

You inherited a pipeline. Some of the data comes from an internal extraction job your team owns, some from a managed vendor your predecessor signed for, and some from a licensed corpus that gets refreshed once a quarter. The model team is asking when retraining can start. Procurement wants to know what changes would occur if you switch to a different vendor. Legal wants per-record provenance for the EU AI Act review. None of the strategic articles you have skimmed helps, because they are not written for the person who has to actually operate this.
This playbook is for that person.
The argument is short. AI training data ops is dominated by four operational properties: freshness, latency, schema stability, vendor handoff cleanliness, and lock-in cost. Sourcing mode choice (in-house extraction, managed external, licensed corpus, synthetic) should be made along these axes, not based on feature comparisons or vendor reputation. Get the ops layer right, and the sourcing question answers itself.
Quick Digest
What you get: an ingestion-boundary view of AI training data, quantified freshness/SLO bands tied to retraining cadence, a vendor data-contract template with the seven fields any external source should commit to, a 4-mode sourcing matrix comparing in-house, managed external, licensed, and synthetic on operational axes, a drift-and-retraining cadence framework, and a 30-day diagnostic plan for PMs inheriting a stack mid-stream. What you do not get: a vendor ranking, “what is AI training data” definitions, or a strategic-buyer pitch.
The Ingestion-Boundary View: What AI Training Data Actually Costs You to Operate
The strategic literature treats training data as an asset. The operational literature, when it exists, treats it as an ingestion-boundary contract. The second view is more useful because it surfaces what your team will actually have to maintain.

A training-data pipeline runs in five stages: sources (internal databases, web extraction, vendor feeds, licensed datasets, synthetic generators) flow through ingestion (scheduled or streaming), through validation (schema checks, completeness, distribution), through versioning (semantic dataset versions, lineage), into consumption (training, fine-tuning, evaluation pipelines). Each stage has its own SLO, failure mode, and change-management cost.
The four operational properties that determine your total cost of ownership across this pipeline:
- Freshness latency. The lag between a source-side change and an updated training set. Tighter is more expensive; looser produces a silent quality decay.
- Schema stability. How often the producer-side schema changes, and whether your pipeline catches it at the boundary or leaks it into the training set.
- Vendor handoff cleanliness. Whether the upstream contract is enforceable in CI, or whether you discover violations downstream during a retrain.
- Lock-in cost. What it would actually cost in time and risk to swap one source for another. Most teams underestimate this by an order of magnitude.
Two reference points to anchor the priority. The data pipeline accounts for roughly 80 percent of AI success, with the model itself contributing the remaining 20 percent. Teams typically spend 60 to 80 percent of their time on data preparation rather than model development. Gartner’s 2026 Data and Analytics predictions put the share of AI spending going to data readiness on a seven-fold growth path from 2025 to 2029, and project that 40 percent of total IT data-management spend will go to multistructured data management by 2027. The work you are doing on this pipeline is where the budget is going.
For foundational definitions of AI training data, see our explainer on AI data. For the public vs. private classification you will hit during sourcing-mode decisions, see public web data vs private data in AI training.
Expert Insights. ML researchers debate model architecture. ML engineers operate the ingestion. The practitioner literature has been written for the first group; this article is written for the second. The four operational properties matter more than the sourcing mode. Get them wrong and no vendor change recovers the cost.
Quick Summary. Training-data ops is an ingestion-boundary contract, not an asset. Four operational properties (freshness latency, schema stability, handoff cleanliness, lock-in cost) drive every downstream decision. The data pipeline is 80 percent of AI success.
Data Freshness and Data SLOs: The Single Most Underweighted Decision
Most teams set freshness aspirationally. “We update daily” turns out to mean the daily job ran. Whether the data inside it reflects what changed at the source is a separate question, and it is the more interesting one.
A data SLO makes the freshness question contractual. The pattern that has matured in 2025 and 2026 is the same shape data engineering uses for warehouse pipelines: 99.9 percent of daily pipelines succeed and data freshness is under one hour of source-side lag, measured per source-tier rather than at the pipeline level. Observability tooling has extended upstream from the warehouse into the ingestion layer to make this measurable: arrival on schedule, schema drift detection, volume anomaly detection, and increasingly LLM-style data quality bots that flag pre-training distribution issues before faulty data reaches the model.
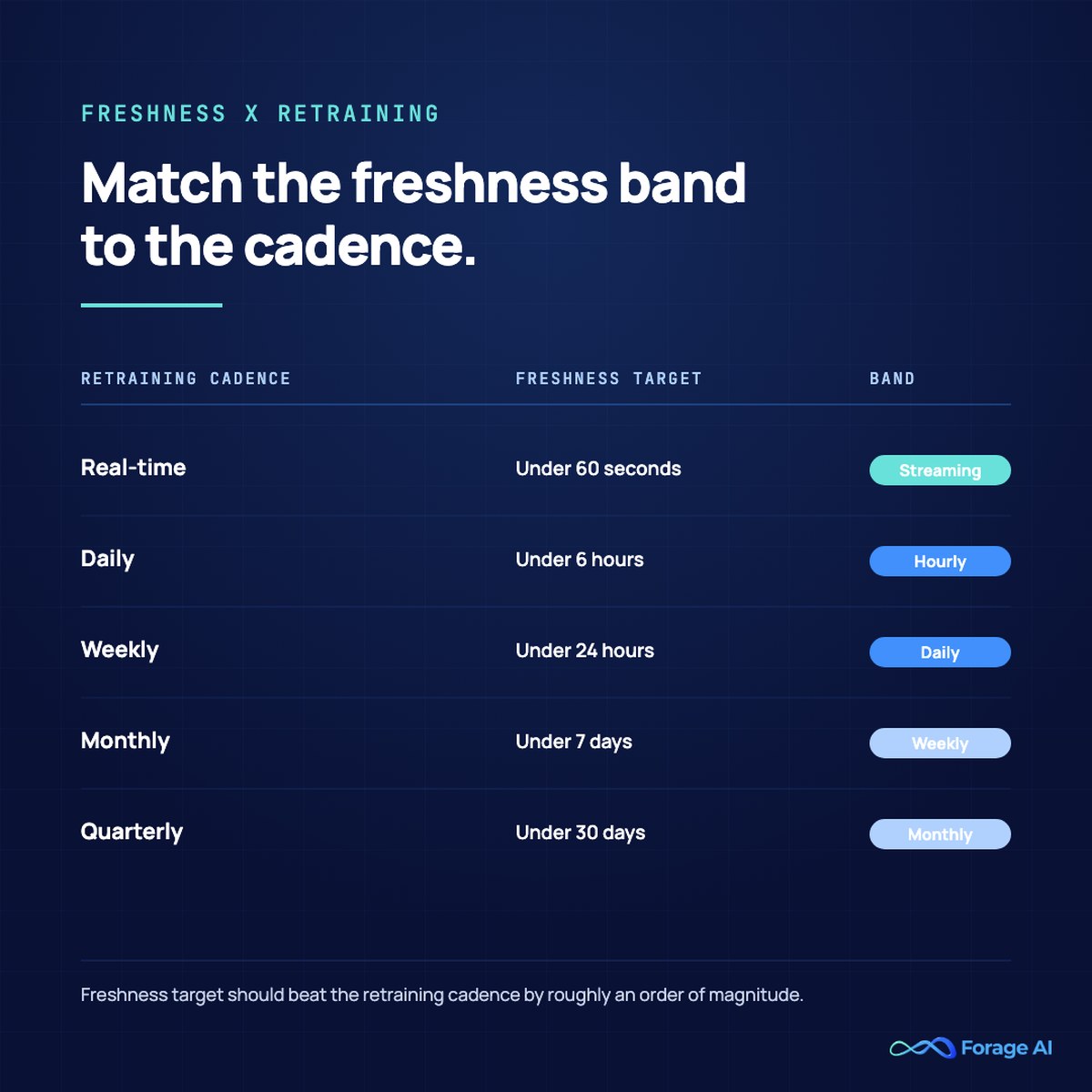
The freshness band you should target is determined by your retraining cadence, not your aspirations:
| Retraining cadence | Recommended freshness target | Notes |
|---|---|---|
| Data SLO of <1hr lag is reasonable on dynamic sources | sub-hour | observability + alerting must be sub-15-min |
| Daily fine-tune | 1 to 4 hours | The common case for B2B SaaS use cases |
| Weekly retrain | 24 to 48 hours | Freshness above this band is wasted spend |
| Monthly evaluation | weekly | freshness above this band is wasted spend |
| Real-time/continuous fine-tune | per refresh | flag staleness explicitly to consumers |
Buying tighter freshness than your model retains is wasted spend. Buying looser freshness than your retrain cadence is a silent quality decay. Both are common; the second one hurts more because nobody finds it until the eval set drifts.
A second point most articles miss. Freshness alone is insufficient. You also need distribution stability. A pipeline that arrives on time but has shifted its statistical properties is no better than a stale one, and is sometimes worse because the appearance of freshness reduces scrutiny. Pair freshness SLOs with distribution monitoring at the dataset level (KL-divergence, feature-level drift on embedding distributions, gold-label drift on evaluation sets).
For the strategic case behind freshness and quality investment, see why quality web data beats quantity for AI training.
Expert Insights. “We update daily without monitoring” is the same uptime theatre that hurt analytics teams in 2018. Data SLOs are the way out. Tie them per source-tier, measure freshness at the source-to-trainable-set boundary, and pair with distribution monitoring. A vendor that cannot give you a freshness SLO is selling a feed, not a service.
Quick Summary. Match freshness to retraining cadence using the band table above. Tighter than retrain wastes budget; looser silently decays quality. Pair freshness SLOs with distribution monitoring; freshness alone is uptime theatre.
Schema Versioning and Data Contracts: What Stops Training Sets from Quietly Breaking
Schema drift is the silent failure mode of training data ops. The producer changes a field type, splits a column, renames a key, or moves a value under a different parent. Your ingestion job runs to completion. The validation step, if you have one, may even pass on rules written before the change. The training set updates. The model retrains on slightly wrong data, evaluates against slightly wrong evals, and ships into production with a quality regression nobody can immediately localize.
Two practices stop this. The first is dataset versioning. Every published dataset gets a semantic version. Tools like DVC, LakeFS, and git-LFS make this enforceable; lineage in a feature store keeps consumer-side joins explicit. When something breaks, you can revert to a known-good version, retrain in parallel, and A/B compare. Without versioning, drift is detected late and recovery is a forensic exercise.
The second practice is the data contract. A data contract is a typed, validated, CI-enforced agreement between producer and consumer. The pattern moved from theory into everyday data-engineering practice during 2024 and 2025; for AI training data it is now table-stakes for any external source.

A vendor-grade data contract for AI training data has seven fields:
- Typed schema. Fields, types, and nullable flags. Versioned. Backward-compatible for at least one prior version.
- Validation rules. Range checks, enum sets, referential integrity. CI-tested in the producer’s pipeline before delivery.
- Freshness guarantee. SLO or SLA tied to a measurable freshness latency per source tier.
- Idempotency keys. A stable per-record identifier so replays produce the same dataset, not duplicates.
- Replay support. A documented mechanism for re-delivering N days of data without producing duplicates downstream.
- Retention policy. How long the source retains its historical state, and what your contractual access to it is.
- Exit and data-portability clause. What happens at termination? Who keeps what? How to export the schema and full historical state.
A vendor without these seven is selling a feed, not a service. Schema-drift recovery time becomes a primary SLO once you have data contracts; it is the time from a producer-side breaking change to a recovered downstream state. Mature teams track this as a primary engineering metric. Immature teams will not have a number when you ask.
For the downstream architecture question, see data storage solutions for LLMs and RAG.
Expert Insights. “We will add data contracts later” is the most expensive technical debt in this space. Adding contracts after a pipeline is in production costs 4 to 10 times as much as building them in. The cheapest contract is the one negotiated at vendor selection.
Quick Summary. Two practices stop schema drift from leaking into models: dataset versioning (DVC, LakeFS) and data contracts (seven fields, CI-tested at the producer). Without both, drift detection is forensic and recovery is days, not minutes.
Sourcing Modes: In-House Extraction, Managed External, Licensed Corpora, Synthetic
Most teams run a mix. The mix question is what to operate on which axis. The four sourcing modes have distinct operational profiles, and the right choice for any given source depends on the four operational properties from H2-1.

The 4-mode comparison on operational axes:
| Sourcing mode | Freshness latency | Schema stability | Handoff cleanliness | Lock-in cost |
|---|---|---|---|---|
| In-house extraction | Whatever you build | You control the producer (good) but absorb upstream changes (bad) | You control the producer (good), but absorb upstream changes (bad) | Low (it’s yours) |
| Managed external | SLA-bound, typically sub-hour to daily | Vendor absorbs producer-side drift; passes through validated schema | Data contract should be standard | Medium (mitigated by exit clause) |
| Licensed corpus | Per refresh (often static or quarterly) | High stability per release; low freshness | Bulk delivery, one-shot validation | High on data; low on access |
| Synthetic | Generated on demand | Schema is whatever you generate | Internal handoff only | You own end-to-end |
A few non-obvious operational facts about each mode:
- In-house extraction wins when sources are bounded, static, and you can absorb the maintenance. The maintenance band typically lands between 30 and 60 percent of relevant engineering hours at scale, depending on source count and anti-bot pressure. Above 50 dynamic sources, in-house starts costing more than managed.
- Managed external is the operational match for high-freshness, schema-volatile, regulated workloads. A vendor with a real data contract absorbs the failure modes that would otherwise eat your roadmap. Forage AI’s Data for AI service is the managed-external option in this category, with SLA-bound delivery, schema contracts, per-record provenance, and the data-contract pattern documented in H2-3.
- Licensed corpora are right for rights-cleared, evaluation-grade datasets where freshness is not the limiting factor and provenance must be defensible to legal. Always pair with a license log. “Licensed equals compliant” is false; you still need indemnification clauses and license tracking for audit.
- Synthetic data fixes coverage of tail and edge cases that your customers do not generate. It does not fix freshness. It does not replace evaluation against real-world distributions. Treat it as an augmentation, not a replacement.
The provenance, indemnification, and license-log triad is the procurement table-stakes for any non-internal source in 2026. The EU AI Act’s enforcement pressure on per-record provenance, and the US state-level data law shifts, make these non-negotiable for high-risk system applications. A vendor that cannot produce per-record provenance by 2026 is operating on borrowed time.
For the build-burden lens, see build vs buy for web data extraction. For the compliance lens specific to scraping-driven sources, see ” Solving the AI Training Data Crisis with Compliant Web Scraping.
Expert Insights. Mode mixing is the norm, not a sign of indecision. Most production stacks have two or three modes running at once with the routing decided per source. The mistake is not the mix; it is failing to instrument the boundary contracts so you can compare the modes on operational axes rather than vendor pitches.
Quick Summary. Four sourcing modes, four distinct operational profiles. Match each source to the mode that fits its freshness, schema, handoff, and lock-in characteristics. Provenance plus indemnification plus license log is the 2026 procurement table-stakes for any non-internal source.

Drift and Retraining Cadence: Connecting Pipeline Health to Model Health
Once your sourcing modes are operating with data contracts and freshness SLOs, the next operational question is when to retrain. The answer depends on which kind of drift you are seeing.
Three drift types, three different operational responses:
- Schema drift is structural. A field changes type, a column splits, a value moves. Catch this at ingestion, in the data contract validation step. Cost to fix: hours if caught at the boundary, days if it leaks into a training set.
- Data drift (statistical drift) is a distributional phenomenon. The values in a stable schema have shifted; the producer is generating different content even though the structure is unchanged. Catch this with feature-level monitoring and dataset-level distribution checks (KL-divergence, population stability index). Cost to fix: usually a retraining run with a refreshed dataset.
- Concept drift is semantic. The relationship between inputs and outputs has changed; the world the model was trained on is no longer the world it is operating in. Catch this only with held-out evaluation sets and gold-label feedback. Cost to fix: rethink, not retrain.
Retraining cadence triggers come in three flavors. Threshold-based triggers fire when a drift metric exceeds a calibrated baseline; well-suited to data drift. Time-based triggers fire on a schedule; well-suited to stable-distribution use cases. Event-based triggers fire on external signals (a new product launch, a regulatory change); well-suited to concept-drift-prone domains.
The common mistake is blanket “retrain weekly” without baseline calibration. This produces alert fatigue and wastes compute on stable distributions. The opposite mistake is “retrain when something breaks,” which is the same as not having a retraining cadence at all.
For the upstream framework for choosing between fine-tuning and RAG architectures, which determines which kind of drift you most need to monitor, see our fine-tuning vs RAG comparison.
Expert Insights. Most production drift stories that reach a postmortem are actually schema drift, which the team mistook for data drift. The structural change leaked through the contract layer, the dataset shifted statistically as a downstream effect, and the team spent a week investigating distributions when the root cause was a renamed field upstream. Catch schema drift at the boundary and the rest of the drift work gets cheaper.
Quick Summary. Three drift types: schema (structural, caught at ingestion), data (distributional, caught with feature monitoring), concept (semantic, caught with eval sets). Match retraining triggers to drift type; blanket schedules waste compute and fail to catch the meaningful changes.
Vendor Evaluation and Lock-in: The Questions Most Ops Interviews Skip
When the sourcing-mode analysis points to a managed-external vendor, the evaluation conversation is where the ingestion fit is settled. Most demos showcase the easy 80 percent of the work. The production of 20 percent is where ops fails. Six questions to ask, optimized for ingestion ops rather than feature breadth.
- What is your data-contract template? A vendor that cannot show you a contract template with the seven fields from H2-3 is selling a feed.
- What is your median schema-drift recovery time? This is the single best signal of internal reliability engineering. Mature vendors track it as a primary SLO; immature ones will not have a number.
- What is your provenance and license-log model? Per-record URL, timestamp, access method, retention, and license documentation, queryable from your side. “We have logs” is not enterprise-grade in 2026.
- What is your delivery-format spec? Idempotency keys, replay support, and partition strategy. The cleaner the spec, the lower your downstream integration cost.
- What is the contract exit and data-portability clause? Look for a 30- to 60-day exit notice, a full schema and history export, and no termination fee for an SLO breach. The cheapest exit is one designed at signing.
- What is your typical onboarding time-to-stable for our source mix? The industry baseline is 2 to 4 weeks for a small pilot and 6 to 12 weeks for a 50-source production rollout. Vendors who quote much faster are usually cutting validation; vendors who quote much slower are operationally immature.
The lock-in conversation mostly centers on the contract exit clause and the delivery-format coupling. Schema-contract lock-in is structurally hard; that is why the data contract has to be portable in the first place. The escape pattern is to require schema export in a tool-neutral format (Avro, Parquet, or a versioned JSON Schema) at signing, and to require a documented replay window. With those, vendor migration becomes a routing-layer change rather than a rewrite.
For the broader provider-selection lens that applies across data-vendor categories, see our B2B data provider selection guide.
Expert Insights. Two questions to ignore in vendor evaluation: how many records they have processed (volume is a feature, not an outcome) and which Fortune 100 customers they list (logos are not SLAs). Substitute a single reference call with a customer who can describe their last incident.
Quick Summary. Six ingestion-ops questions for vendor evaluation. Skip feature demos. Lock-in mitigation lives in the contract exit clause and tool-neutral schema export. The cheapest vendor migration is one designed at signing.
A 30-Day Operational Plan for Data PMs Inheriting an AI Training Data Stack
If you are walking into a stack mid-stream, here is the diagnostic plan that produces a defensible improvement roadmap by day 30.
Week 1, Inventory. Catalog every source. For each one, record the sourcing mode, the retraining cadence it feeds, the current data SLO (or admit there is none), the versioning state, and who owns the contract on your side and theirs. Most stacks do not have this inventory; producing it is half the value.
Week 2, Instrument. Stand up observability for the highest-leverage sources first. Freshness arrival, schema drift detection, volume anomalies, and distribution monitoring at the dataset level. Identify any vendor that is not running on a real data contract. Flag any source that uses rolling-window versioning without semantic dataset versions.
Week 3, Pick the highest-leverage move. The cheapest first move is usually the worst behavioral choice: high freshness latency, frequent schema drift, and no contract. Decide what changes, sourcing-mode change (often in-house to managed external), data-contract negotiation, or versioning instrumentation. Most stacks have one source that is responsible for a disproportionate share of pipeline incidents; that is the source to move.
Week 4, Write the change proposal. Cost, risk, migration plan, and success criteria. Loop in ML and data-platform partners for sign-off. The proposal serves as both your operating plan and your CTO-facing artifact.
The two anti-patterns to resist: do not replatform on day 30 (it is too early to know what you are solving) and do not replace a vendor before you have measured them (the failure may be your contract, not theirs). Observability first; sourcing changes second.
Expert Insights. The 30-day plan produces three deliverables: an inventory document, an observability instrumentation report, and a single change proposal. Each is independently valuable. Stop after these three before recommending anything bigger.
Quick Summary. Week 1 inventory; Week 2 observability; Week 3 highest-leverage change identification; Week 4 change proposal with sign-off. Resist the temptation to replatform; instrument before migrating.
Frequently Asked Questions
What is the right data freshness cadence for AI training data?
Match freshness to retraining cadence. Real-time fine-tuning needs sub-hour; daily fine-tuning needs 1 to 4 hours; weekly retraining handles 24 to 48 hours; monthly evaluation works with weekly freshness. Tighter than retrain wastes budget. Looser silently decays quality. Pair freshness SLOs with distribution monitoring; arriving on time but with drifted distributions is the same problem as being stale.
How do I version AI training data without breaking downstream consumers?
Apply semantic versioning per dataset. Use DVC, LakeFS, or git-LFS to manage versions. Maintain a backward-compatible schema for at least one prior version. Lineage in a feature store keeps consumer joins explicit and lets you debug drift at the version boundary. Without versioning, drift is detected late, and recovery is forensic.
What does a data contract for AI training data actually contain?
Seven fields: typed schema, validation rules (CI-tested), freshness guarantee, idempotency keys, replay support, retention policy, exit, and data-portability clause. A vendor without these is selling a feed, not a service. Adding contracts after a pipeline ships costs four to ten times as much as building them in at vendor selection.
When should we move from in-house extraction to a managed AI training data service?
When schema-drift recovery is consuming more than 20 percent of data-engineering time, when freshness requirements exceed daily cadence on dynamic sources, or when EU AI Act or regulated-workload requirements push per-record provenance into your scope. The shift is not about cost; it is about reclaiming engineering capacity from a maintenance load that does not advance the roadmap.
How do I handle drift in AI training data?
Three drift types, three responses. Schema drift caught at ingestion via data-contract validation. Statistical drift caught with feature-level monitoring and KL-divergence alerts on dataset distributions. Concept drift is caught only via held-out evaluation sets and gold-label feedback. Most postmortems trace back to schema drift mistaken for data drift; instrument the boundary first.
Stop Buying Data. Operate the Boundary.
Treat AI training data as an ingestion-boundary contract, not an asset. Operate the four properties, freshness latency, schema stability, handoff cleanliness, lock-in cost, and the sourcing-mode question answers itself per source. Run the 30-day plan if you are inheriting; run the data-contract question list if you are signing a new vendor; run the drift taxonomy when something breaks.
The teams that get this wrong are not the ones that picked the wrong vendor. They are the teams that picked the wrong abstraction and spent two years compensating with engineering hours. The boundary is the abstraction. Get it right, and the rest gets cheaper.

Sources
- Gartner. Top Predictions for Data and Analytics in 2026. https://www.gartner.com/en/newsroom/press-releases/2026-03-11-gartner-announces-top-predictions-for-data-and-analytics-in-2026
- Flexiana. Data Pipelines for Machine Learning From Ingestion to Training, 2026 Guide. https://flexiana.com/machine-learning-architecture/data-pipelines-for-machine-learning-from-ingestion-to-training-2026-guide
- KDnuggets. 5 Emerging Trends in Data Engineering for 2026. https://www.kdnuggets.com/5-emerging-trends-in-data-engineering-for-2026
- Vodworks. 6 Data Quality Trends for 2026 Shaping Reliable AI and BI. https://vodworks.com/blogs/data-quality-trends/
- Label Your Data. Data Versioning, ML Best Practices Checklist 2026. https://labelyourdata.com/articles/machine-learning/data-versioning
- Label Your Data. AI Training Data, Top 2026 Sources and Dataset Providers. https://labelyourdata.com/articles/machine-learning/ai-training-data
- SmartDev. AI Model Drift and Retraining: A Guide for ML System Maintenance. https://smartdev.com/ai-model-drift-retraining-a-guide-for-ml-system-maintenance/
- Mordor Intelligence. Alternative Data Market. https://www.mordorintelligence.com/industry-reports/alternative-data-market




