

Automated data collection is the use of software, scripts, agents, and managed services to acquire data from external and internal sources without manual intervention. It covers web pages, documents, APIs, files, and sensors.
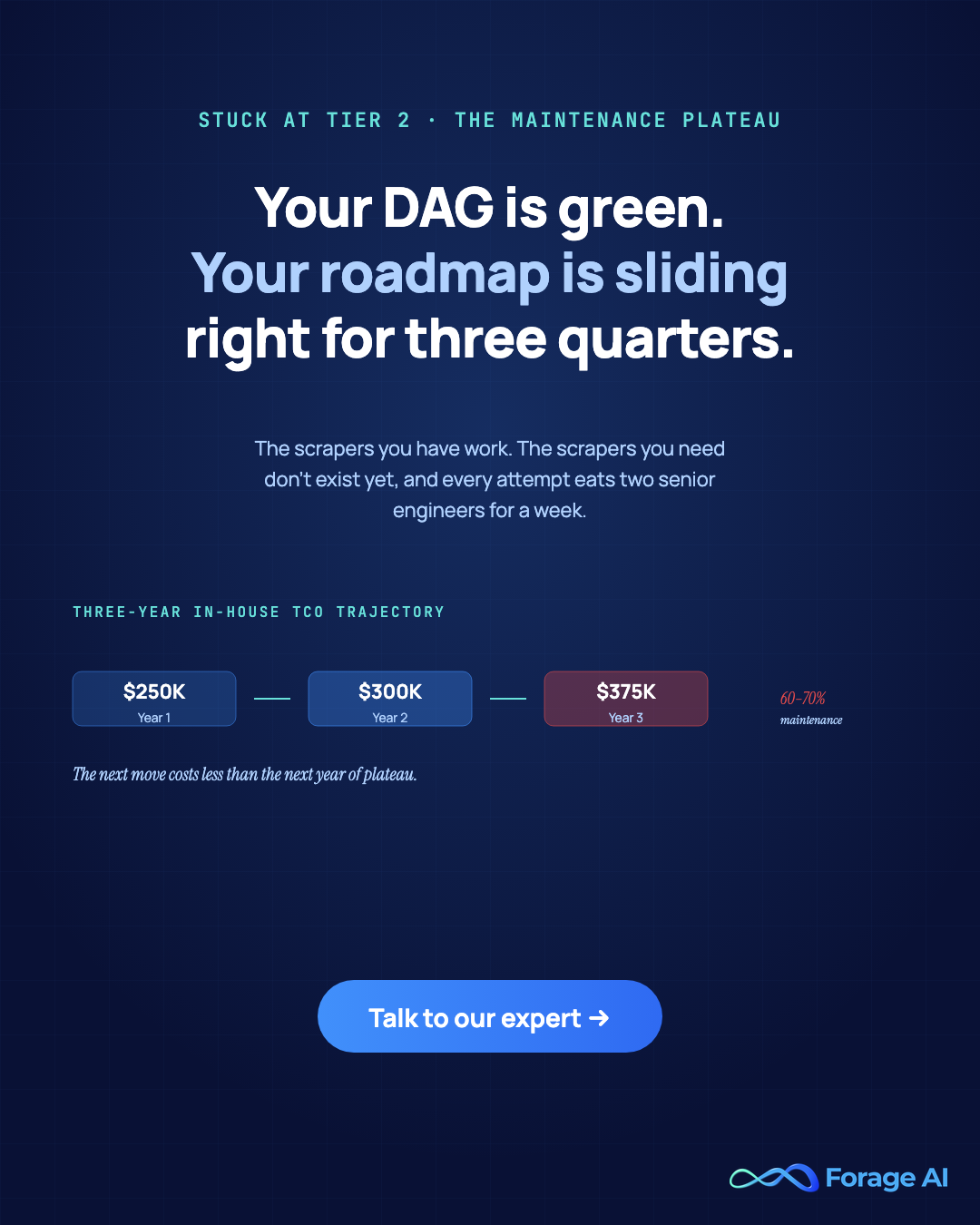
Your Airflow DAG is green. The proxy pool is funded for the quarter. PagerDuty hasn’t fired since Tuesday. And yet, somewhere on your roadmap, the line item that says “add the next 30 long-tail sources” has been sliding right for three quarters. The scrapers you have work. The scrapers you need don’t exist yet, and every attempt to build them eats two senior engineers for a week and produces something that breaks the next time the source changes a CSS class.
That gap between the pipeline you have and the pipeline your product is asking for is the scale wall. This article is about what’s on the other side of it.
The reader we’re writing for already knows what a scheduled extraction is. The question is: which tier of automated data collection your team is actually operating in, what the next move costs, and whether it’s a build or a buy.
Quick Digest
- Automated data collection is a four-tier maturity model (Manual, Scripts, Tools, Managed), and most data-product builders plateau at the Tools tier.
- The hidden cost of plateauing is a maintenance tax that swallows 60-80% of data-engineering capacity
- The jump to Self-Healing is architectural. The jump to Managed is organizational. They are not the same decision.
- The article closes with a 10-question diagnostic that lets you locate your team in 60 seconds and walk into your next leadership conversation with a clear ask.
Why Automated Data Collection Is Now the First Mile of Every AI/Analytics Program
The collection layer used to be a back-office concern. In 2026, it is the most-watched mile in the data stack, because everything downstream (dashboards, RAG indexes, model fine-tunes, agentic features) runs on data the team had to go fetch. Roughly 80-90% of enterprise data is unstructured, and acquiring it cleanly is where AI programs live or die.
The numbers from 2026 make the point bluntly. Fivetran’s 2026 benchmark reports that 97% of enterprise leaders say pipeline failures have delayed analytics or AI initiatives. Gartner finds that 57% of organizations describe their data as not AI-ready, and projects that 60% of AI projects will be abandoned over weak data foundations. The model layer is not the bottleneck. The acquisition layer is.
This is also why automated data collection can’t be reduced to a tool category. It is the production discipline upstream of every data product. As Barr Moses of Monte Carlo put it in her 2026 predictions, “AI will only ever be as useful as the first-party data that powers it.” Treat collection as a software-engineering practice. Treat it as cheap, and the model never gets to act on data it can trust. For the foundational view of the upstream layer, see Forage AI’s web data extraction overview.
Expert Insight: In production, the failure mode that matters most isn’t downtime. It’s silent partial success. A scraper returning 200s on a cached page processes cleanly through the pipeline and only gets caught when a customer asks why last week’s number doesn’t reconcile. The collection layer needs validation, not just monitoring.
Quick Summary: Is automated data collection really an AI problem now? Yes. With 97% of enterprises reporting pipeline-caused AI delays, and the EU AI Act’s August 2, 2026, enforcement adding audit obligations for training and inference data, collection sits within the AI risk surface. If it’s brittle, the model is brittle.
The Automated Data Collection Maturity Model: Manual to Scripts to Tools to Managed
The cleanest way to evaluate where your team sits is to stop thinking about data extraction automation as a binary and start treating it as a maturity progression. There are four named tiers (Manual, Scripts, Tools, Managed), plus a fifth state, Self-Healing, that sits as the architectural waypoint between Tools and Managed. Tiers are not steps. Teams stay at any tier indefinitely. The model tells you where you are, not where you should be.

| Tier | Name | What it looks like | Who lives here | Breakpoint that forces a move up |
|---|---|---|---|---|
| 0 | Manual | Analyst + spreadsheet + copy-paste | Low-volume, high-judgement work | Volume exceeds analyst capacity |
| 1 | Scripts | Python + Scrapy/Playwright; one engineer owns each | First-time builders, R&D pilots | More than 3 sources or weekly refresh |
| 2 | Tools | Orchestrator + alerts + proxy pool + dashboards | Most data-product builders (the plateau) | Maintenance share > 25% of eng capacity |
| 3 | Self-Healing | Failure classification + selector regen + schema validation | Teams with 3+ senior DEs and a long horizon | Source count > 100 or contractual SLAs |
| 4 | Managed | External partner owns the lifecycle; client keeps data ownership | Product-bearing data businesses | The collection layer is the product input, not the product |
The breakpoint pattern is what most articles miss. Each tier is internally consistent. It works at its design volume. What forces the next move is not technology, it’s maintenance math. Adding the 30th source should cost less engineering time than adding the 3rd. When it costs more, the tier you’re on has reached its limit.
There’s a softer trap inside the model. Reliability is not correctness. A clean DAG run is a clean schedule, not clean data. Plenty of low-code tools deliver Tier 1 reliability while marketing themselves as Tier 3. Read the maturity model against your data quality outcomes, not your job-completion rate.
Expert Insight: The teams that move tiers cleanly are the ones that name their current tier honestly. Most teams place themselves one tier higher than the operational reality. The fastest way to lose six months is to claim Tier 3 while running a Tier 2 stack with a layer of AI marketing on top.
Quick Summary: Why is this a model and not a switch? Because each tier has a different cost shape and a different failure surface. A switch implies that more automation is always better. The model says the right answer depends on source count, refresh cadence, downstream consumers, and whether collection is your product or your input.
Tier 0-1: Manual to Scripted Collection (Where Most Teams Start)
Tier 0, an analyst with a spreadsheet and a copy-paste habit, is rational for low-volume, high-judgment work. Twelve sources refreshed quarterly, where the human is reading context as much as data, is a Tier 0 workflow, not a failure. Don’t automate it.
Tier 1 is the first custom Python script. The 2026 stack settled into Scrapy or Playwright for fetching, BeautifulSoup or lxml for parsing, requests when the API exists, and a CSV write at the end. LLM-assisted coding with Cursor or Claude Code has collapsed the Tier 0 to Tier 1 build time from a week to a few hours, which is why a lot of teams now skip Tier 0 entirely for any source they expect to revisit.
The honest description of a Tier 1 script: no retries, no shared schema, no observability beyond a stdout log, and one engineer who can debug it. Cron is a scheduler, not orchestration. Wrapping a Tier 1 script in cron makes it a Tier 1 script that runs every Tuesday at 3 a.m., not a Tier 2 pipeline. For the long-form manual-vs-automated comparison, see Forage AI on the manual-to-automated transition.
What Scripts Will Not Solve (Negative Knowledge)
Cron is not orchestration. There is no rate-limit handling, no auth renewal, no proxy rotation at any meaningful scale, no structured retry. Practitioner data backs the pain shape. Initial build runs 2 to 4 weeks, ongoing maintenance settles around 5 to 10 hours per week per script, and after the first year a typical team is spending 20 to 30% of engineering cycles on script maintenance. If you have more than three sources or a weekly refresh, you’ve already outgrown Tier 1.
Expert Insight: The most expensive Tier 1 mistake is hiring a data engineer to “maintain the scrapers.” Within two quarters that hire is fully booked on triage, the new-source backlog hasn’t moved, and the team has accidentally chosen Tier 2 in headcount while still operating Tier 1 architecturally.
Quick Summary: When is staying at Tier 1 the right call? When the source count is small, the refresh cadence is forgiving, and the engineer who owns the script is unlikely to leave or be reassigned. Anything else, and the script tier is borrowed time.
Tier 2: Tools and Scheduled Pipelines (Where Most Teams Plateau)
Tier 2 is what most data-product builders mean when they say “we have automated collection.” It is an orchestrator (Airflow, Dagster, or Prefect), a set of cron-scheduled DAGs, PagerDuty or Slack alerting, a shared proxy pool, a dashboard, and an on-call rotation. It looks organized. It feels automated. And it can sit there for three years quietly compounding cost.

The Maintenance Tax
The single most important fact about Tier 2 is the maintenance tax. The data is specific and converges across sources. Monte Carlo, 2026: data teams spend 60 to 80% of their time maintaining fragile pipeline systems. Kadoa, 2026: One customer spent 40% of their weekly engineering hours on scraper fixes alone before they replaced the layer. tendem.ai, 2026: the realistic three-year TCO trajectory for an in-house web-scraping team is roughly $250K in Year 1, $300K in Year 2, $375K in Year 3, with maintenance overhead accounting for 60-70% of that total.
The tax compounds non-linearly because the shared infrastructure (proxy pool, alerting, dashboards, on-call) does not amortize across long-tail sources. The first ten sources share the proxy budget. The next 50 each add their own failure modes for the on-call to learn. Adding the 30th source is materially harder than the 3rd, and the cost curve is not the one most engineering leaders mentally model when they greenlit the platform. For a deeper breakdown of failure modes, see why most enterprise data pipelines break.
Named Failure Modes at the Scale Wall
Every Tier 2 team meets the same five failure modes. Naming them is half the work, because the dashboards almost never name them.
- Schema drift. The website adds a new field, your parser silently commits partial data, and downstream consumers see a clean row that’s missing the column nobody noticed.
- Silent gaps. The scheduled job completes with a 0-row result. The alert fires only on hard failure, not on empty success.
- Cascading auth failures. The token expires mid-run, half the load completes, and the partial state is hard to reconcile from logs.
- Rate-limit regressions. The source quietly tightens its throttle, your backoff isn’t adaptive, and over a week, your IP space gets banned without anyone noticing the slow accumulation of 429s.
- Weak observability. The metric is “did the DAG complete?,” not “is the data structurally correct and within the expected range?” That is the metric gap product teams regret most often when they finally migrate.
Why Tier 2 Feels Like Automation but Isn’t (Negative Knowledge)
A clean Airflow DAG is a clean schedule, not a clean pipeline. “We have alerting” describes detection, not validation. Fivetran-style ELT solves Tier 2 cleanly for well-structured API sources, but it does not handle web or document collection. Those still sit on whatever homegrown stack lives upstream. As Chad Sanderson, author of Data Contracts, has argued for years, prevention belongs in CI/CD, not in downstream dashboards. By the time the data lake sees the problem, the contract was already broken upstream.
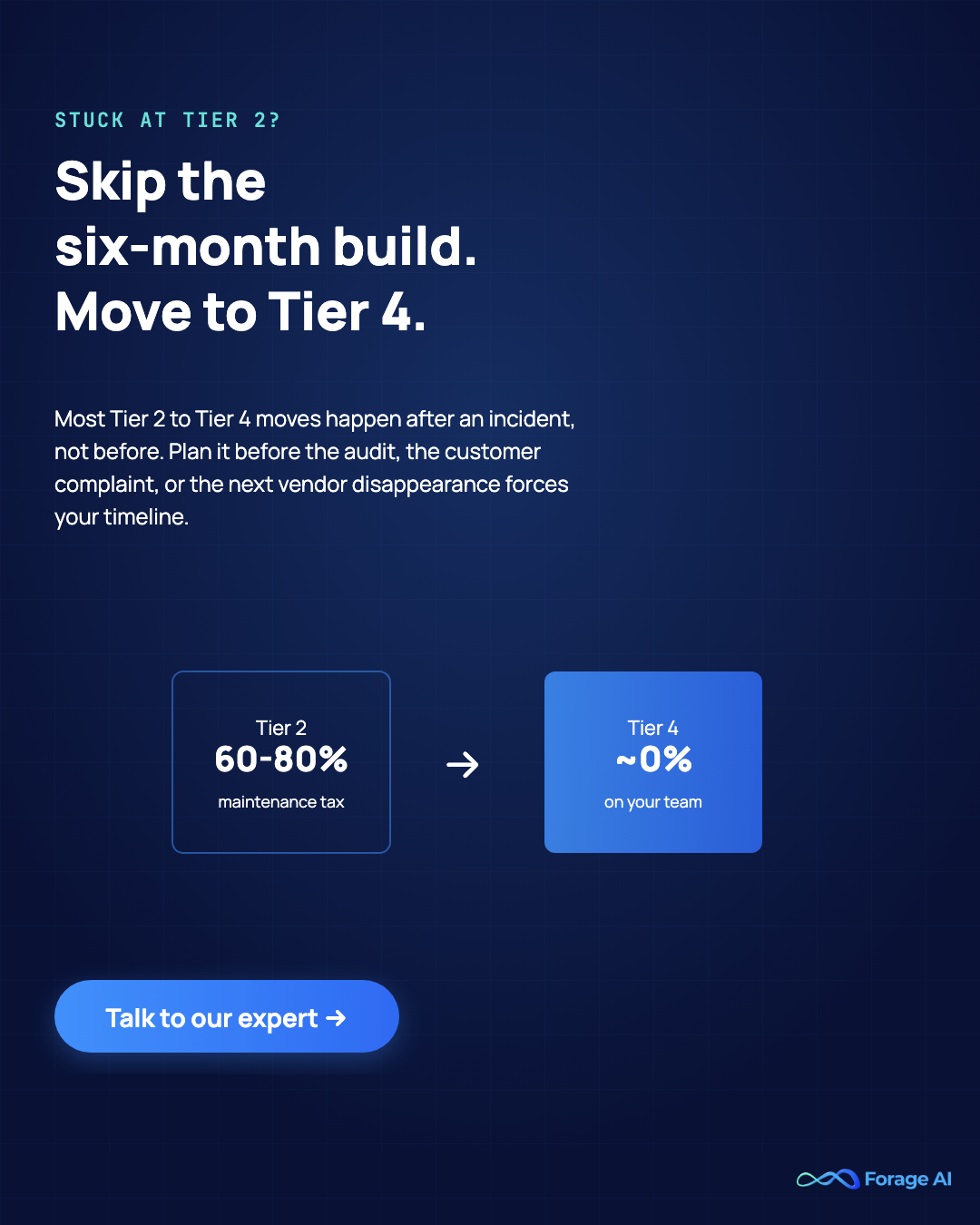
The verdict on Tier 2 is not “it’s broken.” It is “it stops paying back at scale.” If more than 25% of data-engineering capacity is on collection maintenance, that is a Tier-2 problem, not a staffing problem. Adding another engineer to maintain the scrapers will go underwater in roughly six months.
Expert Insight: The Tier 2 plateau usually ends with a single incident, not a planned migration. A bad audit, a customer complaint about stale data, a key source disappearing for a weekend nobody noticed. Plan for the move before the incident, because the incident never gives you the time you need to plan.
Quick Summary: is Tier 2 ever the right destination? For a steady-state portfolio of 10 to 25 sources with weekly refresh and no AI downstream, yes. For everything else, Tier 2 is a stopover. Treating it as a destination is what produces the maintenance tax surprise in the next budget cycle.
Tier 3: Self-Healing Pipelines (The Architectural Breakthrough)
Tier 3 is the first tier where the pipeline classifies failures rather than blindly retrying. A 403 is not a selector miss. An empty DOM is not a CAPTCHA. A timeout is not a layout change. Classification is the heart of Tier 3 because it makes targeted recovery possible.
What Self-Healing Actually Means
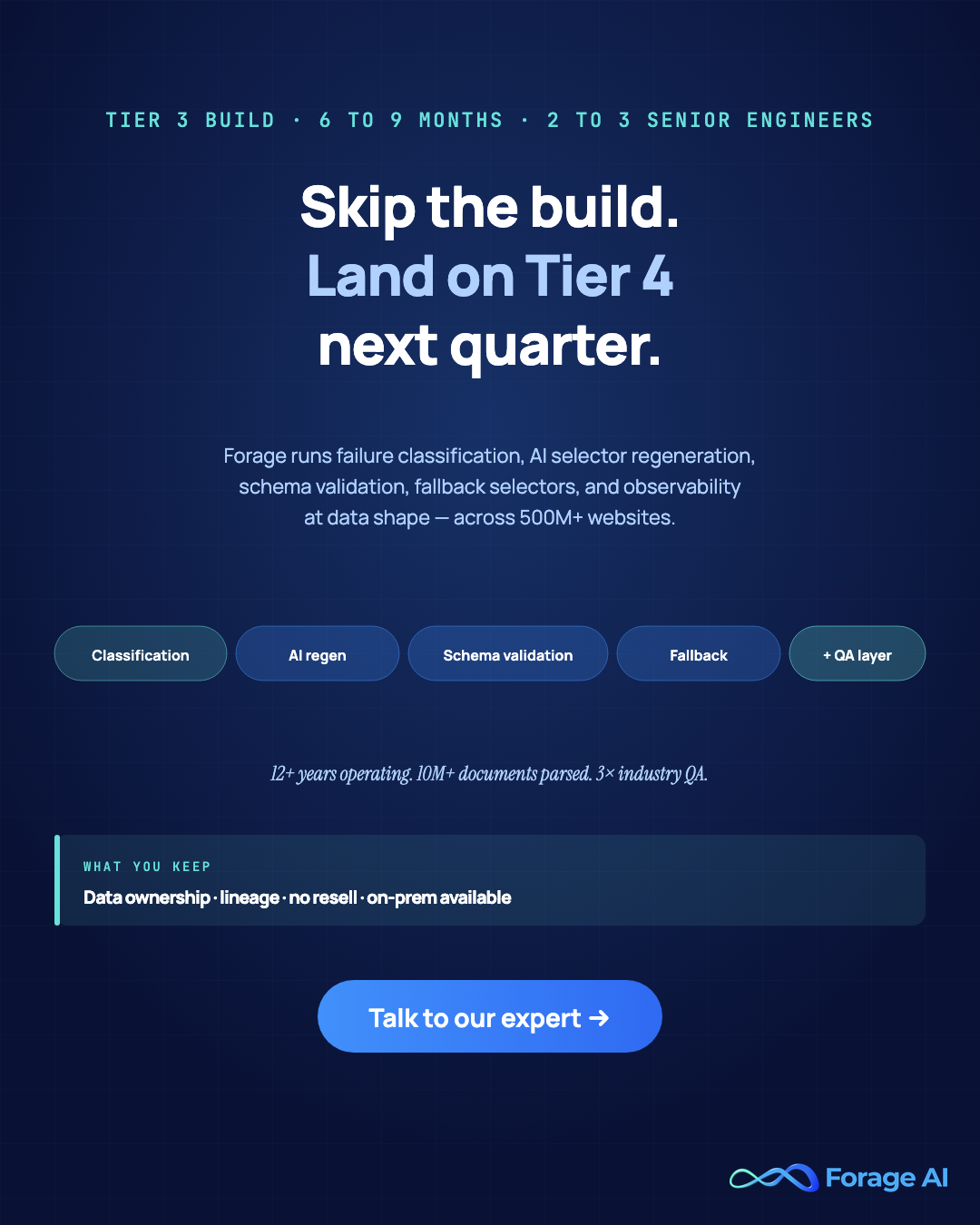
A working Tier 3 stack has five layers, none of which are negotiable.
- A failure-classification layer that bins every error into a known category and routes recovery accordingly.
- AI-driven selector regeneration that fires when a source’s layout signature changes, regenerating the deterministic extraction code rather than calling an LLM at runtime.
- Schema validation at write time with Pydantic in Python or Zod in JavaScript. Non-negotiable. If the row doesn’t fit the contract, it doesn’t land.
- At least two fallback selectors per critical field, primary and backup, with the primary marked degraded if it fails twice in a window.
- Observability at data shape, not just job status. The alert is “row count dropped 40% from baseline,” not “the DAG ran.”
The architecture takes 6 to 9 months to stand up cleanly with 2 to 3 senior data engineers, plus ongoing investment in observability and schema governance. The McGill 2025 study, summarised by Kadoa, showed AI methods maintaining 98.4% accuracy even after page structures changed. That’s the proof Tier 3 isn’t theoretical, but it’s also proof that the architecture matters more than the model. For proven Tier 3 patterns at enterprise scale, see the most reliable ways to automate enterprise web data extraction.

The Role of AI (And the Trap)
There are two AI collection patterns, and only one scales. AI-at-runtime means calling an LLM per page to extract structured fields. It is expensive, slow, and variable. Kadoa’s testing showed that ChatGPT-based scraping ranged from 0% to 75% accuracy on identical tasks. AI-at-setup means using an LLM to regenerate deterministic extraction code when a source changes. It is cheap, adaptive, and the pattern that actually compounds. As Tavis Lochhead of Kadoa put it, “the hard parts are everything else: maintenance when sites change, scaling to thousands of sources, and knowing whether the data is actually right.” AI doesn’t remove those hard parts. It just changes which layer fights them.
This is the production reality of Tier 3 at managed scale. Forage AI operates pipelines that self-update as sites change across more than 500 million websites crawled over 12 years, with a multi-layer QA stack and RLHF feedback loops that fold human corrections back into model behavior. For deeper coverage of the AI agent layer, see the best AI agent solutions for large-scale web data extraction.
What Tier 3 Will Not Solve (Negative Knowledge)
Self-healing is not source discovery. Knowing what to collect is a different problem. It is not about generating compliance evidence; 98% reliability and tamper-resistant audit logs are different artifacts. It is not human-in-the-loop QA; automated validation flags structural issues, not domain-correctness issues, and there are domain calls only an expert reviewer can make. And Tier 3 without schema validation is just Tier 2 with better marketing. The validation layer is what gives the rest of the stack its teeth.
Expert Insight: Build-vs-buy at Tier 3 is a legitimate decision, not a foregone conclusion. With three or more senior data engineers, a multi-year horizon, and a portfolio of fewer than 100 well-understood sources, building is rational. Above that source count, the partner option starts winning on TCO without much argument.
Quick Summary: Is Tier 3 worth the build cost? If collected data feeds AI or RAG, Tier 3 is the minimum viable bar. If freshness is included in a customer contract, Tier 3 is required. Below those thresholds, you can stay at a well-run Tier 2 longer than the vendor’s pitch suggests.
Tier 4: Fully Managed Collection (The Top of the Model)
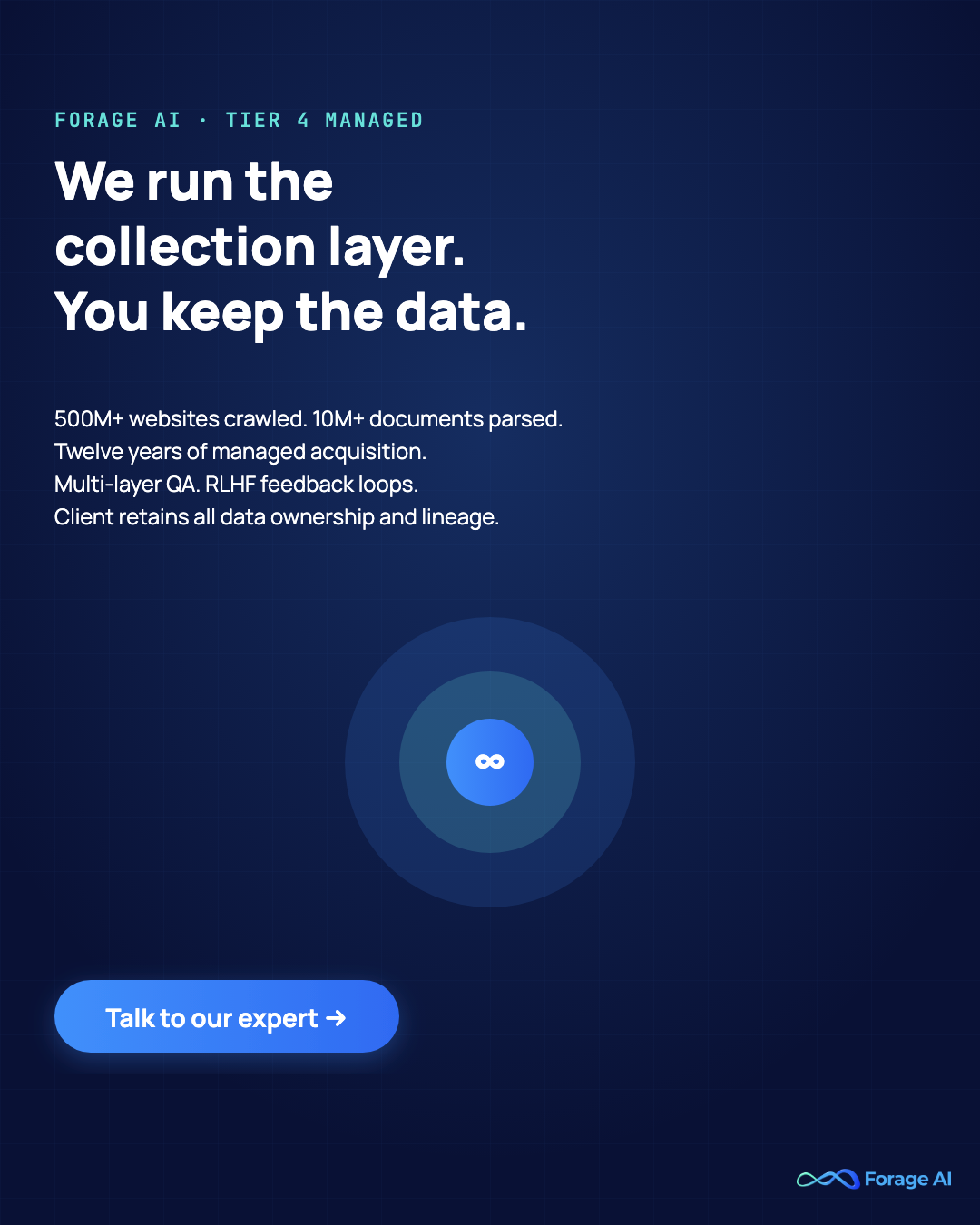
Tier 4 is an organizational decision, not a technical one. The team stops owning the collection lifecycle and hands it to a partner who owns pipeline design, multi-layer QA, monitoring, maintenance, and delivery. The client retains data ownership, lineage, and the right to walk away with everything. The distinction matters: a Tier 4 partner is not a reseller (who sells pre-built datasets) and not a tool vendor (who sells software the client still operates).
What “Managed” Actually Includes
Beyond the Tier 3 architecture, a Tier 4 engagement adds five things a tool license cannot:
- Source discovery and evaluation. The partner helps decide what to collect, not just how.
- Multi-layer QA as a continuous workflow. AI plus human review on a feedback loop, not a one-off audit. Forage AI’s “3x industry-average QA ratio” describes this as a staffing pattern, roughly two QA reviewers for every extraction engineer, with the workflow built into the pipeline rather than bolted on top.
- Domain expertise. Operators who have already seen the patterns in your industry, so the first 20 sources don’t pay the discovery tax twice.
- Dedicated team continuity. The same engineers, quarter to quarter, with institutional memory of every source’s quirks.
- Governance by design. Audit trails, data lineage, no-resell guarantees, and on-prem options where regulation demands them.

Why Layered QA Only Works at This Tier
Multi-layer QA is a tier feature, not a marketing claim. It only works at Tier 4 because it requires three things at once: source volume large enough to justify a dedicated QA team, feedback loops that turn human corrections into model improvements (the RLHF pattern), and organizational separation between the team that collects and the team that validates. None of those three fit inside a tool license. For the deeper view of how human-in-the-loop architectures actually work, see Forage’s coverage of human-in-the-loop data extraction and the broader services landscape.
Compliance as Infrastructure in 2026
The EU AI Act takes effect on August 2, 2026, with penalties of up to €35M or 7% of global annual turnover for the most serious violations. Article 11 requires technical documentation, tamper-resistant logging, transparency obligations, training-data governance, and verifiable deletion. The obligation applies to any collection feeding high-risk AI deployed in the EU, regardless of the company’s headquarters. Raconteur’s 2026 audit guidance is direct: screenshots and declarations are no longer sufficient evidence; only operational evidence (signed logs, lineage, model-version tracking) counts. Tier 4 shifts that evidence generation onto the partner, which is the single largest organizational lift in the move from Tier 3.
The case evidence on Tier 4 outcomes is consistent across industries. Thermo Fisher Scientific automated 53% of its 824,000 annual invoices, reducing processing time by 70%. Allianz cut claim-settlement time by 80% for low-complexity claims. Eletrobras moved document-review accuracy from 50% to 92% and saved $277,377 annually on 65,000 documents. One anonymized enterprise replaced a 15-person manual scraping team and saw first-year costs drop from $4.1M to $270K while data accuracy moved from 71% to 96%. The pattern is consistent across cases: Tier 4 wins on TCO at sufficient volume, and it wins by a wider margin once compliance evidence is in scope. For the full TCO breakdown of build vs. buy, see the 2026 budget analysis.
This article provides general guidance, not legal or compliance advice. Consult qualified counsel for your organization’s specific EU AI Act compliance requirements.
What Tier 4 Will Not Solve (Negative Knowledge)
The most common Tier 4 objection, “we’ll lose control of our data,” is misplaced at any reputable partner. Data ownership, lineage, and no-resell terms are contractual. They are not magic; they are paragraphs in the agreement. Tier 4 is also not appropriate for sub-scale workloads. With only 10 sources and no growth trajectory, the partner relationship overhead is not worth it. And a partner cannot scope your data strategy for you, only with you. The strategic call about what to collect still belongs to the data team. Forage AI’s web data extraction service is built around that division. The client owns the strategy and the data; we own the pipeline and the evidence trail.
Expert Insight: The migration that actually saves money is the one that includes governance, not just collection. Teams that move Tier 2 to Tier 4 for reliability alone often re-inherit the audit problem two years later. Move both at once.
Quick Summary: When is Tier 4 the right call? When the collected data feeds a customer-paid product (think price intelligence for an ecommerce platform, or firmographic enrichment for a sales tool), when collection SLAs sit inside customer contracts, when EU AI Act, HIPAA, or SOC 2 audits are in scope, or when the source count crosses about 100 with daily refresh. Below those thresholds, Tier 3 is honest. Above them, Tier 4 is usually the risk-adjusted winner.
How to Automate Data Collection From Websites: The Operational Playbook
This is the working baseline anyone building Tier 3 in-house ends up with. It is a Tier 2-to-3 bridge, useful as a checklist whether you’re hardening an existing pipeline or scoping a new partner.
The Order of Operations
- Check for a public API first. APIs are 10 to 100x faster than HTML parsing with no rendering overhead. If it exists and has the fields, use it. Always.
- Respect rate limits. 0.5 to 10 requests per second, depending on the source. Exponential backoff. Honor robots.txt and the website’s published terms.
- Rotate proxies. Residential proxies are slower and cleaner; datacenter proxies are faster and cheaper but more flaggable. Mix by source profile, not by default.
- Headless browser only when necessary. Playwright is the default for JS rendering in 2026. Don’t reach for it when a plain HTTP GET would have worked.
- Schema validation at every write. Pydantic (Python) or Zod (TypeScript). The row either fits the contract or it doesn’t land.
- Retry with classification, not blind backoff. 403 triggers proxy rotation. Selector miss triggers fallback selector. Timeout triggers exponential retry. CAPTCHA triggers escalation, not retry.
- Monitor data shape, not just job status. Alert when extraction drops to zero rows, or when row count drifts more than 10% from baseline.
- At least two selectors per critical field. Primary plus fallback. Single-selector-per-field is a latent bug waiting for the next site redesign.
Apify’s 2026 best-practices guide synthesizes six of these and reports that those six cover roughly 90% of production failure modes. The order matters less than the discipline of running the full list before declaring a source done.

What This Playbook Won’t Handle (Negative Knowledge)
The playbook handles the mechanics. It does not handle source discovery, compliance evidence generation, domain validation, or scale beyond what a two-engineer team can sustain. Two persistent myths are worth naming. “Scraping is illegal” is overstated. The real legal tests are robots.txt, the terms of service, and the type of data being collected, and a qualified attorney should weigh in on any high-stakes deployment. “AI will handle it” is half-true. Only AI at setup, not AI at runtime, holds up at production scale. For an enterprise-scale view of the playbook in operation, see how enterprise web data extraction scales reliably.
This article is for informational purposes only and does not constitute legal advice. Consult a qualified attorney for legal guidance specific to your scraping deployment.
Expert Insight: The playbook step that teams most often skip is step 5. Schema validation at write time feels paranoid until the first time you ship six weeks of subtly malformed data to a customer. After that, every engineer on the team becomes a believer.
Quick Summary: do I really need headless browsers for every source? No. For roughly 60% of sources, a plain HTTP request with proper header management is faster, cheaper, and more reliable than spinning up a browser. Reach for Playwright when the page genuinely needs JS execution, not by reflex.
The 2026 Stack: Agentic AI, MCP, and EU AI Act
Three shifts are reshaping the collection layer in 2026. They don’t replace the maturity model. They change, which tier most teams find themselves at by accident.
From Scripts to Agents
The classic collection is procedural: fetch the URL, apply the selector, write the row. Agentic collection is goal-oriented: observe, reason, decide, validate, and recover. It is already running in production. Agentic AI traffic grew 7,851% year-over-year, and AI scraper traffic grew 597% over the same period, per Information Age 2026. The shift matters operationally because agents are non-deterministic. You cannot test them the way you test a procedural script. Build validation around them. Don’t trust them blindly.
MCP as the New Default Protocol
Anthropic released the Model Context Protocol in November 2024. By 2026, Firecrawl, Bright Data, Playwright, and Crawl4AI all ship MCP-compatible servers. The practical effect: an LLM client can invoke a collection task the way it invokes a function. MCP does not fix reliability. It collapses integration friction. The same Tier 2 problems still exist; they’re just easier to wire into an agent.
Compliance as Part of the Stack
The EU AI Act’s Article 11 obligations make the audit trail a piece of infrastructure. If the current stack cannot produce a signed log tying output to source, model version, and governing policy, it will not pass a 2026 audit. Chip Huyen, author of AI Engineering, has framed pipeline brittleness as the dominant bottleneck for production AI, and in 2026, brittleness is also a compliance exposure. Tier 4 is a partner, not a tool, and in 2026, that distinction is the audit difference. Gartner projects a 60% reduction in manual data-management intervention by 2027, but only for teams whose collection layer is audit-ready by the August 2026 deadline.
What the 2026 Stack Won’t Do (Negative Knowledge)
Agents are not deterministic. Treat them as components, not solutions. MCP is a protocol, not a product. It doesn’t handle auth, rate limits, or data quality. And compliance posture doesn’t ship with any of these tools. It has to be designed into logging, lineage, and governance from day one.
Expert Insight: The teams that arrive at the 2026 deadline with a clean audit trail are not the ones who bought the most tooling. They are the ones who decided two years ago that compliance was an architectural concern, not a documentation exercise.
Quick Summary: Will MCP and agentic collection make Tier 2 obsolete? No, but they will make a poorly-run Tier 2 less defensible. The economics of agent-mediated collection only work on top of a self-healing or managed substrate. Without that substrate, agentic collection is a faster way to produce the same silent failures.
Self-Assessment: Which Tier Is Your Collection Layer Actually On?
Most teams place themselves one tier above operational reality. The point of this section is to make that diagnosis quickly. Answer the ten questions below honestly. The score interpretation comes after.

The Ten-Question Diagnostic
- Can you answer “how fresh is every source right now?” without asking a specific engineer?
- When a source changes its layout, does your system notice within an hour?
- Is there schema validation on every collection write?
- When a job returns empty, does your system distinguish “empty because broken” from “empty because no new data”?
- Is more than 25% of your data-engineering capacity going to collection maintenance?
- Can you produce a signed audit trail from a collected record back to its source, model version, and governing policy?
- Do you have a named person whose sole responsibility is collection QA?
- When you add a new source, does it cost less engineering time than the previous one did?
- Is your collection SLA contractually guaranteed to downstream consumers?
- Do you retain data ownership and lineage independent of any collection provider?
How to Read Your Score
- Mostly “no” on 1-4: Tier 1 or a broken Tier 2. The next move is either to harden the foundation or skip it.
- “Yes” on 5: stuck at Tier 2 with compounding maintenance tax. Build vs. buy is urgent, not aspirational.
- “Yes” on 1-4 but “no” on 6-9: Tier 3 for reliability, Tier 2 for governance. EU AI Act audit risk is open.
- “Yes” on most of 1-9: Tier 3 or Tier 4. The question is partner selection, not whether to move.
The Build-vs-Buy Overlay
Stuck at Tier 2 and deciding next? Build Tier 3 in 6 to 9 months with 2 to 3 senior data engineers and sustained investment, or buy Tier 4 with a managed partner who owns the lifecycle. The right answer depends on three variables: how strategic collection is to your product, how many sources you run at steady state, and whether your compliance obligations have pushed audit-evidence generation onto the partner. For the full framework, see the build-or-buy strategic guide.
Scoring Yourself Accurately (Negative Knowledge)
Most teams that move Tier 2 to Tier 4 do so after a specific failure event (a broken vendor, a failed audit, a product incident), not a planned migration. The cleanest moves are the ones planned before the incident. Skipping Tier 2 to Tier 4 without addressing the governance question separately is also a trap: you end up with outsourced reliability and unresolved data-ownership gaps.
Expert Insight: The question on this list that most predicts tier accurately is question 8, whether adding a new source costs less engineering time than the last one. If the curve is flat or rising, no amount of tooling has actually changed the underlying tier.
Quick Summary: what’s the fastest signal that we’re stuck at the Tier 2 plateau? Question 5 plus question 8. If maintenance is over 25% of engineering capacity and new sources are getting more expensive, not less, you have the diagnosis. The next conversation is about which tier to move to and how.
FAQ
What is automated data collection? Automated data collection is the use of software, scripts, agents, or managed services to acquire data without manual intervention. Operationally, it lives on a four-tier maturity model (Manual, Scripts, Tools, Managed), with a Self-Healing architectural state between Tools and Managed.
What are the methods of automated data collection? Common methods include OCR and IDP for documents, web scraping and API ingestion for online sources (the backbone of use cases like competitor price tracking, lead enrichment, and market monitoring), barcode, RFID, or QR codes for physical inventory, IoT sensors for telemetry, and electronic forms for first-party capture. The method matters less than the maturity tier operating it.
What’s the difference between automated data collection and data extraction? Collection is the umbrella: acquiring data from any source. Extraction is the structural sub-step that turns raw acquired data into structured records. Most enterprise pipelines do both, and the failure modes usually surface at the extraction layer even when the collection layer logs success.
Is AI-based automated data collection reliable enough for production? Yes, when the architecture is right. The McGill 2025 study showed 98.4% accuracy maintained after structural changes, but the pattern was AI-at-setup (regenerating extraction code), not AI-at-runtime (ChatGPT-style per-page extraction, which varies 0 to 75% on identical tasks).
How much does it cost to automate data collection at enterprise scale? In-house Tier 3 for around 100 sources runs roughly $250K in Year 1, $300K in Year 2, $375K in Year 3 (tendem.ai, 2026). Managed Tier 4 is typically cheaper at that volume and removes hiring and retention overhead.
When should I build in-house vs. buy a managed collection service? Build if you have three or more senior data engineers, fewer than 50 stable sources, and collection is strategic to your product. Buy if paying customers depend on the data, compliance obligations are in scope, or the source count is above 100 with high refresh.
Conclusion
The reader who arrived here looking for “tools to automate data collection” leaves with a different question: which tier is my team actually on, and what does the next move cost? Collection is the first mile of every 2026 AI and analytics program. The Tools tier looks like automation and silently consumes engineering. The decision is no longer whether to automate. It is which tier in the next twelve months, and at what cost.
If your team isn’t sure where it sits, run the diagnostic on the next sprint planning call. The answers come fast. The conversation that follows is the one that actually moves the budget.
Related Articles
- Intelligent Document Processing Solutions for Faster Workflows. For readers whose collection is document-heavy.
Sources
- Fivetran, 2026. Enterprise Data Infrastructure Benchmark Report.
- CDO Magazine, 2025. Unstructured Data: The Hidden Bottleneck in Enterprise AI Adoption.
- Gartner via aimultiple, 2026. Automated Data Collection Tools and Use Cases in 2026.
- Monte Carlo, 2026. 9 Trends Shaping the Future of Data Management; 10 Data and AI Predictions for 2026.
- Kadoa, 2026. How AI Is Changing Web Scraping in 2026.
- tendem.ai, 2026. Web Scraping Cost Pricing Guide: Hiring a Web Scraping Service vs Building In-House.
- Multimodal, 2025. 17 Useful AI Agent Case Studies.
- Information Age / ACS, 2026. AI Internet Traffic Surges as Agents Swarm the Web.
- Secure Privacy, 2026. EU AI Act 2026 Compliance Guide.
- Raconteur, 2026. EU AI Act Compliance: A Technical Audit Guide for the 2026 Deadline.
- McGill University, 2025. AI Extraction Robustness Study (cited via Kadoa).
- Anthropic, 2024. Model Context Protocol announcement.
- IBM. The True Cost of Poor Data Quality.
- Chad Sanderson. The Rise of Data Contracts (Data Products Substack).
- Chip Huyen, 2024. AI Engineering (O’Reilly).
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




