPAA for regulated healthcare contracts, and EU AI Act Article 11 if extraction feeds high-risk AI deployed to EU users, including tamper-resistant logs and source-to-output lineage.

Industry-Specific Patterns: Finance, Healthcare, Real Estate
Contract extraction patterns differ by industry because contract types, compliance scope, and failure costs vary.
Finance/BFSI
Contract portfolio: loan documents, KYC packages, indenture agreements, intercreditor agreements, ISDA master agreements. Key fields: covenants, rate provisions, collateral descriptions, cross-default triggers, governing law. The hardest part is rarely the loan document itself. It’s the stack of amendments, assignments, and intercreditor agreements that modify it. Volume driver: regulatory reporting (CCAR, Basel, FRTB) plus the M&A pipeline. For the broader financial services landscape, see Top 10 Document Processing Solutions for Financial Services 2026.
Healthcare
Contract portfolio: insurance provider agreements, clinical trial agreements, pharma licensing, value-based care contracts. Key fields: procedure code references, HIPAA-protected identifiers, quality metric thresholds, termination triggers. Failure cost combines compliance risk (PHI exposure) with revenue risk (missed quality metrics → reimbursement loss). Generic extractors misclassify procedure-code references as plain text. For the strategic framing, see AI-Powered Document Processing Builds a Defensive Moat in Healthcare.
Real Estate
Contract portfolio: commercial leases, ground leases, deeds of trust, purchase agreements, and management agreements. Key fields: rent escalation clauses, option-to-renew, CAM reconciliation formulas, recording metadata, and legal descriptions. Failure cost: missed renewal option → lease lost on unfavorable terms; legal description error → title dispute.
Why Cross-Vertical Templates Don’t Work
A lease isn’t a loan document. A provider agreement isn’t a licensing agreement. Fields to extract and failure modes differ even within a single regulatory framework. Vendors that market “one contract extraction model fits all verticals” are either running a very generic pipeline or overselling.
Worth knowing:
- Domain-trained models compound over time via RLHF. The more contracts a system processes in a vertical, the better it gets at that vertical’s specific patterns.
Does vertical specialization actually matter for contract extraction?
Yes. Expect a 10–20 percentage-point accuracy gap between vendors with vertical-specific training data and those running one-size-fits-all models. The gap is largest on industry-specific failure modes, not generic fields.
How to Evaluate a Contract Extraction System
The evaluation matrix. Use this to audit your current system or any system you’re considering.
The Seven-Question Evaluation Matrix
- Variable layouts: Does the system maintain contract accuracy across 10 different counterparties without reconfiguration?
- Cross-references: When a clause references “Section 4.3” or “Exhibit B,” does the extracted metadata resolve the reference or just capture the text?
- Amendments: When Amendment #2 changes a field in the parent, does the extracted metadata reflect the amended value?
- Clause classification: Does the extractor distinguish “governing law” from “venue” and “reasonable efforts” from “best efforts”? Is it trained on legal corpora specifically?
- Document-degradation handling: Can the system handle scanned physical copies with faded text and handwritten annotations? What’s the accuracy on documents over 500 pages?
- Layered QA: Does every extraction pass through both automated validation AND human expert review? Are confidence scores routed to a trained legal QA reviewer?
- Compliance evidence: Can the system produce tamper-resistant audit logs tying every extracted field to source page, model version, and reviewer? Is on-premise deployment available for regulated data?

How to Interpret Your Score
- 7/7: Production-ready for high-stakes contracts.
- 5–6/7 with gap on #3 or #4: Generic IDP pretending to be contract extraction. Amendments and clause classification are the most expensive gaps to retrofit.
- 3–4/7: Template-based or OCR+LLM pipeline. Works on clean standard contracts; breaks on negotiated ones.
- 0–2/7: A general-purpose tool being used for contracts. High-risk. Immediate remediation is recommended before the next audit cycle.
Why Vendor Demo Scores Don’t Match Production Reality
Demo contracts are usually clean native PDFs of standard agreements. Run your own test set of degraded scans, negotiated counterparty contracts, and amended documents to see the real score. A system that hits 7/7 on clean demos and drops to 3/7 on your archive is not evaluating as advertised.
Worth knowing:
- For EU AI Act audit preparation, question #7 is the one most teams fail first. Tamper-resistant logging is rarely present in a generic IDP.
When should I replace my current contract extraction system vs. augment it?
If you score 5–6/7 with gaps only in compliance evidence or QA, augment. Those can be bolted on. If the gaps are in amendments or clause classification, replace. Those require architectural changes that retrofit poorly.
Related Articles
- A Comprehensive Guide to Intelligent Document Processing — Foundational IDP reference for readers new to the technology stack.
Frequently Asked Questions
What is contract data extraction?
Contract data extraction is the automated identification and structuring of key information from contracts (parties, dates, obligations, renewal terms, liability caps, clauses) into queryable metadata. In 2026, it spans five technical challenges — variable layouts, nested clauses, cross-references, amendments, and legal terminology — that generic IDP systematically misses.
Can ChatGPT analyze a contract accurately?
For summarization with heavy human oversight, sometimes. For production extraction, no. Stanford RegLab 2024 measured legal hallucination rates of 58% for GPT-4, 69% for GPT-3.5, and 88% for Llama 2 on specific legal queries. Even specialized legal AI tools like Lexis+ and Westlaw still hallucinate 17–34%+.
What’s the difference between generic IDP and purpose-built contract extraction?
Generic IDP handles templated documents (invoices, receipts). Purpose-built contract extraction handles variable layouts, cross-references, amendments, legal terminology, and file degradation across four architectural layers: enhanced OCR, domain-trained ML, schema validation, and human-in-the-loop. Generic IDP typically runs one or two of those layers.
How accurate is AI at extracting data from contracts?
Purpose-built contract extraction hits roughly 94% clause accuracy on 2026 benchmarks; general-purpose LLMs plateau around 85%. Accuracy varies by contract type, counterparty variance, and presence of amendments. It’s lowest on negotiated contracts with amendments and highest on clean standard templates.
How do you handle contract amendments and cross-references?
The amendment linking must be a structural requirement of the extraction schema: metadata points from the child amendment to the parent agreement, and the governing value for any field reflects the most recent amendment. Cross-references require explicit resolution logic. “As defined in Section 4.3” must be followed and resolved, not just captured as text.
Can AI handle handwritten annotations on signed contracts?
Yes, with the right stack. HDR OCR handles most printed and neatly written annotations. A separate classification layer distinguishes material changes from signature-block marks. Low-confidence extractions route to human review. Cursive handwriting and heavily degraded margins still require expert validation. Standard OCR stacks miss this entirely.
What compliance do I need for automated contract extraction in 2026?
SOC 2 for access controls and audit logging. GDPR for data subject rights and lineage. HIPAA for regulated healthcare contracts. EU AI Act Article 11 if extraction feeds high-risk AI deployed to EU users, including tamper-resistant logs and source-to-output lineage. Penalties for high-risk AI violations range from €15M to 3% of global turnover.




