

On the world’s largest e-commerce marketplace, prices change roughly 2.5 million times a day. The average product gets a new price every 10 minutes, and about 40% of those changes happen within a minute of the previous one (industry repricing benchmarks on the largest marketplace, 2026). That data is usually quoted as proof that real-time pricing has arrived.
It has. But that’s the easy part of the story.
Tracking those price changes is price monitoring. Doing something useful with them is price intelligence. The two are not the same, and the gap between them is where most pricing-data programs stall. In 2026, the ecommerce teams pulling ahead aren’t the ones with the fastest scraper. They’re the ones who have built a real intelligence layer on top of a data foundation they can trust.
This article is for the person scoping that capability. You may have tried off-the-shelf tooling, watched it deliver a competitor price feed, and then realized you still couldn’t answer the questions that mattered: where do our prices sit right now? Which SKUs are price-sensitive? Is that competitor running a clearance or shifting strategy?
Quick Digest
- What price intelligence is, and how it differs from price monitoring, repricing, and dynamic pricing.
- The five layers of a real price intelligence capability, framed as a stack you can scope against.
- Why the data foundation matters more than most tools admit, and where it usually breaks.
- The intelligence layer itself: competitive positioning, elasticity signals, and market dynamics.
- The failure modes to plan for, and how to think about what to build versus what to buy.
What Price Intelligence Is (and What It Isn’t)
Price intelligence is the capability that turns raw competitor pricing data into pricing decisions. It sits between the data layer (what competitors are charging) and the action layer (what you do about it). It is a capability, not a tool.
The 2026 framing has shifted. Five years ago, “price intelligence” meant competitor price tracking tools. Today, the term covers the analytical work that sits on top: a continuous, AI-enabled decision layer that turns live pricing data into revenue decisions.
To make this concrete: in e-commerce today, roughly 38% of companies anchor their pricing on competitor prices, 33% use value-based pricing (what the customer is willing to pay), and 30% use cost-plus pricing (cost plus margin) (Elevated Signal, 2026). The competitor-anchored group lives or dies on the quality of its price intelligence.
Price monitoring vs price intelligence: the distinction that decides everything
These two terms get used interchangeably, and it causes real damage when teams scope their work.
Price monitoring is the mechanic: collecting competitor prices, watching for changes, and feeding a database. It’s the plumbing. If you have a scraper pulling competitor PDPs (product detail pages) and dumping prices into your warehouse, you have monitoring.
Price intelligence is the meaning: turning that feed into competitive positioning, elasticity estimates, and market-dynamics signals. It’s analytical work that sits on top of monitoring.
Repricing is a downstream action: changing your own prices, often via rules, in response. Dynamic pricing is the broader discipline of setting prices in real time based on multiple signals. Repricing is one form of dynamic pricing. Price intelligence informs both, but it isn’t either.
The common misconception worth pushing back on: “We have a price tracker, so we have price intelligence.” You don’t. You have one layer of a five-layer capability. For the mechanics of the tracker itself, see our ecommerce price monitoring piece, the operational sibling to this article.
Expert Insights
The 2026 industry analysis showing 38/33/30 split across competitor-based, value-based, and cost-plus pricing strategies means roughly two in five businesses depend directly on the quality of their price intelligence to make daily decisions (Elevated Signal, 2026). In our work with ecommerce data programs, the most common scoping error we see is teams treating the price feed as the deliverable. The feed is the input. The intelligence is what someone has to build on top of it.
Quick Summary
“If we already have a price tracker, do we have price intelligence?” No. A tracker gives you monitoring, which is one of five layers. The intelligence is the analytical work that turns tracked prices into positioning, elasticity, and market-dynamics signals.
Why Price Intelligence Matters Now
The numbers at the top tell the operating reality: 2.5 million daily price changes on the largest marketplace, 40% within a minute of the previous move. Whatever your category, the velocity floor in 2026 is set by marketplaces that continuously change prices. Slow pricing decisions are measurably expensive.
What “real-time” actually means depends on the category. Commodity electronics on marketplaces can require sub-hour freshness. Fashion and home goods may tolerate sub-day. B2B and regulated categories often run on sub-week cycles. The freshness expectation varies by category, and the downstream stack (monitoring, intelligence, action) inherits the freshness from the data layer. For teams that need to detect price changes on target pages, website change monitoring is the underlying mechanism.
The economic case is well-documented. Strong dynamic-pricing programs deliver 2-5% sales growth and 5-10% margin improvement in retail (McKinsey, 2024). The asymmetry is real: a competitor can undercut a hero SKU before your morning standup, and a category manager who finds out at 11 a.m. has already lost the morning’s traffic.
There is a counter-trap. “Real-time everywhere” is not the right ambition for every category. Fashion, regulated industries, and B2B catalogs don’t behave like marketplace electronics, and pretending they do results in over-engineered pipelines that miss slower, more meaningful signals, like promotional cadence.
Expert Insights
McKinsey research finds 2-5% sales growth and 5-10% margin improvement from strong dynamic-pricing programs (McKinsey, 2024). The 2026 shift we see in client conversations is from periodic pricing reviews to continuous decisioning. That shift is what’s stretching data foundations the most.
Quick Summary
“Do I really need real-time price intelligence?” Depends on your category. Marketplaces and commodity electronics need sub-hour freshness; fashion and B2B can run on daily or weekly cadence. The wrong move is defaulting to real-time everywhere; the equally wrong move is assuming your category doesn’t need it.
The Price Intelligence Capability Stack, Five Layers
Here’s the mental model. Price intelligence is a five-layer capability stack:
- Data Extraction, pulling competitor pricing data from websites, marketplaces, and feeds.
- Product Matching, linking competitor SKUs to your own products so prices being compared are for the same thing.
- Price Monitoring, tracking, normalizing, and storing matched prices over time.
- Intelligence, turning monitored prices into positioning, elasticity, and market-dynamics signals.
- Action, feeding decisions into repricing engines, dashboards, or category-manager workflows.

Each layer’s failures propagate upward. Intelligence is only as good as monitoring; monitoring is only as good as matching; matching is only as good as extraction. That dependency is the part most “price intelligence software” pitches gloss over.
Two practical observations. First, the layers don’t sequence in build order. You can’t postpone matching and “do intelligence later.” If the matching is wrong, your intelligence layer will be confidently wrong. Second, most off-the-shelf platforms deliver layers 1-3 reasonably and layers 4-5 thinly. A vendor dashboard of competitor prices is layer 3 with a visualization on top.
When you’re scoping, the unsexy bottleneck is almost always layers 1 and 2, not layer 4. Teams underestimate the data foundation, over-budget the analytics layer, and end up with a sophisticated model chewing on noisy data. The build-vs-buy decision in web data extraction is mostly a decision about how seriously you take the foundation.
A common pushback: “Can’t we use GTIN/UPC and skip matching?” On marketplaces, no. Sellers list products under different identifiers; identifiers get reused; brands use private UPCs. Identifier-only matching is a known failure mode.
Expert Insights
Mature programs typically blend at least two of three data sources: their own web data extraction, third-party data APIs, and merchant-supplied feeds. The 2026 industry framing of price intelligence as “the data layer behind every pricing tool” captures the same point the stack metaphor makes.
Quick Summary
“Which layer should I invest in first?” All five, sequentially, because each depends on the one below. The layer most teams underinvest in is layer 1 (extraction) and layer 2 (matching). Skip those and the intelligence layer becomes confident nonsense.
The Data Foundation, Where Most Price Intelligence Programs Actually Break
The data foundation is layers 1 and 2: data extraction and product matching. This is where price intelligence programs quietly fail, often months into a build, after the analytics dashboards are already approved.

Extraction is harder than it looks
Modern PDPs render prices in JavaScript, vary by locale and currency, mix list and promotional prices in the same DOM, expose different prices to different marketplace sellers, and change their HTML structure without notice. Anti-bot defenses block naive scrapers. Schema drift breaks selectors. The team that built a working scraper in January is rebuilding it in March.
Pulling clean, complete, current price data at scale is a continuous engineering discipline, not a one-time setup. This is the reality of ecommerce data scraping at production scale. Platform-specific patterns differ across surfaces; we cover them in Amazon, Walmart, and eBay data extraction.
Product matching at scale, the silent killer
The question is simple: is this competitor’s listing the same product as mine? The answer rarely is.
Titles vary (“Sony WH-1000XM5 Wireless Headphones, Black” vs “Sony XM5 Black Headphones”). Images vary across angles and seller-uploaded photos. GTIN and UPC are unreliable on marketplaces; sellers list bundles, regional variants, and white-label items under inconsistent identifiers. Robust matching combines titles, images, identifiers, and attributes, with a confidence score for each match.
Here’s the reasoning that catches teams off guard: if matching is 95% accurate, that sounds good, until you realize 5% of your competitive-price feed is comparing the wrong products. Every downstream decision drawn from those wrong matches is corrupted. The cost of a false match (you think Competitor X sells your hero SKU for $89; they’re actually selling a knockoff) is much higher than a missing match. Match confidence scoring matters more than headline accuracy.
Freshness, locale, and the validation discipline
Once you have extracted and matched, two more things must be true: the price must be current, and you must know it’s current. Freshness SLAs vary by category. Locale handling (currency, tax inclusion, region) is its own discipline; a price collected in EUR but presented in USD without conversion is silently wrong.
Validation catches all of this. Outlier filtering. Stale-cache detection. Cross-source reconciliation. E-commerce data-extraction vendors, Forage AI among them, treat validation as a first-class discipline rather than a post-hoc step, because the cost of a wrong-but-confident price reaching a dashboard is high.
Vendor claims of 99% accuracy or “1.2 billion SKUs covered” are industry context, not proof. Accuracy depends on your catalog and the matching discipline.
Expert Insights
Data trust is the 2026 challenge in pricing intelligence, not data volume. The clearest signal: the industry conversation has shifted from “can we collect more data” to “can we trust the data we collect.” In production ecommerce extraction, the most expensive failure isn’t a missed price, it’s a wrong match that propagates into a pricing decision.
Quick Summary
“Isn’t 95% matching accuracy good enough?” Not for pricing decisions. A 5% wrong-match rate corrupts every decision drawn from those matches. What you want is a confidence score per pair, and the discipline to act differently on high-confidence vs low-confidence matches.

The Intelligence Layer, Positioning, Elasticity, and Market Dynamics
Now we’re at the part most off-the-shelf platforms don’t actually deliver. The intelligence layer turns the clean, matched, validated price stream into three kinds of signal: positioning (where your prices sit), elasticity (how demand responds), and market dynamics (what the competitive system is doing).
The work is mostly analytical and sits atop the foundation. A sophisticated elasticity model on noisy matches produces sophisticated nonsense.
Competitive positioning
Where do your prices sit in the relevant competitive set? Above, at parity, below? On which SKUs? Positioning answers these and depends on a clearly defined competitive set, itself a matching problem in disguise.
Useful sub-concepts: price bands (high, mid, low ranges in a category), KVI (key value items, the SKUs customers use to judge whether a retailer is “cheap”), and basket positioning (the perceived price of a typical basket, often more strategic than individual SKUs).
Elasticity signals
Price elasticity measures how demand responds to changes in price. Estimating it requires two kinds of data: cross-sectional (at a given moment, how do sales vary across SKUs at different prices?) and time-series (within a given SKU, how does demand respond over time?). Most monitoring tools deliver one, rarely both.
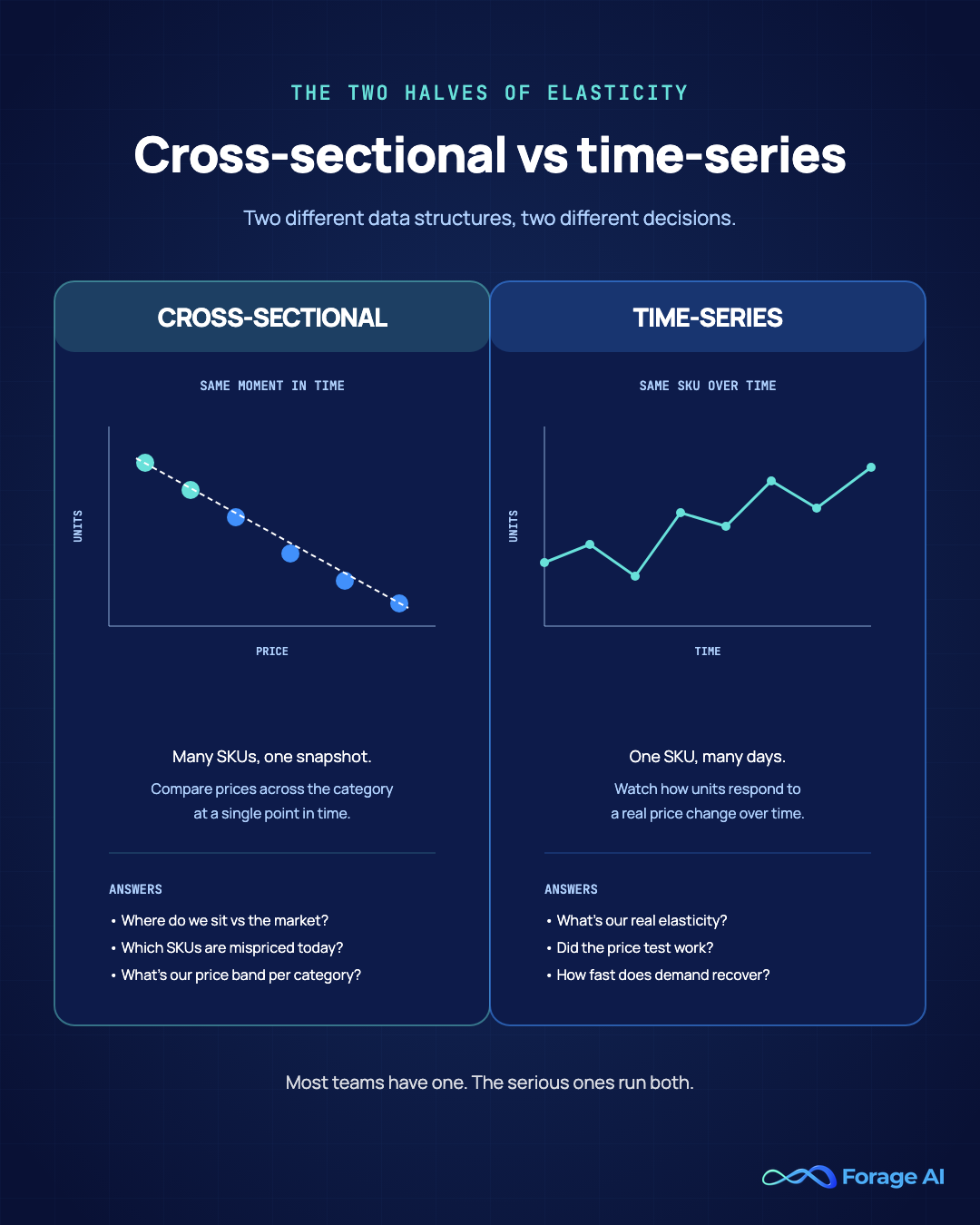
Reliable: commodity categories with enough volume and price variation. Unreliable: long-tail SKUs, new product launches (no history), structural breaks (regulatory shift, major competitor exit), and confounded variables (you raised price, demand fell, but a competitor also ran a promo).
A modern elasticity module is a multifactor algorithm that draws on transaction data, product prices, substitute prices, promotions, inventory, seasonality, and competitor volumes (McKinsey, 2024). The shorter framing: cost and willingness to pay are the two inputs necessary to calculate an optimal price (BCG, 2025).
Market dynamics
This layer asks: what is the competitive system doing? When competitors discount, are they running scheduled promos, clearing inventory, or shifting strategy? Promo timing patterns (a competitor always discounts on the first Tuesday). Inventory-driven price moves (price drops correlate with stock decreases). Seasonality decomposition. Machine learning earns its keep here, but only when the data foundation supports it.
BCG observed in 2025 that many CPG companies are investing in refreshing their understanding of shopper price elasticity as they look to take more nuanced price actions. The naive alternative, match the lowest competitor and undercut, is documented to destroy margin in marketplace dynamics.
Expert Insights
The most common gap between “we have price intelligence software” and “we have price intelligence” sits in the elasticity and market-dynamics work. Working with teams on intelligence layers, the pattern we see is this: the moment matching confidence is reliable, the elasticity and positioning models start producing decisions the pricing team actually trusts. The data foundation is the unlock, not the model.
Quick Summary
“What does the intelligence layer do that monitoring doesn’t?” Monitoring tells you what competitors are charging. The intelligence layer tells you where you sit, how customers respond, and what the competitive system is doing. It’s the difference between data and decision.
Use Cases, Dynamic Pricing, Repricing, MAP, Promotions, Assortment
Price intelligence feeds several downstream applications, and they often get confused with it.
Dynamic pricing is algorithmic price-setting in real time using multiple inputs. Price intelligence feeds the competitor side; demand and inventory come from your own systems.
Repricing is rules-based competitor following, common on marketplaces. “Match the Buy Box minus 1 cent, with a floor at cost plus 8%.”
MAP monitoring (Minimum Advertised Price) is brand-side: a brand checks that its resellers aren’t advertising below the floor it set.
Promotional intelligence asks when, what, and how often competitors discount. Assortment intelligence watches which SKUs competitors are pushing, new launches, expanded variants, and withdrawn products.

A useful way to think about which use cases are most data-foundation-hungry: dynamic pricing and repricing demand the cleanest, freshest data because they act in near-real-time. Positioning and promo timing tolerate slightly older data. MAP is largely a matching-plus-detection problem. For the operational mechanics of competitor following, our ecommerce price monitoring piece covers the patterns.
Common mistakes: running dynamic pricing on a weak foundation; conflating MAP enforcement (legal action) with MAP intelligence (data and reporting); assuming a rule-based repricer counts as a pricing strategy (it doesn’t).
Expert Insights
MAP enforcement requires real-time detection across all resellers, including long-tail marketplace sellers who often drive violations, a matching problem at scale. The use case most worth investing intelligence-layer rigor in, for ecommerce specifically, is promotional intelligence; the signal is rich and most teams capture less of it than they could.
Quick Summary
“Is repricing the same as price intelligence?” No. Repricing is a downstream action that consumes price intelligence. The intelligence is the analytical layer that decides whether following a competitor’s move is wise; the repricer is the mechanic that executes the decision.
Where Price Intelligence Misleads, Failure Modes to Plan For
Price intelligence done badly is worse than no price intelligence. It concentrates on wrong decisions instead of dispersing them. The failure modes are properties of the problem, not bugs in a tool.
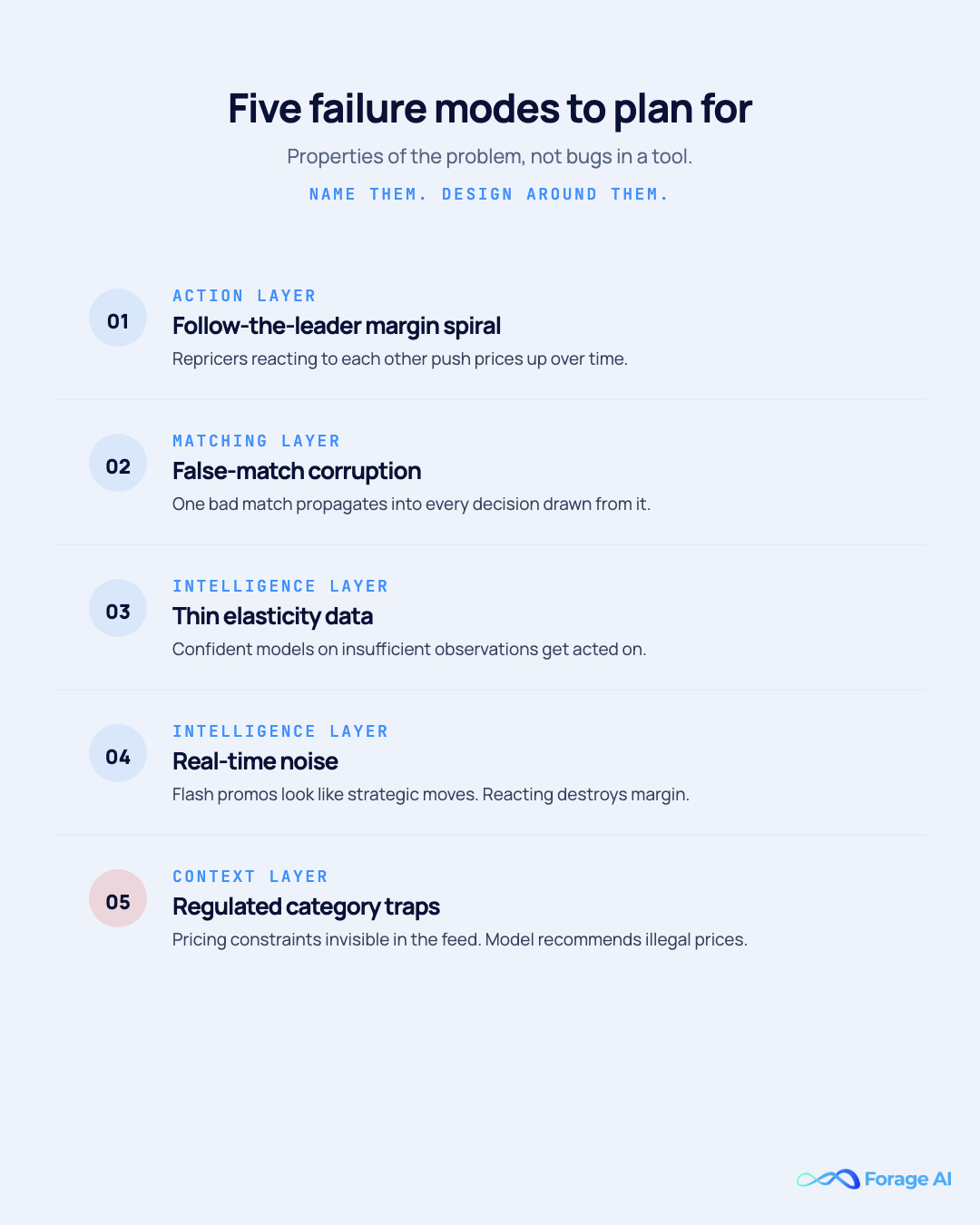
1. The follow-the-leader margin spiral. When every retailer’s repricer is set to “match the lowest competitor minus 1 cent,” the market converges downward or upward. A 2026 analysis reported that the largest marketplace’s repricing dynamics push average prices up by more than 11% over time as competitors react to each other (Washington Monthly, 2026). The foundational academic work on algorithmic pricing on the same marketplace (Le Chen et al., 2016) documented the dynamic earlier.
2. False-match corruption. One bad match propagates into every decision drawn from it. The model can be perfect; the input is wrong.
3. Thin elasticity data. Confident estimates on insufficient observations get acted on. Long-tail SKUs, new launches, and structural breaks all produce thin-data conditions.
4. Real-time noise. When the feed updates constantly, every flash promo looks strategic. Reacting causes price churn that erodes margins. Filtering signal vs noise is itself an intelligence-layer discipline.
5. Regulated category traps. Pharmaceuticals, alcohol, financial products, and other regulated categories face pricing constraints that are invisible in a price feed. A pricing model unaware of a state-level minimum-price law will recommend illegal prices. This article is for informational purposes only and is not legal advice. Consult qualified counsel for pricing-regulation guidance specific to your category.
Each failure mode connects to a specific layer of the stack. Margin spirals are an action-layer problem. False-match corruption is a matching-layer problem. Thin elasticity data is an intelligence-layer problem. Naming the layer tells you where to invest mitigation.
Expert Insights
2026 journalism on marketplace algorithmic pricing has put the follow-the-leader dynamic back in regulators’ field of view. The technical literature was a decade ahead; the recent attention is catching up. The failure modes above aren’t theoretical for teams that have run pricing programs, they show up in postmortems, and naming them upfront produces a team that designs around them.
Quick Summary
“What’s the biggest risk in running a price intelligence program?” False confidence. A confident model on bad matches, a fast feed reacting to noise, or an elasticity model on thin data all produce decisions that look principled but aren’t. The mitigation is mostly discipline.
Scoping a Price Intelligence Capability: What to Build, What to Buy
Given the five-layer stack, where should a team invest in internal engineering, and where should it rely on vendors? The honest answer is rarely “all built” or “all bought.”

The layer-by-layer logic:
- Layer 1, Extraction. High engineering cost. Continuous maintenance burden. Usually buy or hybrid. The “we’ll build it in-house” assumption almost always underestimates the maintenance tail.
- Layer 2, Matching. Hybrid is the sweet spot. Vendor matching plus your own validation thresholds.
- Layer 3, Monitoring. Mature SaaS category. Often buy.
- Layer 4, Intelligence. Mostly built, because this is where competitive differentiation lives.
- Layer 5, Action. Depends on the category. Marketplace repricing is buy; direct-to-consumer pricing systems are usually custom.
The strategic principle: buy the commodity layers, build the differentiated layers, and invest engineering rigor in the data foundation because everything above it depends on it. The “tried tooling, hit a wall” pattern usually maps to taking on too much foundation work in-house with too little engineering depth, or to buying a tool that handles layers 1-3 well and assuming 4-5 came in the box. This is the layer where specialized data-extraction vendors like Forage AI prove their worth: large-scale ecommerce price extraction, matching, monitoring, and validation as the foundation on which the rest of the stack depends. For a wider treatment, see our build vs buy guide.
Common scoping errors: building extraction in-house and discovering that selector maintenance is the real cost; buying “price intelligence software” and finding it’s monitored only via a dashboard; accepting vendor accuracy claims without validating against your specific catalog.
BCG’s executive question, long-term profit increasingly depends on whether leaders resist, accept, or accelerate AI-driven pricing trends (BCG, 2025), reframes through the stack lens: which layers do we own, buy, and build?
Expert Insights
Build-vs-buy in this space is rarely either/or. The healthiest programs use vendors for layers 1-3, build dedicated teams for layer 4, and select vertical-specific tools for layer 5; if you’re deciding who to lean on for those commodity layers, a roundup of ecommerce data providers by category is a useful starting point. The single most leveraged investment we see is making matching confidence scoring a first-class metric, once treated as a tracked SLA, downstream conversations get measurably better.
Quick Summary
“Should we build or buy our price intelligence stack?” Both, layer by layer. Buy the commodity layers, build the differentiated ones, and invest engineering rigor where you’ll feel the consequences hardest, which is almost always the data foundation.

What Comes Next as Price Intelligence Matures
A few directions worth watching. Continuous decisioning is the new default; periodic pricing reviews look slow. Observed-data coverage gaps are being filled with modeled or synthetic data. Cross-channel coherence (web, marketplace, and physical retail as one intelligence problem) is rising on enterprise agendas. MAP intelligence is shifting from enforcement-driven to insight-driven. And consent-bounded personalized pricing is on the horizon.
The implication for teams scoping today: the data foundation will be more strained, not less. Teams that assume the foundation work is “mostly done after launch” will be rebuilding it within a year.
Conclusion
Price intelligence is not the tool you buy. It is the capability you scope, and the data foundation determines whether the intelligence layer ever pays off.
Teams that treat it as a tool purchase end up where the persona at the top of this article started: tried tooling, hit a wall. Teams that treat it as a layered capability, buying the commodity layers, building the differentiated ones, and investing engineering rigor in the data foundation, give themselves the chance to make pricing intelligence actually deliver intelligence.
The decision isn’t whether you need this capability. In a market where the velocity floor is set by 2.5 million daily price changes on a single marketplace, you do. The decision is which layers you own, which you outsource, and where you invest the engineering rigor that makes the rest worth running.
Frequently Asked Questions
What is the difference between price monitoring and price intelligence?
Price monitoring is the mechanism of collecting and tracking competitor prices over time. Price intelligence is the analytical layer that turns those prices into competitive positioning, elasticity signals, and market-dynamics insights. Monitoring is the input; intelligence is what someone builds on top of it. Most tools that call themselves “price intelligence software” deliver monitoring with a dashboard, not intelligence in the analytical sense.
What data does a price intelligence platform collect?
At minimum: competitor prices, list vs. promotional price distinctions, stock signals, marketplace seller information, currency and locale, and MAP signals where relevant. Mature platforms also collect product attributes (titles, images, identifiers) for matching, change history for freshness analysis, and contextual signals like promotional cadence and assortment changes.
How accurate is competitor price tracking?
It depends on the matching layer. Vendors often quote 99% accuracy, but accuracy is conditional on the specific catalog, the competitive set, and the matching discipline. A 99% claim on a vendor’s reference catalog doesn’t transfer to your own. The number that matters more in production is the confidence score per matched pair.
Is price intelligence legal?
Generally yes, when data is collected from publicly accessible sources and respects website terms of service, robots.txt directives, and jurisdictional rules. The legal landscape is nuanced, especially around algorithmic pricing coordination and regulated categories. This article is for informational purposes only and is not legal advice; consult qualified counsel for guidance specific to your situation. See our piece on legal and ethical web scraping.
How often do prices change on Amazon and other major marketplaces?
Industry repricing benchmarks (2026) report roughly 2.5 million daily price changes on the largest marketplace, with the average product getting a new price about every 10 minutes. Velocity varies significantly by category; commodity electronics change fastest, while furniture and home goods change much more slowly.
What is MAP monitoring, and how is it different from price intelligence?
MAP (Minimum Advertised Price) monitoring is brand-side: a brand monitors its resellers to ensure they don’t advertise below the floor. Price intelligence is broader, covering competitive positioning, elasticity, and market dynamics across the full set. MAP monitoring is a focused application of the same matching-and-monitoring foundation.
Should we build or buy our price intelligence stack?
Both by layer. Extraction and monitoring are usually buy or hybrid. Matching is hybrid (vendor matching plus internal validation thresholds). Intelligence is usually built, because that’s where strategic differentiation lives. Action varies by category.
Sources
- Elevated Signal, 2026. Competitive Pricing Analysis 2026 Guide.
- McKinsey & Company, 2024. How retailers can drive profitable growth through dynamic pricing.
- BCG, 2025. Five Trends That Will Define the Future of Pricing.
- Washington Monthly, 2026. How Amazon’s AI Algorithms Raise the Prices You Pay.
- Le Chen et al., 2016. An Empirical Analysis of Algorithmic Pricing on Amazon Marketplace.
- Industry repricing benchmarks on the largest marketplace, 2026.
Related Articles
- Boost Profits with E-commerce Price Monitoring & Web Scraping, The operational sibling. How to actually build the price-monitoring layer.
- Best E-Commerce Web Scraping vs AI Extraction – 2025 Guide, For readers comparing extraction approaches.
- How AI-Powered Extraction Unlocks Amazon, Walmart, eBay Data, Platform-specific patterns for the major marketplaces.
- Build or Buy? A Strategic Guide to Web Data Extraction, Wired framing of the build/buy question.
Sai is a data infrastructure enthusiast who has spent the past two to three years following the AI space closely, from the infrastructure layer to the fast-growing world of data for AI. He is genuinely curious about how modern data pipelines get built and where the data industry is heading, and he writes insightful pieces on the core topics that shape this niche.




