

Global spending on financial market data hit a record $44.3 billion in 2024, up 6.4% year over year (Burton-Taylor, 2025). That is the line buyers can see. The line they cannot see is what gets bought wrong. The pattern across the dataset is consistent: a feed that looked finished at signing breaks in production.
A bought financial data feed fails in the parts that no demo exposes. Coverage and price are visible; redistribution rights and point-in-time accuracy are not. Those last two determine whether the feed passes an audit, supports a model-training use case, or holds up in a backtest. Most rankings of financial data providers compare the visible parts and skip the two that break.
The trap runs on two axes. The first is licensing: internal use, redistribution, resale, AI training, and retention are separate rights, and most enterprise licenses restrict the ones buyers most want.
The second is point-in-time accuracy: a feed can be complete today and still wrong for a backtest, because survivorship and look-ahead bias overstate every result built on overwritten history. A 2026 study found an overstatement of 4.94 percentage points in annual returns. Neither axis shows up in a feature comparison.
The buyer base now extends past the market-data desk. Per Mordor Intelligence (January 2026), 67% of professionals already deploy alternative data, and 94% plan to increase their outlays.
The data says more teams are signing feeds without a licensing or point-in-time review in the loop, and the cost of getting it wrong scales with the spend.
This guide ranks 20 providers by data type, Forage AI at #1 as the managed-extraction option for when a packaged feed clears none of the gates. Each entry carries its own comparison table on the axes that actually break a feed, plus an honest read on what users praise and complain about.
The evaluation framework comes after the list, so you can shortlist first and run a repeatable check before you sign.

Financial data providers at a glance: who each is best for
- Forage AI (#1): best when a packaged feed’s licensing or freshness blocks the use case and you need the data on your own schema, with ownership you control.
- Bloomberg: best for front-office breadth across markets, news, and analytics.
- LSEG (Refinitiv): best for markets data plus infrastructure at scale.
- FactSet: best for equity research, portfolio analytics, and ownership data.
- S&P Global Market Intelligence (Capital IQ): best for fundamentals, estimates, and as-of accuracy via Compustat Point-In-Time.
- Financial Modeling Prep: best for broad coverage on a budget with dev-friendly REST endpoints.
- Finnhub: best for real-time data and fundamentals via API, with a generous free tier.
- Intrinio: best for institutional-grade US fundamentals, ESG, and holdings via API.
- Alpha Vantage: best for a budget API with a strong free tier.
- Twelve Data: best for developer-friendly real-time and historical multi-asset data.
- Polygon.io: best for US-equities real-time streaming and minute-bar history.
- Nasdaq Data Link: best for a marketplace of niche financial, economic, and alternative datasets.
- ICE Data Services: best for fixed-income pricing and evaluated data at scale.
- Exchange Data International (EDI): best for reference data and corporate actions.
- Cbonds: best for fixed-income specialist coverage.
- Dun & Bradstreet: best for company financials, credit risk, and firmographics.
- Morningstar PitchBook: best for private-capital and venture market intelligence.
- AlphaSense: best for AI-search across filings, transcripts, and broker research.
- Kaiko: best for institutional crypto market data.
- Bright Data: best for a web-data marketplace with financial and crypto datasets.
What we are listing, and how we judged it
Every provider below is scored against four factors in the order that determines whether a feed survives a use case. Rights and as-of accuracy come first because they are the two axes a generic ranking never tests. Coverage and reference-data consistency layer on top.
| Factor | What it asks | Why it decides the buy |
|---|---|---|
| Licensing & redistribution | Can you embed, resell, AI-train, and retain the data? | Internal use, redistribution, model training, and retention are separate rights; most enterprise licenses restrict the ones buyers most want |
| Point-in-time accuracy | Does it return data as it appeared then, with restatement lineage and delisted names? | Survivorship and look-ahead bias overstate every backtest built on overwritten history |
| Coverage depth | Does it cover the long tail and delisted names you actually need? | A bigger provider is deep on large-cap and thin in the tail; “best” is use-case-specific |
| Reference-data consistency | Do identifiers map cleanly across your existing feeds? | Identifier mismatch across CUSIP, ISIN, and SEDOL is the most common silent break |

The first factor splits into four rights the buyer clears one at a time: embed in a product, resell a derived dataset, train a model, and retain the data after the contract ends.
Internal use is the base grant. Everything past it costs more and is audited more closely, and most enterprise licenses restrict it.

Categorize a provider by what it actually sells before comparing it to anything else, because the data type predicts the licensing posture and the failure mode.
Financial data is split into eight broad types, and the type is the first thing to match against your use case.
| Data type | What it is | The rights or risk that bites |
|---|---|---|
| Reference/entity | Real-time and historical quotes, OHLCV, order books, corporate actions | Exchange redistribution licensing; vendor-agnostic exchange fees |
| Company fundamentals | Statements, ratios, estimates; as-reported vs standardized | Restatement and point-in-time accuracy; look-ahead bias |
| Credit/firmographic | Identifiers, security master, classifications, mappings | Identifier fragmentation across CUSIP/ISIN/SEDOL; reconciliation breaks |
| Filings & regulatory | SEC/EDGAR filings, ownership, insider transactions | Source licensing, latency and correction handling |
| Alternative | Web/scraped, satellite, foot traffic, card, social, job postings | MNPI and diligence risk; redistribution and source rights |
| ESG | Environmental, social, governance scores and disclosures | Methodology disagreement; restatement of scores |
| Ratings, credit risk, default, and company financial health | Coverage completeness, parsing and timeliness | Private-company coverage gaps; redistribution limits |
| News & sentiment | News feeds, NLP-derived sentiment signals | Coverage completeness, parsing, and timeliness |

- Match the type to the use case first. Backtesting lives on fundamentals plus point-in-time integrity. In-product display lives on exchange redistribution licensing. Alternative data carries MNPI and diligence risk that the others do not.
- Reference data sits underneath all of it. When the join keys do not line up, the other seven types stop reconciling, which is why identifier mapping is the quiet break.
- The buyer base now spans past the market-data desk. Per Mordor Intelligence (January 2026), 67% of professionals already deploy alternative data, and 94% plan higher outlays.
Quick Summary
Q: How do you judge a financial data provider before you buy?
A: Score every provider on four factors in order: licensing and redistribution rights, point-in-time accuracy, coverage depth, and reference-data consistency. Rights and as-of accuracy come first because they are the two axes that a generic ranking never tests, and they determine whether a feed passes an audit or a backtest. Categorize the provider by what it actually sells first, because the data type, one of eight, predicts both the licensing posture and the failure mode.
Expert Insight
The U.S. Treasury’s Office of Financial Research has formally documented that fragmented instrument identifiers, CUSIP and ISIN and SEDOL plus internal IDs, impede data consolidation across the financial system. Reference-data consistency is a recognized systemic-data-quality problem, not a vendor talking point, and it is the join-key layer that determines whether the other seven data types reconcile (OFR Viewpoint Paper 17-03).
The 20 financial data providers, ranked by data type
The right provider is use-case-specific, so this list is grouped by what each one is genuinely best for, with Forage AI at #1 as the option for when a bought feed clears none of the gates. Every entry uses the same comparison columns because the cleanest way to compare 20 providers is a single, consistent read on the axes that break a feed.
Pricing is described as a model where no public figure is verified. Review sentiment is attributed to the platform it came from, never to the vendor.
1. Forage AI
| Field | Detail |
|---|---|
| Best for | Acquiring public financial data to your own schema when a packaged feed’s licensing or freshness blocks the use case |
| Key use cases | In-product embedding, AI-training datasets, filings and fundamentals extraction, alternative-data feeds, retention you control |
| Pricing model | Managed-service, quote-based per scope and cadence |
| Licensing & redistribution | You own the extracted output; no-resell of client data; on-premise and sovereign delivery available; never sent to third-party LLMs |
| Data types & coverage | Filings, fundamentals, news/sentiment, firmographic, and alternative/web data; 500M+ websites and 10M+ documents across sectors |
| Standout strength | Build-to-spec extraction to your schema, your refresh cadence, with provenance tags and a 3x-industry QA layer |
| Watch-out | Not a packaged terminal, not a 30-year fundamentals warehouse, not a real-time market-data feed |
Forage AI is for the buyer who hits the licensing or freshness wall on a packaged feed. It is not a terminal or a market-data vendor on this list. It is the managed extraction layer for when a bought feed breaks on the two axes. This guide leads with.
When a license will not let you embed a feed in-product, resell a derived dataset, train a model on it, or retain it after the contract ends, Forage extracts the underlying public data to your schema and your cadence, with ownership you actually control. The output is yours, provenance-tagged, and never sent to third-party LLMs.
The sovereign and no-resell posture is co-primary, not a footnote, because the buyers who hit the licensing wall hardest sit in regulated verticals where redistribution and retention rights are the whole decision. On-premise delivery keeps the data inside your infrastructure. Client data is never resold or reused.
For point-in-time and coverage gaps, the model is the same: rather than inheriting an exchange or vendor’s correction behavior and long-tail thinness, you specify the capture, and the service handles selector drift, anti-bot evolution, and schema changes as part of the work.
It delivers the data, not just the pipeline, and works as an extension of your data team, typically live in 1 to 2 weeks, with SOC 2 controls. The watch-out: this is not a replacement for a terminal you already run well.
Forage is the option for when a feed’s coverage or license blocks the use case. The build-vs-buy mechanics sit in our piece on how financial data extraction works.

Institutional platforms and terminals
The institutional terminals win on bundled breadth, and the recurring trade-off across all four is the same: enterprise cost and redistribution restrictions that determine whether the feed survives embedding or AI training.
None is the wrong choice for front-office breadth. All four require the rights review before the buy.
2. Bloomberg
| Field | Detail |
|---|---|
| Best for | Front-office breadth across markets, news, and analytics |
| Key use cases | Trading, research, real-time market monitoring, enterprise data feeds |
| Pricing model | Per-seat Terminal subscription; enterprise Data License |
| Licensing & redistribution | Enterprise redistribution licensing required; restrictive on external use |
| Data types & coverage | Market, fundamentals, news, reference; deep cross-asset breadth |
| Standout strength | Breadth and bundled depth as the front-office benchmark |
| Watch-out | Cost and the enterprise redistribution licensing layered on top |
Bloomberg is for front-office teams that need everything in one place. It is the front-office benchmark, and its breadth across markets, news, and analytics is unmatched by any other single source.
The gripe that recurs in practitioner forums is consistent: cost and the enterprise redistribution licensing that sits atop the seat fee.
For a buyer trying to surface Bloomberg data within a product they ship or to train a model on it, the licensing review is the sole decision, not the data quality. The watch-out is the rights ceiling, not the data: the breadth is real, and so is the redistribution restriction that comes with it.
3. LSEG (Refinitiv)
| Field | Detail |
|---|---|
| Best for | Markets data plus infrastructure at scale |
| Key use cases | Enterprise market data, feeds, workflow via Workspace |
| Pricing model | Subscription; enterprise feeds, quote-based |
| Licensing & redistribution | Internal-product-embedding terms reported as restrictive |
| Data types & coverage | Market, fundamentals, reference; broad cross-asset scale |
| Standout strength | Scale and infrastructure across markets data |
| Watch-out | Redistribution and embedding licensing can be restrictive |
LSEG (Refinitiv) is for teams that need both market data scale and infrastructure. It brings one of the largest market data footprints in the category.
Platform-comparison analyses note that its internal-product-embedding terms can be restrictive, which matters most for teams trying to surface the data inside a product they ship rather than use it internally.
As with every terminal here, the scale is a genuine strength, and the embedding posture is the gate. If the use case is internal analytics, the licensing rarely bites. The watch-out: if it is in-product or model-training, read the redistribution clause before you shortlist.
4. FactSet
| Field | Detail |
|---|---|
| Best for | Equity research, portfolio analytics, and ownership data |
| Key use cases | Buy-side and sell-side research, portfolio analytics, ownership analysis |
| Pricing model | Subscription; enterprise |
| Licensing & redistribution | Redistribution restricted per third-party data terms |
| Data types & coverage | Fundamentals, ownership, estimates |
| Standout strength | Research and ownership depth |
| Watch-out | Redistribution difficult under third-party terms |
FactSet is for buy-side and sell-side analysts who live in research and ownership data. It is strong on research and a default for analysts who live in portfolio analytics.
The same platform-comparison analyses note redistribution is difficult under its third-party data terms, which the vendor documents on its own third-party-terms page.
The depth of ownership and estimates is the reason teams pick it. The watch-out is the same redistribution ceiling that applies to the rest of the institutional tier, so the rights review should come before the buy for any external-use case.
5. S&P Global Market Intelligence (Capital IQ)
| Field | Detail |
|---|---|
| Best for | Enterprise cost: licensing for derived use |
| Key use cases | Fundamentals, estimates, credit, private company |
| Pricing model | Subscription; enterprise |
| Licensing & redistribution | Standard enterprise restrictions; point-in-time product available |
| Data types & coverage | Fundamentals analysis, point-in-time backtesting, private company, and credit research |
| Standout strength | Compustat Point-In-Time as the as-of reference standard |
| Watch-out | Enterprise cost; licensing for derived use |
S&P Global Market Intelligence (Capital IQ) is for quant teams that need survivorship-clean, restatement-aware history. It carries fundamentals, estimates, credit, and private-company data, and its Compustat Point-In-Time product is the category reference standard for as-of fundamentals.
It provides a consistent view of historical financial data, both reported and subsequently restated, the way it appeared at the end of any month. This is the benchmark against which the rest of the list is measured.
The trade-off is the institutional one: enterprise cost and licensing for derived use. The point-in-time depth is the reason it earns the slot. The watch-out is cost: confirm the specific product tier covers the use case before signing.
Quick Summary
Q: Which financial data provider is best for fundamentals and backtesting?
A: For as-of fundamentals, S&P Global’s Compustat Point-In-Time is the reference standard because it preserves both reported and restated figures the way they appeared at the time. The institutional terminals win on bundled breadth, but all of them carry enterprise cost and redistribution restrictions that decide whether the feed survives an embedding or AI-training use case.
🧭 Expert Insight
The breadth of a terminal does not settle the corrections question. As CP Capital founder Chris Petrescu observed, “Some datasets will remove companies that have gone bankrupt, or overwrite companies that have been acquired. It sounds simple, but some of the largest data vendors in the world don’t grasp these concepts, or don’t care to” (Calcbench, 2022). For the institutional tier, a per-provider read on how each one stores and versions history matters more than the bundled feature list.
Fundamentals and API-first developer tiers
The developer tier wins on budget and flexibility, and the public-review pattern is consistent across G2, Capterra, and Reddit threads: praise for the free and budget tiers, complaints about rate limits and long-tail coverage once a use case scales.
For any of these, the licensing column is tier-dependent, so the redistribution and AI-training rights have to be read against the specific tier, not the brand.
6. Financial Modeling Prep
| Field | Detail |
|---|---|
| Best for | Broad coverage on a budget, dev-friendly |
| Key use cases | Prices plus fundamentals via practical REST endpoints |
| Pricing model | Tiered subscription; budget and dev tiers |
| Licensing & redistribution | Tier-dependent; check redistribution terms per plan |
| Data types & coverage | Prices plus fundamentals |
| Standout strength | Practical REST endpoints, broad coverage at a low price |
| Watch-out | Coverage depth varies in the long tail |
Financial Modeling Prep is for teams that want fundamentals and prices without a terminal contract. It draws repeated praise across G2 and developer threads for practical REST endpoints and broad coverage at a low price. It is a common first stop for budget fundamentals.
The recurring caveat in the same reviews is that long-tail depth varies, so a coverage probe against your actual universe matters more here than the headline endpoint list. The watch-out: for deep long-tail or delisted coverage, test before you commit.
7. Finnhub
| Field | Detail |
|---|---|
| Best for | Real-time plus fundamentals via API |
| Key use cases | Real-time quotes, fundamentals, and alternative-data signals |
| Pricing model | Freemium; generous free tier |
| Licensing & redistribution | Tier-dependent |
| Data types & coverage | Real-time, fundamental, alternative |
| Standout strength | Generous free tier and alt-data breadth |
| Watch-out | Rate limits on the free tier at scale |
Finnhub is for developers prototyping across real-time, fundamental, and alternative data. Its generous free tier is the headline in community sentiment, and its breadth across data types makes it a flexible starting point. The most common complaint in those same threads is rate limits once a use case scales past the free tier.
For prototyping and lower-volume production, the free and budget tiers are the draw. The watch-out as volume grows: rate limits and the tier-dependent redistribution terms, the two things to confirm against the paid plan.
8. Intrinio
| Field | Detail |
|---|---|
| Best for | Institutional-grade US fundamentals, ESG, and holdings via API |
| Key use cases | US market data, fundamentals, ESG, institutional holdings |
| Pricing model | Tiered subscription |
| Licensing & redistribution | Tier-dependent |
| Data types & coverage | US market, fundamentals, ESG, holdings |
| Standout strength | Institutional-grade access via API |
| Watch-out | Pricing scales with scope |
Intrinio is for teams that want cleaner institutional data without a full terminal. It positions as institutional-grade access via API across US market data, fundamentals, ESG, and institutional holdings. It sits a step above the pure budget tier.
The recurring sentiment is that pricing scales with scope, so the cost advantage over a terminal narrows in broad multi-feed use cases. The watch-out: for a focused US fundamentals or holdings feed, it is a strong fit, but the cost climbs with scope.
9. Alpha Vantage
| Field | Detail |
|---|---|
| Best for | Budget API with a strong free tier |
| Key use cases | Equities and FX for development and lower-volume production |
| Pricing model | Freemium; strong free tier |
| Licensing & redistribution | Licensed-exchange-sourced; tier-dependent |
| Data types & coverage | Equities, FX, sourced from NASDAQ and OPRA |
| Standout strength | Strong free tier as a budget entry point |
| Watch-out | Rate limits and coverage gaps |
Alpha Vantage is for a lightweight or early-stage equities and FX feed. It sources from licensed exchanges, including NASDAQ and OPRA, and is a common budget entry point. The strong free tier is the recurring draw in developer reviews.
The recurring sentiment is that rate limits and coverage gaps occur once a use case scales, the same pattern that runs across the budget API group. The watch-out: for production breadth, test the coverage and the limits first.
10. Twelve Data
| Field | Detail |
|---|---|
| Best for | Developer-friendly real-time and historical multi-asset data |
| Key use cases | Real-time and historical stocks, forex, and crypto via API |
| Pricing model | Tiered subscription |
| Licensing & redistribution | Tier-dependent |
| Data types & coverage | Stocks, forex, crypto |
| Standout strength | Developer-friendly real-time access across asset classes |
| Watch-out | Coverage gaps in the long tail |
Twelve Data is for a multi-asset real-time feed at developer scale. It is favored in developer reviews for real-time and historical access to stocks, forex, and crypto in a single API. The multi-asset breadth and developer-friendly interface are why teams reach for it.
The same long-tail caveat applies as it does to the rest of the group, and the redistribution terms are tier-dependent. The watch-out: probe the tail for niche instruments before you commit.
11. Polygon.io
| Field | Detail |
|---|---|
| Best for | US-equities real-time streaming and minute-bar history |
| Key use cases | Real-time US stock streaming, historical minute bars, trading apps |
| Pricing model | Tiered subscription; limited free tier |
| Licensing & redistribution | Tier-dependent |
| Data types & coverage | US stocks, forex, crypto; real-time and historical |
| Standout strength | WebSocket streaming and minute-data depth in US markets |
| Watch-out | Reported gaps in dividend and split data; thin free tier |
Polygon.io is for real-time US equities and minute-bar history at throughput. It is built around US-equities performance, and its WebSocket streaming and minute-bar history are what developers single out in reviews.
If the use case is streaming every trade for a US ticker or pulling years of minute data, it handles the throughput that lighter APIs do not.
The watch-outs that recur in developer write-ups and GitHub issue threads are corporate actions gaps, with reports of missing dividend and split data on even well-known tickers, and a free tier that is thin for anything past development.
The watch-out: if your model depends on a clean corporate actions history, validate that layer specifically.
12. Nasdaq Data Link
| Field | Detail |
|---|---|
| Best for | A marketplace of niche financial, economic, and alternative datasets |
| Key use cases | Pulling specific economic, financial, and alternative datasets via API |
| Pricing model | Marketplace; free datasets plus per-dataset premium subscriptions |
| Licensing & redistribution | Per-dataset terms; varies by publisher |
| Data types & coverage | Financial, economic, and alternative datasets from many publishers |
| Standout strength | Breadth of niche datasets with R, Python, and Excel integration |
| Watch-out | Per-dataset licensing makes total spend hard to forecast |
Nasdaq Data Link is for a team that needs one or two niche economic or alternative feeds. Formerly Quandl, it runs a marketplace model: free datasets sit alongside premium ones from many publishers, accessed through well-documented APIs with R, Python, and Excel integration. The catalog breadth is the draw.
The watch-out, noted across developer comparisons, is the marketplace structure itself: per-dataset licensing and pricing make total spend harder to forecast when a workflow pulls across several premium sources, and redistribution terms vary by publisher.
The watch-out: read each dataset’s terms separately rather than assuming one platform-wide license.
Quick Summary
Q: What are the best financial data APIs for developers?
A: Financial Modeling Prep, Finnhub, Alpha Vantage, and Twelve Data win on budget and broad coverage; Polygon.io leads on US-equities real-time streaming; Nasdaq Data Link offers a marketplace of niche datasets. Across all of them, the recurring complaints are rate limits and long-tail coverage gaps, and redistribution rights are tier-dependent, so confirm the rights against the specific plan.
🧭 Expert Insight
The budget-tier complaints about coverage gaps point at the same root cause that breaks larger feeds. As CP Capital founder Chris Petrescu observed, “Some datasets will remove companies that have gone bankrupt, or overwrite companies that have been acquired. It sounds simple, but some of the largest data vendors in the world don’t grasp these concepts, or don’t care to” (Calcbench, 2022). For an API tier, the rate-limit ceiling is visible at signup; the corrections and delisting behavior is not, and it is the one to test directly.
Reference, fixed-income, and specialists
The specialists win on depth in one data type, which is the right call when the failure mode you face is reference-data consistency or fixed-income coverage rather than breadth.
None of the three is a full-market terminal, and that is the point: when the gap is deep in one type, a specialist clears it where a generalist will not.
13. ICE Data Services
| Field | Detail |
|---|---|
| Best for | Fixed-income pricing and evaluated data |
| Key use cases | Evaluated pricing and reference data at scale |
| Pricing model | Enterprise, quote-based |
| Licensing & redistribution | Enterprise terms; redistribution licensed |
| Data types & coverage | Fixed-income, evaluated pricing, reference |
| Standout strength | Evaluated pricing depth at scale |
| Watch-out | Enterprise cost and scope |
ICE Data Services is for a fixed-income desk that needs to evaluate pricing at scale. It is the reference for fixed-income pricing and evaluated data, the layer where instruments do not trade often enough for a last-price feed to be enough. For evaluated pricing across a large fixed-income book, the depth is the reason it earns the slot.
The trade-off is enterprise cost and scope, and redistribution is licensed under enterprise terms. The watch-out: for a generalist use case it is more than the gap requires.
14. Exchange Data International (EDI)
| Field | Detail |
|---|---|
| Best for | Reference data and corporate actions |
| Key use cases | Security master, corporate actions, historical pricing |
| Pricing model | Subscription, quote-based |
| Licensing & redistribution | Subscription terms; check redistribution |
| Data types & coverage | Reference, corporate actions, pricing |
| Standout strength | Corporate-actions and reference accuracy |
| Watch-out | Narrower than full-market terminals |
EDI is for a team whose break is in the reference layer, not market breadth. Exchange Data International is built around reference data, corporate actions, and historical pricing, the layer that determines whether your security master reconciles. When the failure mode is an identifier mapping or a missed corporate action, the specialist addresses it directly.
It is narrower than a full-market terminal, and that is by design. The watch-out: it is not a market-breadth feed, so the focused accuracy is worth more than a generalist’s wider but shallower coverage only when reference data fills the gap.
15. Cbonds
| Field | Detail |
|---|---|
| Best for | Fixed-income specialist coverage |
| Key use cases | Bond pricing and reference depth |
| Pricing model | Subscription |
| Licensing & redistribution | Subscription terms |
| Data types & coverage | Fixed-income, bond reference |
| Standout strength | Bond-market specialist depth |
| Watch-out | Specialist scope, not full-market |
Cbonds is for a credit or fixed-income team that needs broad bond coverage. It is a fixed-income specialist with bond-market depth and reference coverage the generalist terminals do not match in that one type. It reaches instruments that a market-data generalist treats as an afterthought.
Its scope is deliberately fixed-income rather than full-market, so it sits alongside a broader feed rather than replacing one. The watch-out: it is a specialist, not a full-market feed, but when the gap is bond depth, it clears it.
Quick Summary
Q: When should you pick a reference-data or fixed-income specialist over a terminal?
A: Pick a specialist when the failure mode is depth in one data type rather than breadth. ICE Data Services leads in evaluated fixed-income pricing at scale, EDI in reference data and corporate actions that determine whether a security master reconciles, and Cbonds in bond-market specialist coverage. None replaces a full-market terminal; each sits alongside one to close the specific gap a generalist leaves open.
Credit, firmographic, and private markets
This category fills the private-company and credit gap that the public market leaves open. Public-market terminals are deep on listed securities and thin on private entities.
So credit, firmographic, and private-capital providers exist as their own category for due diligence, risk, and private markets work.
16. Dun & Bradstreet
| Field | Detail |
|---|---|
| Best for | Company financials, credit risk, and firmographics |
| Key use cases | Third-party-risk screening, private-company intelligence, due diligence |
| Pricing model | Enterprise subscription, quote-based |
| Licensing & redistribution | Company financials, credit risk, firmographic, and global business universe |
| Data types & coverage | Private company and firmographic depth public-market feeds lack |
| Standout strength | Private-company and firmographic depth public-market feeds lack |
| Watch-out | Coverage and freshness vary by region and entity tier |
Dun & Bradstreet is for due diligence and third-party risk work, not market trading. It fills the private company and firmographic gaps that the public market leaves open. It is the reference for company financials, credit risk, and firmographic screening.
The recurring sentiment caveat across review platforms is that coverage depth and freshness vary by region and by how far down the entity tier you go, the same long-tail point that applies to every coverage claim in this guide. The watch-out: coverage and freshness thin out by region and entity tier, so probe the universe you actually screen.
17. Morningstar PitchBook
| Field | Detail |
|---|---|
| Best for | Private-capital and venture market intelligence |
| Key use cases | Deal-flow intelligence, PE and VC research, private-company profiles |
| Pricing model | Subscription; enterprise, quote-based |
| Licensing & redistribution | Enterprise terms; redistribution licensed |
| Data types & coverage | Private-capital, venture, M&A, private-company financials |
| Standout strength | Depth and breadth of private-capital coverage |
| Watch-out | Private-market data freshness depends on disclosure and self-reporting |
Morningstar PitchBook is for a team whose use case is private-market deal intelligence. PitchBook, part of Morningstar, is a default for private capital and venture intelligence, and reviewers on G2 consistently point to its depth and breadth of data across deal flow, PE, and VC coverage. It covers entities the public-market feeds do not track.
The inherent watch-out for private-market data, true of the category and not unique to PitchBook, is that freshness depends on disclosure and self-reporting, so private-company figures tend to lag and be more estimated than listed fundamentals. The watch-out: treat the private-company financials as directional rather than as filed.
Quick Summary
Q: Where do you get financial data on private companies?
A: Use the credit, firmographic, and private-capital category, because public-market terminals are deep on listed securities and thin on private entities. Dun & Bradstreet leads on company financials, credit risk, and firmographic screening for due diligence; Morningstar PitchBook leads on private-capital and venture deal intelligence. Treat private-company figures as directional, since freshness depends on disclosure and self-reporting rather than filing dates.
News, sentiment, alternative, and web data
This category serves the data types that the traditional feeds do not. Research-search, news and sentiment, crypto, and web-sourced data each raise their own questions of rights and freshness.
For the marketplace and web models, the source rights and point-in-time checks matter even more than with a single-source feed.
18. AlphaSense
| Field | Detail |
|---|---|
| Best for | AI-search across filings, transcripts, and broker research |
| Key use cases | Market intelligence, thesis validation, document and earnings-call search |
| Pricing model | Subscription; enterprise, quote-based |
| Licensing & redistribution | Enterprise terms; content-source-dependent |
| Data types & coverage | Filings, transcripts, broker research, news, expert interviews |
| Standout strength | AI search across a large content set, strong support |
| Watch-out | Steep onboarding; price hard to justify for lighter use |
AlphaSense is for a research team that lives in filings and transcripts. It is a research and market intelligence platform that runs AI search across company filings, broker research, earnings transcripts, news, and expert interviews.
It holds a strong rating on G2 based on hundreds of reviews, where users single out the AI summaries and responsive support as reasons it speeds up thesis validation.
The recurring complaints in those reviews are a steep onboarding curve, with new users describing the feature set as overwhelming, and a price some find hard to justify against lighter AI research tools. The watch-out: for occasional use, the cost and learning curve outweigh the search depth.
19. Kaiko
| Field | Detail |
|---|---|
| Best for | Institutional crypto market data |
| Key use cases | Enterprise terms: check redistribution |
| Pricing model | Subscription, quote-based |
| Licensing & redistribution | Enterprise terms; check redistribution |
| Data types & coverage | Crypto market data, order books, DeFi |
| Standout strength | Institutional-grade crypto depth |
| Watch-out | Scope limited to crypto |
Kaiko is for desks that need reliable, institutional crypto data. It delivers crypto market data, with order books, trades, and DeFi metrics at a depth retail crypto APIs do not reach. It is the specialist that the generalist cannot match in that type.
Its scope is deliberately limited to crypto rather than full-market coverage, so it sits alongside a traditional feed rather than replacing one. The watch-out: scope is crypto-only, but when the data type is crypto, and the bar is institutional, it clears it.
20. Bright Data
| Field | Detail |
|---|---|
| Best for | A web-data and scraping marketplace with financial datasets |
| Key use cases | Web-sourced financial and crypto datasets |
| Pricing model | Subscription and usage-based |
| Licensing & redistribution | Marketplace terms; source-rights dependent |
| Data types & coverage | Web-scraped financial and crypto data |
| Standout strength | Breadth of web-sourced datasets |
| Watch-out | Source rights and freshness vary by dataset |
Bright Data is for a team that needs web-derived signals rather than exchange or fundamentals feeds. It is a web data and scraping marketplace that includes financial and crypto datasets, and its breadth of web-sourced data is the draw. The catalog reaches sources that the traditional providers do not.
The watch-out that applies to any marketplace model is that source rights and freshness vary from dataset to dataset, so rights clearance and point-in-time checks matter even more here than with a single-source feed. The watch-out: clear source rights and freshness per dataset, not platform-wide.
The alternative-data category as a whole, including the MNPI and diligence questions that come with non-traditional signals, is covered in our guide to evaluating alternative data providers. For the wider packaged-data market these financial feeds sit inside, see our roundup of the Data-as-a-Service (DaaS) companies.
Quick Summary
Q: Which financial data providers are best, and how do you tell them apart?
A: The right provider is use-case-specific. Terminals win on bundled breadth, API and developer tiers on budget and flexibility, specialists on depth in one type, credit and private-markets providers on the entities’ public feeds miss, and managed extraction when no packaged feed clears the gates. Compare them on licensing, freshness, coverage, and reference-data consistency, not on brand size.
🧭 Expert Insight
The vendor-failure pattern holds across the institutional and fundamentals groups. As CP Capital founder Chris Petrescu observed, “Some datasets will remove companies that have gone bankrupt, or overwrite companies that have been acquired. It sounds simple, but some of the largest data vendors in the world don’t grasp these concepts, or don’t care to” (Calcbench, 2022). A per-provider read on licensing and freshness surfaces what a feature list hides.
How to choose: the four-gate evaluation framework
The list has answered which providers fit which use case. Here is the repeatable method for deciding between them. Run four gates in order.
The sequence matters because clearing a later gate is wasted work if an earlier one already disqualifies the feed. Clear rights first, then run the point-in-time test, then the coverage probe, then the reference-data consistency check.
This four-gate evaluation replaces the generic six-factor checklist (accuracy, coverage, latency, price, integration, support) that every ranking ships and that ignores the two axes where feeds actually break.
| Gate | What to ask | What good looks like | Red flag |
|---|---|---|---|
| 1. Rights-clearance | Written a grant for each right the use case needs | Breadth claims that it thins out in the tail | Silence or case-by-case approval on the right you need |
| 2. Point-in-time test | Does it return data as it appeared then, with restatement lineage and delisted names? | As-of snapshots, versioned history, delisted coverage | Overwritten history; survivors only |
| 3. Coverage probe | Does it cover the long tail and delisted names we need? | Depth in your actual universe, not the demo set | Clean CUSIP/ISIN/SEDOL mapping, a few exceptions |
| 4. Reference-data check | Do identifiers map cleanly across our feeds? | Clean CUSIP/ISIN/SEDOL mapping, few exceptions | Reconciliation exceptions on shared entities |

Gate 1: Can you actually use the data you licensed?
Often not by default. A license is not ownership: internal use, redistribution, resale, AI training, and retention are separate rights, and licensing a feed for internal analytics does not grant the right to embed it in a product you sell, resell it, train a model on it, or keep it after the contract ends.
Most enterprise licenses restrict the buyers who want the most.
Two operational realities make this expensive to get wrong. First, exchange license fees are vendor-agnostic. They are owed regardless of which provider you choose, ranging from $32 to more than $20,000 per month per exchange, and a redistribution license is triggered if you distribute data externally within 24 hours of receipt.
Second, the audit looks backward, so a license that changes retroactively bills for data already consumed, and a derived-data license costs materially more than a raw-data one. As of January 2026, CME’s delayed-data fee was $304 per month, and a bank licensed across CME’s five exchange products would pay $273,600 per year in market-data fees (WatersTechnology, 2026).
📊 $273,600 per year
Market-data fees a bank pays across CME’s five exchange products, with the delayed-data fee at $304 per month. Source: WatersTechnology, 2026 (as of January 2026).
The implication for sequencing is direct. If your use case is AI training or in-product embedding, most enterprise licenses restrict it, so clear the right before you shortlist, not after, and start the licensing process three to six months before you need the feed live.
If the feed is sovereign or regulated, the redistribution and retention posture is decisive, not cost. For the licensing nuances specific to non-traditional sources, see our alternative data sources and licensing guide.
This article is for informational purposes only and does not constitute legal advice. Consult qualified counsel for your organization’s specific licensing and redistribution terms.
Expert Insight
The CME licensing overhaul shows how live this risk is. CME ended free end-of-day licenses for CME, CBOT, Nymex, and Comex, reclassified end-of-day as chargeable delayed data, and back-billed fees despite limited access controls. On whether the IPUG user group would pursue litigation, IPUG chair and bank market-data procurement head Caroline Poisson said, “It’s something we’re looking at” (WatersTechnology, 2026). When a license changes retroactively, the exposure is measured in years of back-billing, which is why the rights review belongs before the buy.
Gate 2: Is it accurate as of, not just complete today?
A feed can be complete today and still wrong for a backtest. The reason is point-in-time integrity: whether the data returns as it appeared at the time, with the restatement lineage intact, rather than as it looks now after corrections.
As-reported figures are the original numbers a market saw on the filing date. Restated and standardized figures overwrite them later. Point-in-time data preserves the as-reported view a model would actually have had.
Two biases follow from getting this wrong. Survivorship bias comes from dropped and delisted names that quietly vanish from the dataset, leaving only the winners. Look-ahead bias arises when a backtest sees numbers that were not known on the date it claims to trade. Both inflate results in the same direction: returns up, drawdowns down.
The magnitude is measurable, not theoretical. A 2026 study of India’s NIFTY Smallcap 250 found survivor-only backtests reported 26.17% annual returns against 21.23% for the true delisting-inclusive universe, a 4.94-percentage-point overstatement, with the Sharpe ratio inflated to 1.160 from 1.063.
Across the broader literature, survivorship bias has been shown to inflate Sharpe ratios by roughly 0.5 (Brown, Goetzmann, Ibbotson, and Ross) and to cause hedge-fund drawdowns to be underestimated by an average of 14 percentage points (Andrikogiannopoulou and Papakonstantinou). The number you bought is not the number you can trade.

📊 4.94-percentage-point overstatement
Survivor-only backtests of India’s NIFTY Smallcap 250 reported 26.17% annual returns against 21.23% for the true delisting-inclusive universe, with the Sharpe ratio inflated to 1.160 from 1.063. Source: arXiv 2603.19380, a 2026 study.
Restatements move rankings, not just point estimates. After restatement, one company fell from a top-5% return-on-equity ranking to the 88th percentile, and another shifted from the 92nd to the 27th percentile (Eagle Alpha, 2024). The data changed under the model, which is exactly the failure point-in-time integrity is meant to catch.
Run a point-in-time test before you buy: confirm the feed returns data as it appeared then, carries restatement lineage, and includes delisted names, and ask the vendor directly how they store and version historical data. The mechanics of point-in-time capture are covered in our piece on how financial data extraction works.
This article is for informational purposes only and is not financial advice. Consult a qualified financial advisor before making investment or trading decisions.

🧭 Expert Insight
The corrections layer is where vendors quietly differ. As CP Capital founder Chris Petrescu observed, “Some datasets will remove companies that have gone bankrupt, or overwrite companies that have been acquired. It sounds simple, but some of the largest data vendors in the world don’t grasp these concepts, or don’t care to” (Calcbench, 2022). Headline coverage does not reveal this. Only a point-in-time test does.
Gates 3 and 4: coverage depth and reference-data consistency
After rights and freshness, coverage and reference data consistency determine the rest. Coverage is not one number. It splits into breadth, the count of securities or entities, and depth, how far into the long tail and the delisted names the feed actually goes.
A feed can claim broad coverage and still be thin where it matters: small caps, private companies, emerging markets, and names that have since dropped off. A bigger provider does not mean better data, and breadth claims mean little without long-tail and delisted depth.
Reference data is the quieter failure. Identifiers, CUSIP, ISIN, and SEDOL, plus internal IDs, are the join keys that let feeds reconcile. When two feeds disagree on the same entity, the cause is usually an identifier mapping issue, not the underlying numbers.
That mismatch is the most common silent break, and it carries a measurable operational cost: 32% of UK payments businesses rank exception handling among their most time-consuming reconciliation tasks, with mismatched identifiers and missing fields cited as the single biggest underlying cause of breaks (Kani Payments, 2025).
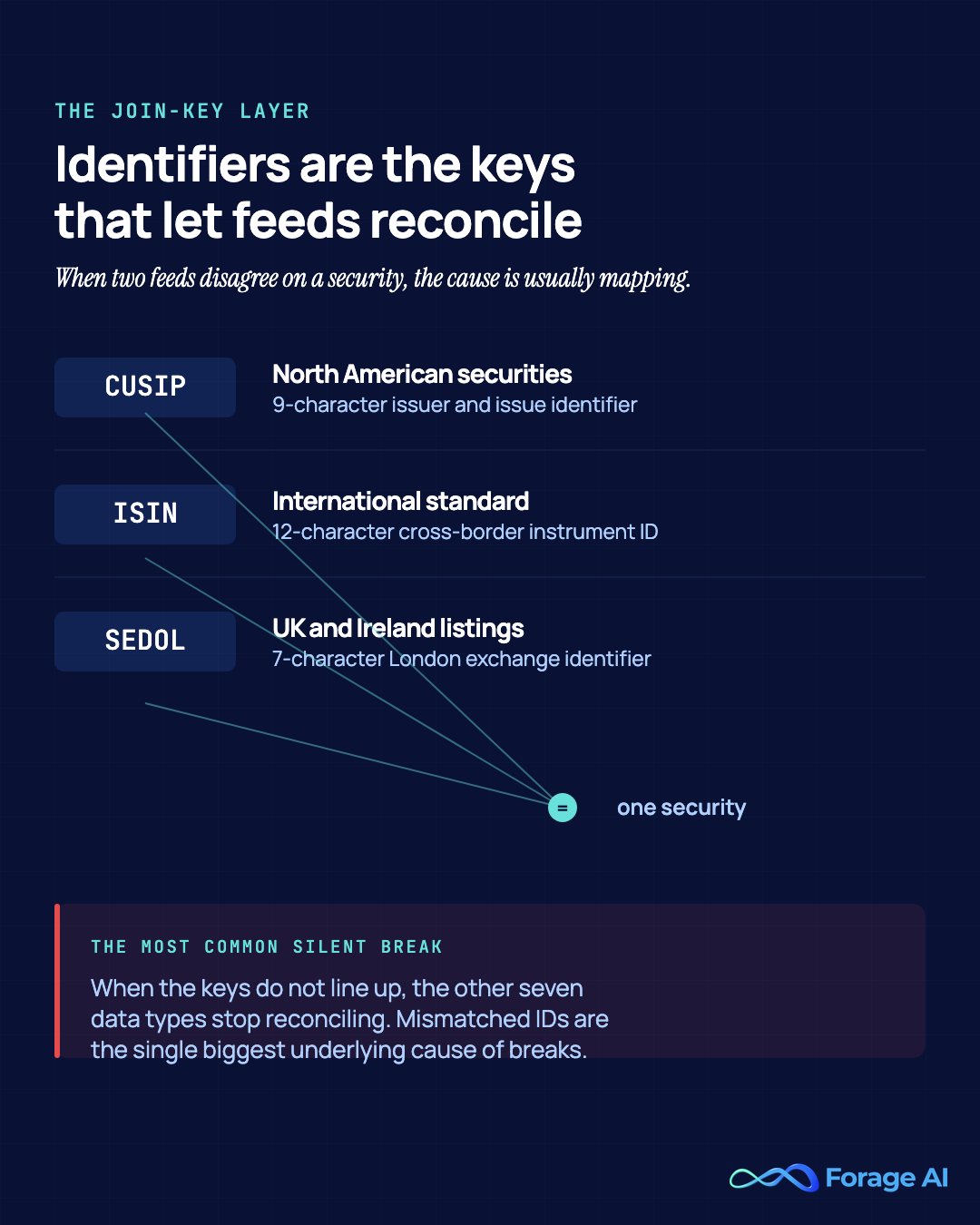
Two probes settle it. Run a coverage probe against the long tail and the delisted names you actually need, not the headline universe a demo shows. Run a reference-data consistency check to confirm that identifiers map cleanly across your existing feeds before you add another one.
The demand signal is strong: the alternative-data market alone was roughly $11.7 billion in 2024 to 2025 and is projected to reach $143.87 billion by 2031 at a 51.91% CAGR (Mordor Intelligence, January 2026), so coverage demand is expanding precisely where bad coverage costs the most.
Breaking ties, and when no feed clears all four
Apply a tie-breaker when two providers clear the gates closely. If both pass all four and the decision sits within a narrow margin, break the tie on the gate whose failure would cost the most in year two.
For most regulated and product-embedding use cases, that is, rights-clearance, because a rights gap surfaces as back-billing or a forced product change long after the contract is signed. For quant backtesting, the tie-breaker is point-in-time integrity, because a survivorship or look-ahead gap silently overstates every result built on it.
When no packaged feed clears all four for your use case, commission-managed extraction to your own schema. This is the rational move when you need in-product embedding, AI training rights, retention, and long-tail coverage at once, and no single feed provides them all.
Forage AI fits here: it extracts public data into your schema and cadence, with ownership and retention you control, which is decisive in sovereign and regulated contexts where the rights posture, not the price, is the sole decision. The broader build-vs-buy architecture sits in our solution-level evaluation framework.

Quick Summary
Q: How should you evaluate and choose a financial data provider?
A: Run four gates in order: rights-clearance, a point-in-time test, a coverage probe, and a reference-data consistency check. Break ties on the gate whose failure costs the most in year two, usually rights for regulated or product use cases, and point-in-time for backtesting. Commission managed extraction when no packaged feed clears all four.
Expert Insight
The gate order is not arbitrary; it tracks where the largest exposure sits. On the CME licensing overhaul, IPUG chair and bank market-data procurement head Caroline Poisson said, on whether the user group would pursue litigation over retroactive back-billing, “It’s something we’re looking at” (WatersTechnology, 2026). A rights gap surfaces years after signing, as back-billing or a forced product change, which is why rights-clearance runs first in the four-gate sequence.
Financial data vendors, providers, or solutions: are they the same thing?
One terminology question lies beneath the entire evaluation, and it maps directly to the scope of the decision in front of you. “Vendor” and “provider” mean the same thing here: who you buy from. “Company” is used interchangeably with both.
“Solutions” is the broader category, the build-or-assemble layer that sits above any single provider, which is why a solutions decision is an architecture decision and a provider decision is a selection decision. This guide is about who you buy from.
Pick the word for the decision in front of you. Provider or vendor selection is what this article supports. The solution-level architecture is covered in our solution-level evaluation framework, the target for the broader financial data solutions decision. The sourcing method, when extraction is the answer, is covered in how financial data extraction works.
Quick Summary
Q: Are financial data vendors, providers, and solutions the same thing?
A: Vendor and provider mean the same thing, and company is used interchangeably with both: all three name who you buy from, which is a selection decision. Solutions is the broader build-or-assemble layer that sits above any single provider, so a solutions decision is an architecture decision. This guide supports provider and vendor selection; the solution-level architecture is a separate, higher-order call.
Conclusion
A provider’s headline coverage is the part a demo shows. Its redistribution rights and its accuracy as of now are the factors that determine whether the feed survives your use case and your next audit. That is the bought-data trap: the buy looks finished at signing and breaks where you were not looking, in the contract and in the historical archive.
The four-gate evaluation is the lens that keeps it from happening. Clear the rights, run the point-in-time test, probe the long-tail coverage, check the reference-data mapping, in that order, and the “best provider” question answers itself against your actual use case.
When no packaged feed clears all four, the move is managed extraction to a schema and a rights posture you control. For the broader architecture decision behind that call, the solution-level evaluation framework is the next step.
FAQ
What are the main types of financial data providers?
They map to eight data types: market/pricing, fundamentals, reference/entity, filings and regulatory, alternative, ESG, credit/firmographic, and news/sentiment. The type predicts the risk, so market-data providers carry exchange-licensing risk while fundamentals providers carry restatement and point-in-time risk.
Can I redistribute or train an AI model on licensed financial data?
Usually not by default. Internal use, redistribution, resale, AI training, and retention are separate rights, and most enterprise licenses restrict the ones buyers most want. Clear the specific rights your use case needs in writing before you shortlist.
What’s the difference between as-reported and point-in-time (restated) financial data?
As-reported is the original figure a market saw on the filing date. Point-in-time data preserves the data as it appeared then, with restatement lineage, so a model only sees what was knowable at the time. Without it, backtests inherit look-ahead and survivorship biases, which a 2026 NIFTY Smallcap study measured at a 4.94 percentage-point return overstatement.
How much do financial data providers cost?
Pricing ranges from free and budget API tiers to six-figure enterprise terminals, plus vendor-agnostic exchange fees of $32 to more than $20,000 per exchange per month (per industry licensing guidance). Specific vendor figures vary by tier and scope.
Which financial data provider is best for backtesting, fundamentals, market data, or alt data?
It is use-case-specific. Backtesting needs point-in-time and survivorship-clean fundamentals; in-product market display needs redistribution rights; alternative data needs MNPI diligence. Match the provider to the data type and the rights your use case requires, not to brand size.
How do I find financial data on private companies?
Use firmographics and credit providers such as Dun & Bradstreet, private capital intelligence such as Morningstar PitchBook, or platforms with private company coverage such as Capital IQ. Private-company coverage is a distinct gap that public-market feeds do not fill, so treat it as its own category in the evaluation.
Related Articles
- Strategic Framework for Evaluating Financial Data Solutions: An Executive Guide: the solution-level decision above provider selection, covering build, buy, or assemble across the eight data types.
- Top Alternative Data Vendors: How to evaluate alternative data providers, including the MNPI and diligence questions specific to non-traditional signals.
- Alternative Data Guide: alternative data sources and the licensing nuances that come with web, satellite, and transaction data.
- What is Financial Data Extraction: the mechanics of capturing financial data into your own schema when a packaged feed will not.




