

A property adjuster opens her queue on Monday morning. There are 142 active files. Forty-eight of them touched her inbox over the weekend: a first notice of loss from a state she rarely sees, three demand packages from plaintiff counsel, a stack of medical records from a bodily injury claim, photo evidence sent from a contractor’s phone, and the usual procession of repair estimates and ACORD forms. She has not started a single adjudication. She is already behind.
This is the operational reality that claims processing automation is supposed to fix. The promise sounds clean: ingest every document, extract the structured data, validate it against policy and coverage, and route only the exceptions to a human. The promise is also where most automation projects quietly fail. Not because the technology cannot extract, but because the technology that does extract often cannot defend its output to a regulator, cannot keep medical records inside the carrier’s data perimeter, and cannot survive the form variations that real claim files throw at it.
This article is for the claims operations director who has already tried tooling, hit a wall, and now has to build a case strong enough to convince a CFO, a compliance officer, and a state regulator at the same time. We will cover what claims processing automation actually is, the document types that break templated approaches, the audit trail you need before regulators ask, and the IDP-plus-expert-QA pattern that makes the whole stack defensible.
Quick Digest
- The bottleneck is upstream of adjudication, not at it. Roughly 80% of claims organizations cite document handling as the top friction point (LexisNexis, 2024); the median P&C adjuster carries 100 to 150 active files.
- Five document types break templated OCR every time: FNOL packets, ACORD variants (100+ forms), medical records, demand packages, and police reports with photo evidence.
- Top-quartile carriers process 60 to 70% of property claims straight through; the bottom half stay under 30%. The gap is a document-handling and exception-routing problem, not a model problem.
- The defensible architecture is layered: enhanced OCR, ML extraction, rule-based validation, human-in-the-loop QA, and write-back into the claims system. No single layer carries the accuracy on its own.
- Regulators ask for field-level audit trail, not document-level logs. NAIC market conduct exams run on 18 to 24 month cycles and expect chain-of-custody on every decision-relevant field.
- Automate the work around adjudication, never adjudication itself. Coverage interpretation, reserve setting, and settlement negotiation stay with humans.
- Data sovereignty is the swing factor. Most IDP SaaS routes medical records through third-party LLMs. For PHI, that fails the legal review before it fails the technical one.
- The CFO case rests on loss adjustment expense, leakage recovery, and cycle-time-driven retention, not on speed. Discount first-year ROI by 40 to 50% to absorb the realistic ramp.
- Seven evaluation criteria separate partners that hold up from partners that demo well: accuracy reporting, audit trail granularity, data sovereignty, form coverage, QA model, integration, and partnership shape.
Why claims processing is the operational bottleneck of modern insurance
The median property and casualty adjuster carries 100 to 150 open files at any time, according to Insurance Information Institute industry surveys. In a normal quarter, this is a heavy but manageable workload. In a catastrophe quarter, hurricane season, hailstorm cluster, wildfire complex, it doubles or triples within days, and there is no labor pool that can absorb the spike.
The bottleneck is not adjudication. It is everything that has to happen before adjudication can begin. LexisNexis Risk Solutions, in its 2024 Future of Claims research, found that roughly 4 out of 5 claims organizations identify document handling as the single most-cited friction point in their workflow. Every FNOL packet, every police report, and every demand letter must be opened, classified, keyed, validated, and routed before an adjuster can make a coverage decision.
The downstream cost is not just slower payouts. It is leakage from missed deductibles, reservation errors, regulatory exposure when statutory clocks expire, and reputational damage when a customer’s claim sits in a queue for three weeks because a fax was illegible. Carriers usually meet this with one of two responses: hire more adjusters or buy a tool that promises straight-through processing. Both responses are correct in the abstract. Both fail to execute when the volume curve and the document variability curve are steeper than the operating model can handle.
This is the Scale Wall in insurance. It is not a technology problem. It is a moment when manual work plus light tooling stops scaling, and the carrier has to decide whether to industrialize the front of the claims function or accept structural underperformance.
Expert Insight. The hidden multiplier in claims operations is statutory clocks. Many states require acknowledgment within 10 to 15 days and a coverage decision within 30 to 40 days. A backlog that delays intake by two days does not just slow payouts; it pushes a measurable share of files into Unfair Claims Settlement Practices Act territory before the adjuster even opens them.
Quick Summary. “Why is claims the operational bottleneck?” Because adjudication is the visible step but document handling is the binding one. When 80% of organizations name it as their top friction point and adjusters carry 142-file queues, the math says the front of the funnel is where the program lives or dies.
What claims processing automation actually is (and what it isn’t)
Definition. Claims processing automation is the combination of intelligent document processing, business rules, and human-in-the-loop review that converts unstructured claim documents into validated structured data, routes exceptions, and writes back to your claims system of record. It is not a chatbot adjudicating coverage, and it is not an end-to-end black box.
A working definition: Claims processing automation is the layer of software, workflow orchestration, and quality assurance that turns the unstructured artifacts of a claim, forms, scans, emails, photos, and free-text narratives into trustworthy structured records inside the claims system of record. It covers intake classification, field-level extraction, business-rule validation, exception routing, and write-back to the policy administration or claims management platform.
What it is not: a system that decides whether to pay a claim. Coverage determination, reserve setting, and final adjudication remain in human hands for almost every meaningful line of business, and they should. Automation belongs in the document handling, data extraction, and orchestration layers around the adjuster’s judgment, not on top of it. The mechanics here mirror the invoice automation pattern in accounts payable: capture, extract, validate against a ruleset, route only the exceptions to a human, and write back to a system of record. Different document family, same operating discipline. Readers new to the underlying technology will get a faster orientation from our OCR vs IDP comparison guide; the rest of this piece assumes you already know why plain OCR is not enough.
Expert Insight. The cleanest definitional line we use with carrier teams: if the system would ever say “this claim is approved” without a human signing off, it is out of scope. If the system says “this claim is ready for an adjuster, here is the validated data and the flagged exceptions,” it is in scope. The boundary is the decision, not the document.
Quick Summary. “Is claims automation about replacing adjusters?” No. It is about removing the document handling, classification, and validation work that surrounds adjusters so the human spends time on judgment, not on keying ACORD forms.
The five document types that break templated OCR every time
Most claims automation pitches show a clean ACORD form being read correctly and call it a day. Real claim files are messier than the demo. These five document types are where templated extraction stops working and where the gap between accuracy claims and field performance becomes apparent.

- First notice of loss forms. FNOL packets are a mix of structured fields, handwritten annotations, and free-text narratives. The narrative is where coverage triggers live (“water came through the roof”) and where templated OCR drops the most signal.
- ACORD forms. The ACORD standards family includes more than 100 form-level and field-level variants across personal lines, commercial lines, and certificates. Carriers customize the forms further. A model trained on one variant degrades silently when the variant rotates.
- Medical records. Bodily injury claim files include physician notes, lab reports, imaging summaries, and billing records. Pages mix handwriting, tables, and stamps. HIPAA requirements are displayed on every page. This is the document family where third-party LLM routing becomes an immediate compliance problem.
- Demand packages and itemized invoices. Plaintiff demands bundled packages of medical bills, repair estimates, and supporting invoices that must be reconciled line by line. This is the exact use case where the best invoice data extraction tools have to live inside the claims stack, not as a separate tool, but as part of the same extraction layer.
- Police reports and photo-derived evidence. Multi-page police reports include diagrams, witness statements, and accident codes. Photo evidence carries metadata and increasingly informs damage estimation. Both require multimodal extraction, and both are where most pure-text IDP systems quietly give up.
Templated extraction works on the document that does not vary. Claims documents always vary.
Expert Insight. The accuracy benchmark we trust on claim files is field-level, per document family. Document-level accuracy hides the fact that the easy fields are perfect and the hard fields (handwritten injury narrative, multi-line demand totals) are 60 percent. The customers and the regulators only care about the hard fields.
Quick Summary. “Why does templated OCR keep failing on claim files?” Because templates assume document stability and claim files are structurally unstable. The defensible solution is per-document-family extraction with ML plus rules plus a human-in-the-loop, not a better template.
The straight-through processing benchmark and why most carriers miss it
Straight-through processing (STP) is the percentage of claims that flow from intake to closure without human intervention. Deloitte’s claims research places top-quartile property STP rates in the 60 to 70% band. The industry median is well below that. Most carriers report STP optimistically because the denominator excludes the claim types they could not automate at all.
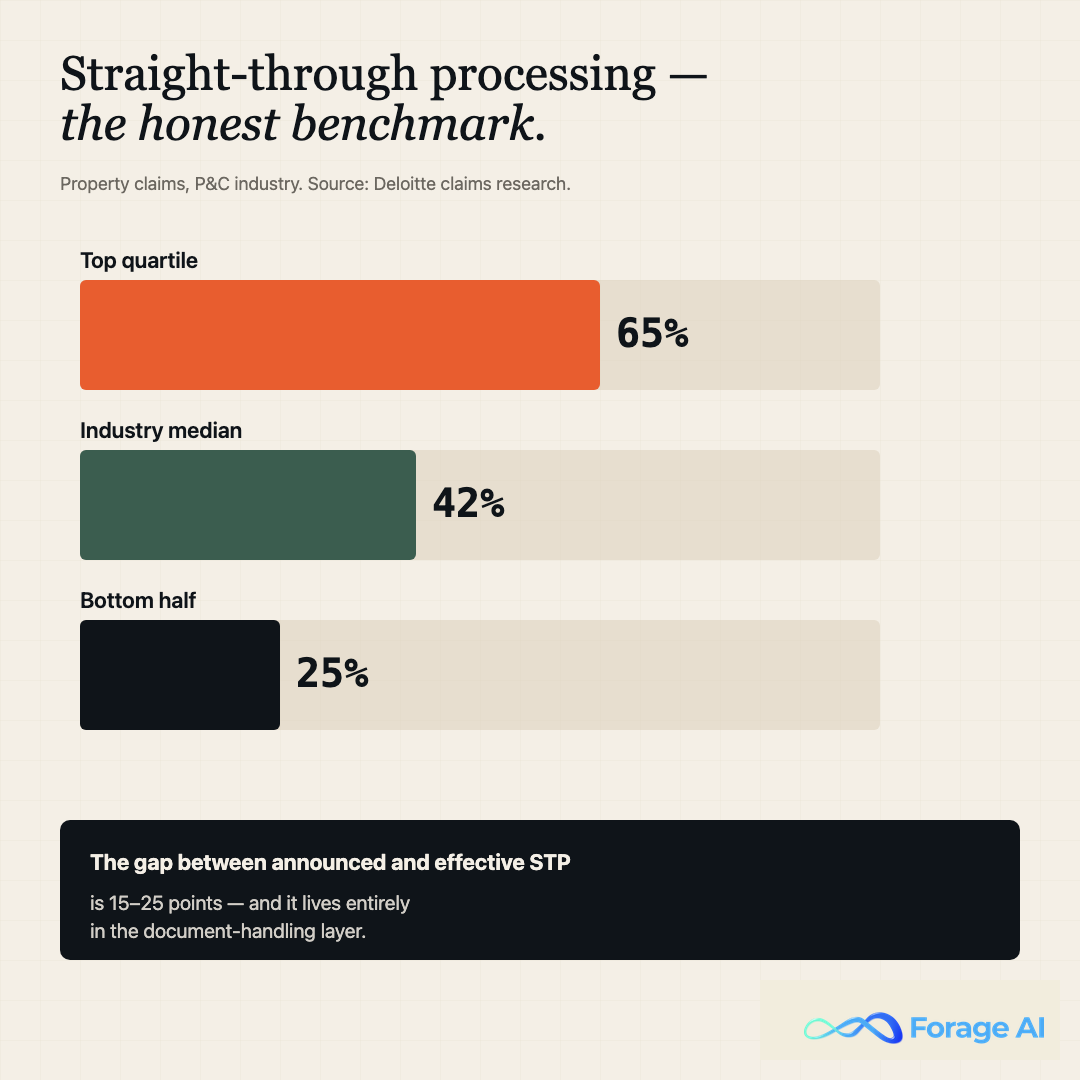
Stat callout. Top-quartile P&C carriers process 60 to 70% of property claims straight through. The bottom half process under 30%. The gap is almost entirely a document-handling and exception-routing problem.
The honest STP number is the one that includes the messy stuff: FNOLs with handwriting, demand packages with mixed invoice formats, and claims where the insured submits photos instead of receipts. When the denominator is honest, the gap between announced STP and effective STP is usually 15 to 25 percentage points. Closing that gap is where the meaningful ROI lives, and closing it requires an extraction that handles variability, not an extraction that handles the clean cases and dumps the rest into an exception queue that just relocates the manual work.
Expert Insight. When a carrier brags about an 85% STP number, ask for the denominator. In most decks that 85% applies only to a defined subset (first-party auto glass, simple property under a threshold) and the remaining queue absorbs all the loss-adjustment-expense pressure. A 65% honest STP is a healthier number than an 85% selective one.
Quick Summary. “What is a realistic STP target?” 60 to 70% across honest denominator categories. Anything higher is usually a denominator trick. Anything below 40% means the program never got past the easy cases.
The IDP plus expert QA pattern that makes claims automation defensible
The pattern that actually holds up at scale on insurance documents is layered. Enhanced OCR runs first, with HDR image processing, handwriting recognition, and table detection. Machine learning extraction reads the fields with a trained model that knows the document family. Rule-based validation checks the values against policy data, coverage logic, and known field constraints. Exceptions are routed to human reviewers who validate, correct, and feed the corrections back into the model. Write-back posts the validated record to the claims system.

This is the model Forage AI has built across more than 10 million parsed documents in financial, legal, and healthcare workflows. The reason the layered model works is not that any single layer is uniquely strong. It is that the layers cover each other’s failure modes. ML catches what templates miss. Rules catch what ML hallucinates. Humans catch what rules cannot specify. And the human corrections compound into the model over time. The discipline travels well across adjacent document classes; the legal-contracts parallel is instructive, legal teams face the same mix of clause-level variability, audit pressure, and human review gates that claim files demand, and the same layered pattern is how their extraction stays defensible.
The Forage approach commits to a 200% QA model, in which every extraction undergoes automated checks and human verification. The QA team is roughly three times the industry average size relative to the delivery team. That ratio sounds excessive until you sit through a market conduct exam and try to defend a 92% field-level accuracy claim with no human verification log. Verifiable accuracy is not a marketing line. It is what survives the audit.
Expert Insight. The QA layer is also where institutional memory accumulates. After a year of running a carrier’s claim flow, the human-in-the-loop reviewers have seen the same edge cases hundreds of times, and that pattern set is what trains the next quarter’s model improvements. Pipelines without a human layer never accumulate this asset.
Quick Summary. “Why does a layered approach beat a single AI model on claim files?” Because each layer protects against a different failure mode. ML covers variability, rules cover known constraints, humans cover the long tail, and the loop compounds. A single model has to be perfect on day one and degrades from there.
The audit trail you need before regulators ask
NAIC market conduct examination cycles run on an 18 to 24-month cadence. State regulators sample claim files, request documentation of how data flows through the carrier’s systems, and look for patterns of unfair claim settlement practices under each state’s Unfair Claims Settlement Practices Act. If a field in your claims system says “loss date = 2024-03-12” and a regulator asks where that came from, the answer cannot be “the IDP extracted it.”
The answer has to include: which document, which page, which bounding box on that page, which extraction model version, which validation rules fired, which human reviewer touched it (if any), what they changed, and when. Field-level lineage. Not document-level lineage.

Most generic IDP SaaS products produce document-level audit logs. They tell you that document X was processed at time Y with confidence Z. They do not tell you the chain of custody at the field level, and they certainly do not retain a tamper-evident history of human corrections. A claims automation stack that cannot answer the regulator at the field level is not really automated. It is just deferring the audit work to the moment of greatest pressure.
The test is simple. Pick a random closed claim from six months ago. Try to reconstruct, in 30 minutes, the full lineage of the three most decision-relevant fields in that file. If you cannot, you do not have an audit trail. You have a logfile.
Expert Insight. The regulators we see asking the sharpest field-level questions in 2025 and 2026 are NY DFS, CA DOI, and TX DOI. The carriers that get caught flat-footed are the ones whose IDP vendor’s “audit log” is a CSV of timestamps and document IDs with no field-level granularity. By the time you discover the gap, the exam is already underway.
Quick Summary. “What audit trail does claims automation need?” Field-level lineage that ties every value back to its document, page, bounding box, model version, validation outcome, and human review history. Document-level logs do not survive a market conduct exam.
Where automation belongs in the claims lifecycle, and where it doesn’t
A clean way to think about scope: automation belongs wherever the work is mechanical extraction, classification, routing, or validation against a known rule. It does not belong in coverage interpretation, reserve setting, settlement negotiation, or any decision that requires reading the spirit of a policy.
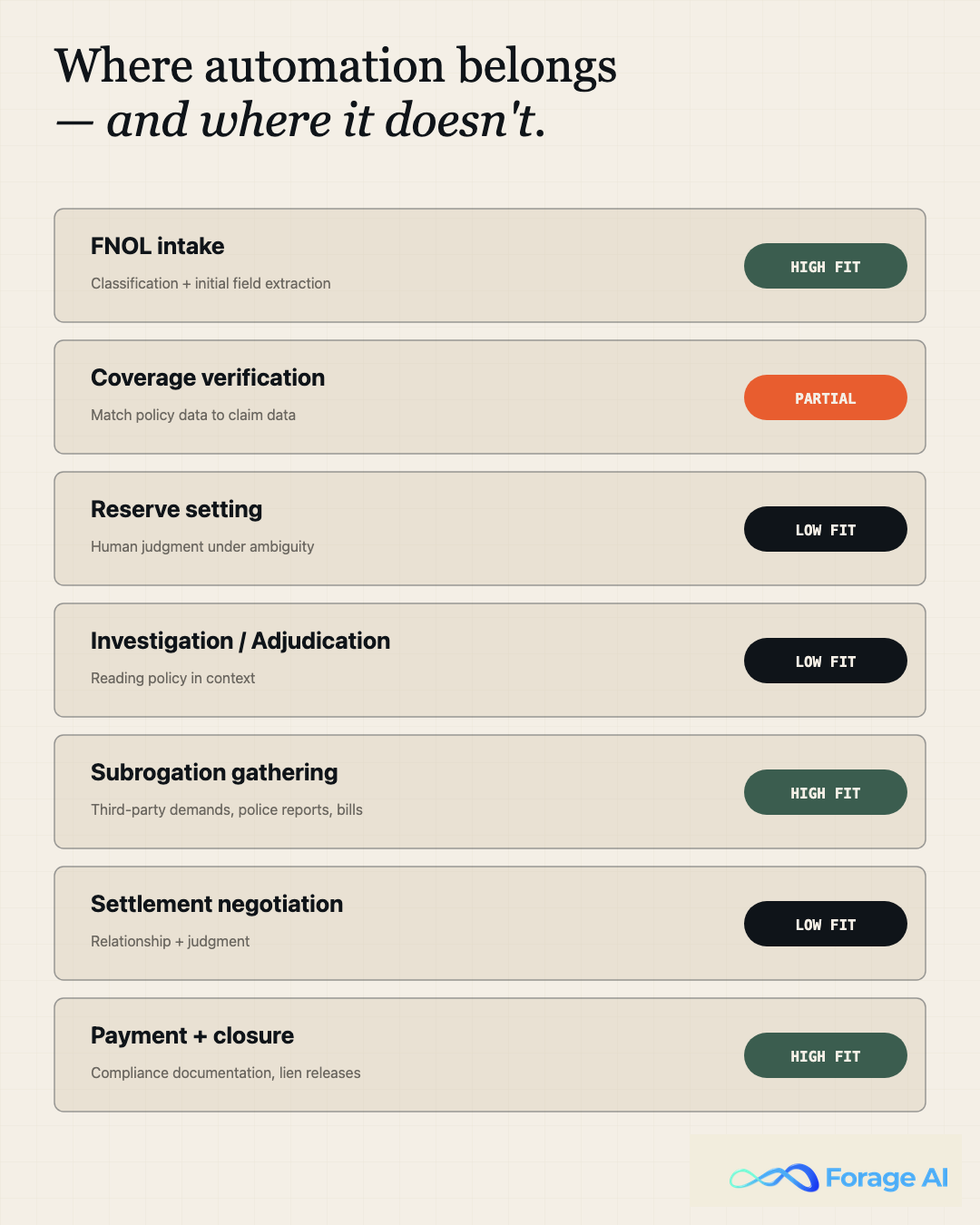
Inside that frame, the high-fit moments across the lifecycle are FNOL intake (classification plus initial field extraction), coverage verification (matching policy data to claim data), subrogation document gathering (third-party demands, police reports, medical bills), and payment plus closure (compliance documentation, lien releases, final paperwork). For a deeper treatment of the orchestration around extraction, see our piece on document workflow automation.
The low-fit moments are coverage interpretation under ambiguous policy language, reserve setting on complex liability claims, bad-faith risk assessment, and any decision involving negotiation. Assistive AI can support these by surfacing relevant precedents, summarizing claim history, and flagging anomalies, while the human stays in the loop and the automation stays in support.
Carriers that try to automate adjudication end up either overpaying (the model takes the path of least resistance) or underpaying (the model penalizes anything novel), and both outcomes show up in market conduct findings.
Expert Insight. The lifecycle map also helps with change management. Adjusters resist “the AI is replacing me” framing and accept “the AI is opening the envelopes and keying the forms” framing. The map gives a leadership team something concrete to point at when they explain scope to the claims floor.
Quick Summary. “Which claims tasks should we automate?” Intake classification, field extraction, validation against known rules, routing, subrogation gathering, and closure paperwork. Not adjudication, not reserve setting, not negotiation.
The Scale Wall, when manual plus light tooling stops working
The signals that a claims operation has hit the Scale Wall are consistent across carriers. Catastrophe season produces a sustained backlog the team cannot drain. Growth above 15 to 20% per year outpaces the hiring market for qualified adjusters. Regulatory tightening (a new state UCSPA interpretation, an NAIC bulletin, a privacy framework update) increases the documentation burden per claim. M&A integration drops a different carrier’s claim files into your workflow and the form library doubles overnight.
When two or more of those signals land in the same quarter, the cost of waiting compounds quickly. Loss adjustment expense (LAE) creeps up. Cycle time slips. Customer complaints rise. The CFO starts asking questions. The compliance officer starts asking different questions. The Scale Wall does not announce itself; it shows up as a steady degradation that a quarterly business review eventually has to confront.
Expert Insight. The signal we trust most is LAE creep on a flat exposure base. If exposure is flat or shrinking and LAE per claim is up two quarters in a row, the front of the funnel is the problem, not the adjudication layer. It is a remarkably reliable leading indicator.
Quick Summary. “How do I know we have hit the Scale Wall?” Watch LAE creep, cycle-time slippage, and complaint volume across two consecutive quarters. When two of those three move the wrong way on flat exposure, the operating model is the bottleneck.
Sovereignty, why most insurance claims SaaS quietly fails the legal test
This is the part most claims automation pitches skip. Almost every IDP SaaS product on the market today routes documents through third-party large language models, OpenAI, Anthropic, Google, or one of the major hyperscaler-hosted variants, to handle the parsing of unstructured content. For most use cases, that is fine. For insurance claims, it is a sovereignty problem.
Medical records inside a bodily injury claim are PHI. State data residency rules vary. Carrier contractual obligations to reinsurers, agents, and corporate insureds usually include data-handling clauses that do not contemplate sending documents to a third-party model provider whose terms reserve the right to use theinputs for service improvement. Legal and Compliance teams are increasingly the swing vote on claims automation deals for exactly this reason, and they are right to be.
The way Forage AI is built avoids this category of risk. Extraction is processed inside Forage’s own systems. Client data is never sent to third-party AI services, never aggregated across clients, never resold, and never used to train external models. On-premises deployment is available for environments where data must remain within the carrier’s perimeter. The signal phrase is simple: your data stays in our perimeter. It holds up under contract review because the contract backs the marketing.

For the claims director, this means the conversation with Legal and Compliance changes from “can we use this at all” to “how do we onboard this faster.” The deal does not get killed at the last review gate.
Expert Insight. The fastest way to lose a deal in 2026 is to hand a Legal team a sub-processor list with five upstream LLM providers on it. The fastest way to win the same deal is a one-line answer: no third-party LLM in the data path. Procurement gates have moved upstream, and a contract that says “we do not use OpenAI” closes more business in regulated lines than any feature bullet.
Quick Summary. “Why is data sovereignty the swing factor?” Because the legal review is where most deals fail, and most IDP SaaS routes PHI through third-party LLMs that the carrier’s contracts do not allow. A sovereign-by-design architecture turns a hard gate into a soft one.
Building the internal case, ROI math your CFO will accept
CFOs do not buy automation on the promise of speed. They buy it on a defensible model of loss adjustment expense reduction, leakage recovery, and cycle-time-driven customer retention.
A workable structure: take the average fully-loaded cost per claim file in the current state, break it into the document handling component (typically 15 to 30% depending on line of business), and model the reduction under realistic STP assumptions. Add the leakage recovery from catching coverage and reserving errors earlier in the cycle. Add customer lifetime value by protecting it with faster cycle times. Subtract the software, integration, and change management costs. Discount the first-year ROI by 40-50% to account for the realistic ramp.
Industry benchmarks help anchor the math. A one-point change in industry loss adjustment expense translates to billions of dollars across the property and casualty industry, per NAIC annual aggregate reporting. For a single mid-size carrier, a similar relative move shows up as a recognizable line item in the combined ratio. Cost is the closing argument in the CFO conversation, not the opener. The opener is reliability, defensibility, and the cost of doing nothing through the next CAT cycle.
Expert Insight. The number that lands hardest in a CFO conversation is “days of float on outstanding reserves”. If document handling delays open another two days of reserved-but-unpaid claims across the book, that is real working-capital cost that audit-committee CFOs understand viscerally. Frame the ROI in terms of float as much as in terms of LAE.
Quick Summary. “How do I model the ROI for the CFO?” LAE reduction on the document handling component (15 to 30% of fully-loaded cost), plus leakage recovery, plus retention, minus software and integration cost, discounted 40 to 50% for ramp. Anchor the closing argument on float and the combined ratio, not on speed.
What to evaluate when comparing claims automation partners
When the field of candidates is narrowed and the evaluation moves into procurement, these criteria separate partners that hold up from partners that demo well. Teams that are still building a shortlist often start from a roundup of the best insurance data extraction software and then apply the criteria below to whittle it down to the partners that survive a market conduct exam.

| Criterion | What to ask | Red flag |
|---|---|---|
| Accuracy reporting | Field-level, not document-level. By document family. | Vendor only reports document-level confidence |
| Audit trail | Field-level lineage, tamper-evident. Reconstruct any closed claim. | Logs only, no chain of custody |
| Data sovereignty | Sub-processor list. Third-party LLM disclosure. On-prem option. | Automated plus human, with a named QA ratio. |
| Form coverage | By line of business and by ACORD variant. | Demos a clean form, no coverage data |
| QA model | Automated plus human, with named QA ratio. | “AI-powered QA” with no human layer |
| Integration | Native connectors to your claims platform. | Vague answers on where the extraction actually happens |
| Partnership model | Dedicated team, change-request SLA, named technical owner. | Tier-1 ticket queue, anonymous support |
The criteria are uneven on purpose. Accuracy and audit trail outweigh integration in importance. A partner that integrates fast but fails the audit will cost more in market conduct findings than the integration ever saved.
Expert Insight. The single most diagnostic question in any vendor evaluation is “can you walk me through a closed claim from six months ago and show me where each field came from?” Vendors that pass that test almost always pass the rest of the evaluation. Vendors that pivot to talking about confidence scores are quietly admitting their audit trail is document-level.
Quick Summary. “What should I score partners on?” Accuracy reporting at field level, audit trail granularity, data sovereignty, form coverage, QA model, integration, partnership shape. Accuracy and audit trail weigh heaviest because they decide whether the deal survives a regulator.
How Forage AI approaches claims document extraction
Forage AI is not a claims platform. We do not adjudicate claims, set reserves, or replace your claims management system. We act as the acquisition layer for the document data that flows into those systems, handling the extraction, structuring, and quality assurance work that must happen between the document’s arrival and the claim being workable.
Our approach combines multi-method extraction (XPath plus NLP plus custom-trained ML models running in parallel, so accuracy holds when one method degrades), a 200% QA model with a QA team roughly three times the industry average size, and a delivery model where data stays inside our perimeter and yours. We have parsed more than 10 million documents across financial, legal, and healthcare workflows. Insurance claims sit at the intersection of all three, which is why the same patterns that hold for KYC, contract data extraction, and clinical document workflows also hold for claim files.
Sovereign by design means client data never trains third-party models, never gets resold, never aggregates across clients. SOC 2, GDPR, and HIPAA-compliant workflows are not a configuration option; they are how the service is built. On-premises deployment is available when the document corpus must remain within the carrier’s environment.
Onboarding typically takes one to two weeks from brief to a live extraction layer on a single document family, then expands as the form library widens. The team is dedicated, not a ticket queue. The acquisition layer is yours.

Expert Insight. The most common reason carriers move from in-house IDP to a Forage engagement is not accuracy. It is form expansion velocity. The carrier’s queue keeps absorbing new ACORD variants, regional medical forms, and post-M&A document families, and the in-house team cannot keep up. The dedicated-team model exists for exactly that pattern.
Quick Summary. “What does Forage AI do for claims?” Run the extraction, structuring, and QA layer that turns claim documents into validated structured records inside your claims system. We do not adjudicate. We do not touch the decision. We make the document data trustworthy and auditable.
Frequently Asked Questions
How accurate is claims processing automation today?
Honest accuracy claims are field-level, by document family. A reasonable expectation is 95 to 97% field-level accuracy on clean document families and 88 to 94% on messy families (handwritten, low-resolution, mixed-format), with the gap closed to 99%+ through human-in-the-loop validation of exceptions that fall below a confidence threshold. Document-level confidence numbers in vendor decks usually overstate what survives an audit.
What is the difference between OCR, IDP, and claims processing automation?
OCR converts pixels to text. IDP adds classification, structured extraction, and validation on top of OCR. Claims processing automation adds workflow orchestration, business rules, exception routing, and write-back to claims systems on top of IDP. Our OCR vs IDP comparison covers the first two layers in depth.
Can we automate claims adjudication?
No, and you should not try. Adjudication requires reading policy language in context, applying judgment to ambiguity, and managing relationships with insureds and counsel. Automation belongs in the document handling, extraction, and orchestration layers around adjudication, not in the decision itself. Carriers that have tried to automate adjudication have either overpaid or underpaid, exposing themselves to market conduct findings.
How long does it take to deploy claims processing automation?
For the extraction layer on a single document family, one to two weeks from brief to live with a competent partner. For a full multi-family rollout integrated with the claims platform, three to six months is realistic. Most of the timeline is focused on integration, change management, and form-coverage expansion, not on extraction technology.
Related Articles
- Top 10 Document Processing Solutions for Financial Services 2026, vendor comparison for regulated document workflows.
- AI-Powered Intelligent Document Processing Solutions 2025, broader overview of how AI-powered IDP works.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




