

Author: Punith Yadav, with expert insights from Pihu Srivastava
Part I: You Made the Right Bet
Let’s get this out of the way first.
If you’re adding Retrieval-Augmented Generation to your data extraction pipeline, you’re on the right track. RAG is essential for any organization that wants to pull structured data from complex documents with AI.
Even the best Large Language Models have three major limitations that make them unreliable for enterprise data extraction on their own. They don’t know your domain. They don’t understand what “asset allocation” means in your documents, or what a specific regulatory term means on page 247 of a filing. Their knowledge stops at their training cutoff, so they can’t reference the document in front of them unless you provide it. When they have to answer without proper context, especially with large, messy, unstructured inputs, they tend to hallucinate with confidence.
RAG addresses this by adding external, domain-specific knowledge to the model during inference. Instead of making the LLM guess, you give it the exact context it needs: “Here’s the document. Here are the definitions. Here’s what these terms mean in this specific context. Now extract.”
The market agrees. RAG is projected to reach $11 billion by 2030, a 49% compound annual growth rate. Document retrieval is leading, making up a third of global revenue. More than 80% of enterprise data is unstructured, and the need to make it usable is accelerating.
You read the landscape correctly. RAG is the right choice.
The question is, why isn’t it working?
QUICK DIGEST
- RAG is the right architecture, but most production pipelines stall at 60-75% accuracy
- The bottleneck is almost never the model or retrieval; it’s the ingestion layer
- Three patterns kill production RAG: generic keywords, mis-chunking, missing navigation logic
- A data-first inversion ships pipelines past 95% accuracy on the same commodity models
- Debug bottom-up: data, retrieval, augmentation, generation, in that order
Part II: The Pipeline That Should Work But Doesn’t
Here’s the version of this story we’ve lived firsthand.
We built a data extraction pipeline using all recommended components: a production-grade vector database, several tested chunking strategies, embedding pipelines with cross-encoder re-ranking, and hybrid retrieval combining semantic search with keyword matching. By every benchmark, the architecture was solid.
But accuracy stayed at 65% for weeks.
We did what anyone would do: optimized retrieval, improved embeddings, adjusted re-ranking thresholds, and tried different chunk sizes and overlap ratios. Each change made a small difference, but nothing made a real breakthrough.
If you’re at this stage, with a solid architecture, good implementation, and accuracy stuck between 60 and 75%, you’re not alone, and you’re not making a mistake. This is the most common production failure in RAG, and it isn’t caused by the layers you’re optimizing.
The real problem starts earlier, at the ingestion stage, the moment data enters the pipeline.
What makes ingestion failures more dangerous than retrieval failures is that they’re invisible. When retrieval fails, you get empty results and a clear, traceable error. You know something broke and where to look for it.
When ingestion fails, the LLM still returns an answer. It looks plausible and sounds confident, but it’s wrong. Nothing in the pipeline flags this, because from the system’s perspective, everything worked: chunks were retrieved, the prompt was assembled, and the model generated a response. The failure actually happened earlier, in how the data was structured when it first entered the system.
Three specific patterns cause these issues. They often build on each other and show up in every stalled pipeline we’ve seen.
Worth knowing:
- Solid architecture plus stalled accuracy almost always points to ingestion, not retrieval
- Ingestion failures are invisible: the LLM still answers confidently with retrieved context
- Three ingestion patterns – keyword specificity, chunking, navigation – drive most plateaus
Part III: Three Patterns That Kill Production RAG
The keyword problem
This is the most common failure, and it’s almost completely hidden from engineering teams.
Take a keyword like “asset allocation.” Domain-specific. Clear extraction intent. The kind of term that should produce clean, confident retrieval.
In a 300-page financial PDF, the term shows up 47 times. Some are formal definitions, some are table headers, and others are just passing mentions buried in unrelated paragraphs. The system retrieves all 47 matches because they all have the keyword. The LLM then gets a payload that’s about 80% irrelevant context and only 20% real knowledge.
With that ratio, hallucination isn’t just a risk; it’s almost guaranteed.
The keyword itself wasn’t wrong. It was just too common in the document to create a clear link between the query and the right data point. The system couldn’t separate signal from noise because, at the keyword level, there was no real difference.
This is the key point: a RAG pipeline is only as strong as the relationships between its data points. When those relationships are strong, when a keyword points to one or two clear locations with good context, the LLM extracts information confidently. When keywords are generic and match everywhere, accuracy reaches a ceiling, regardless of the model, database, or retrieval setup.
The standard approach defines keywords, splits the document into chunks, embeds, and retrieves. It never stops asking if the keywords are specific enough to create meaningful relationships. That question isn’t in any RAG tutorial, but it should be the first step.
The chunking trap
Even with specific keywords, how you break the document determines whether meaning survives into the vector database.
The usual logic is to split the document to fit the model’s context window, say, 128K tokens for a 200K-token document. This optimizes for the model’s limits, but ignores the document’s own structure.
| Strategy | How it works | Where it fails |
|---|---|---|
| Character split | Fixed character count | Cuts sentences mid-thought, meaning destroyed at boundaries |
| Sentence split | Sentence boundaries | Duplicates data across chunks, conflicting retrieval |
| Recursive split | Follows document headers and sections | Best general approach, but fails on cross-section dependencies |
Recursive splitting is usually the best default. It follows the document’s structure, headers, sub-headers, and sections, and creates coherent chunks. For simple documents, this works well.
But it fails when important meaning is spread across different sections.
In one project, we worked with Markdown files that ranged from 100K to 200K tokens. Recursive splitting followed the headers closely, but accuracy remained low. That’s because a definition in Section 2 changed a value in Section 7, which depended on a clause in Appendix B. The data was correctly chunked according to every standard metric, but the real logic, the relationship between the three sections spread over dozens of pages, was lost.
Chunking should be a document-specific engineering decision, not just a way to fit the model. Most chunking tutorials focus on fitting the model but rarely address tailoring to the document.
Even if chunking is done well, there’s still a third pattern to watch for.
The navigation gap
This is the failure that keeps teams stuck in proof-of-concept (POC) rather than moving to production. Here, the limits of basic RAG become structural problems rather than just tuning issues.
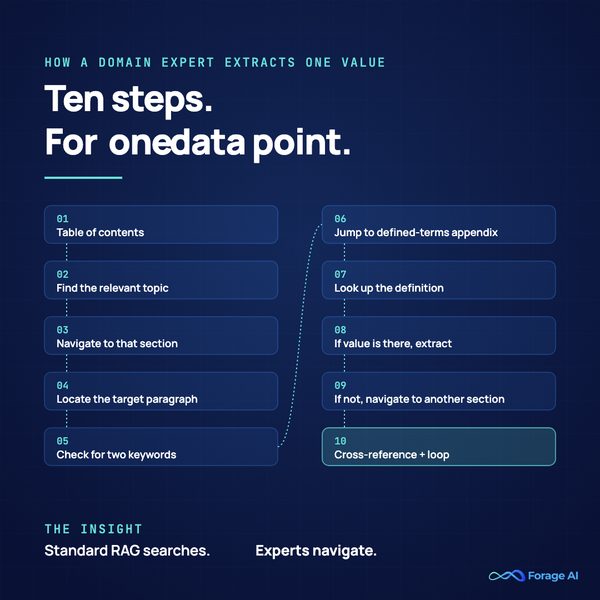
Open a 300-page financial PDF. Extract a single data point the way a domain expert does. Watch their process:
- Go to the Table of Contents
- Find the relevant topic
- Navigate to that section
- Locate the target paragraph
- Check for two specific keywords
- If present, jump to the Defined Terms appendix
- Look up the definition
- If the value is there, extract it
- If not, navigate to another section
- Cross-reference and repeat
Ten steps. Conditional logic. Cross-references between sections fifty pages apart. For one data point.
Standard RAG, chunk, embed, and retrieve can’t represent any of this. It doesn’t know that Section 2 depends on Appendix B. It doesn’t know that the Table of Contents entry maps to one specific paragraph, not the 46 other instances of the same term. It treats the document as a flat collection of searchable text.
But complex documents aren’t just flat text. They’re structured systems with navigation paths, hierarchies, and conditional logic. A 300-page financial PDF isn’t just a wall of text; it’s more like a directed graph, and basic RAG doesn’t understand graphs.
This is where methods like Graph RAG become essential. By treating data points as nodes and their relationships as edges, Graph RAG can navigate between sections, jumping from a value in Section 7 to a definition in the appendix to a condition in Section 12 with structural accuracy rather than just guessing based on semantics.
But even Graph RAG only works if those relationships are mapped during ingestion. Without that foundation, every RAG approach runs into the same problem.
The real challenge in data extraction from complex documents isn’t search, it’s navigation. Standard pipelines are built for search, and that mismatch causes more stalled projects than any model limitation.
EXPERT INSIGHT
The real challenge in extracting data from complex documents isn’t search – it’s navigation. Standard pipelines are built for search, and that mismatch is responsible for more stalled projects than any model limitation we’ve encountered. Until ingestion learns to navigate, no amount of retrieval tuning will move the ceiling.
Worth knowing:
- Generic keywords that match dozens of locations cap accuracy regardless of model or retrieval
- Chunking should follow document logic, not model token limits
- Complex documents are directed graphs of cross-references; standard RAG treats them as flat text
- Graph RAG and structural metadata only work if relationships are mapped during ingestion
Part IV: Why Good Teams Hit This Wall
The pattern behind every stalled pipeline we’ve diagnosed follows the same sequence:
Step 1: Start with the model. Pick an LLM, build a RAG pipeline, run initial tests. Accuracy comes back low.
Step 2: Optimize retrieval. Better embeddings. Hybrid search. Cross-encoder re-ranking. Each adjustment produces a small gain. Encouraging, but not enough.
Step 3: Add more data. Bigger chunks, more documents, wider context window. Accuracy drops because noise scales faster than the signal. More data in a structurally flawed pipeline doesn’t improve results. It buries the signal deeper.
Step 4: Hit a wall. The pipeline plateaus, months pass, sometimes years, and optimizing retrieval produces diminishing returns. The team starts questioning whether the model is the bottleneck, or whether the documents are just “too complex” for AI extraction.
This isn’t a talent issue. The teams we’ve seen in this situation are often excellent, experienced data scientists, strong engineers, and a real investment in infrastructure. The real problem is the sequence they follow.
The model-first approach is what the industry teaches. Every tutorial, every documentation page, every “getting started with RAG” guide walks through the same steps: pick a model, set up a vector database, chunk your documents, embed, retrieve, generate. When it doesn’t work, optimize retrieval.
This sequence works for simple extraction, basic documents, short text, and direct keyword-to-value mapping. But it fails with complex documents because it never asks the key question: Is the data entering the pipeline structured to allow accurate extraction? Separate true technology limitations from approach limitations.
The technology limits are real but specific: LLMs have fixed context windows, basic RAGs can’t handle multi-hop navigation, and vector databases can store duplicate data, leading to conflicting retrievals. These are hard constraints.
But most production failures aren’t due to technology; they’re caused by the approach. Examples include chunking documents just to fit token limits rather than preserving meaning, using generic keywords without checking their specificity, treating structured documents as flat text, and never looking at how a human expert performs extraction. These are choices, not constraints, and the standard playbook doesn’t address them.
This distinction matters because it means the problem can be solved, not by better models or retrieval, but by better data engineering at the ingestion stage.
Worth knowing:
- The standard model-first sequence works for simple extraction and fails on complex documents
- Adding more data to a structurally flawed pipeline buries the signal, it doesn’t recover it
- Most production failures are approach limitations, not technology limitations
- The fix is upstream data engineering, not better models or retrieval tuning
Part V: The Inversion, Data-First, Not Model-First

The teams that consistently achieve production-grade accuracy do something different from the model-first sequence. They start with the document, not the model. Before any pipeline code is written or a single embedding is generated, the document is studied as a structured system. The methodology that emerges follows a different logic from the standard playbook.
Understand navigation before processing text. Complex documents have internal logic that lives below the surface: section markers, heading conventions, cross-reference patterns, and conditional dependencies. These aren’t formatting choices; they’re how the document organizes meaning. Before deciding how to chunk or what to embed, that logic needs to be mapped. Most stalled pipelines never perform this step. They treat the PDF as a wall of searchable text and wonder why search-shaped solutions keep failing on navigation-shaped problems. The first hour of any serious extraction project should be spent reading the document the way an SME reads it, not the way a parser does.
Map relationships before creating embeddings. The relationships between data points, one-to-one mappings, one-to-many dependencies, and conditional chains across sections need to be made explicit at the metadata layer before any vector is generated. This is what gives a RAG system its relationship strength. Without it, the system is searching. With it, the system is navigating. The vector database stops being a noisy lookup and becomes a structured index. In our experience, this is the single biggest determinant of whether accuracy plateaus at 65% or scales past 95%, because it changes what the retrieval layer is actually doing.
Make navigation deterministic, not probabilistic. If a domain expert always follows the same path, table of contents to section to definition to conditional clause, that path should be codified, not left for an agent to rediscover on every query. Deterministic paths eliminate hallucination on the navigation layer entirely. The AI doesn’t guess the route. The route is engineered. The model only handles the part it’s actually good at: extracting a specific value from a specific location once it has been guided there. Every navigation decision left to probabilistic inference is a place where accuracy can leak.
Build fallback logic for the edges. Documents are inconsistent. Patterns break. Page numbering shifts. A defined-terms section gets renamed. A footnote convention changes between filings. Edge cases need explicit exception handling, not silent failures that poison downstream accuracy without anyone noticing. The teams that ship are obsessive about cataloging where the standard pattern doesn’t hold and writing logic for each case. The teams that stall let the edges fail quietly and watch their accuracy ceiling drop without ever knowing where the leak is.
Combine approaches; never rely on one. Production-grade extraction rarely uses a single technique. Different parts of the same document might need standard RAG for simple keyword mapping, Graph RAG for cross-section dependencies, deterministic logic for known navigation patterns, and agentic reasoning for dynamic structures. The combination is what makes production accuracy possible. Single-approach pipelines hit a ceiling because no single approach handles every variant a real document throws at them, and choosing one technique up front is itself a model-first decision in disguise.
The result of this approach is that the vector database receives clean, structured, relationship-aware data instead of raw text. Retrieval works better almost automatically because it’s operating on data designed for accurate retrieval. The model becomes what it should be: a commodity layer that processes well-structured inputs. Not the hero, not the thing you optimize when accuracy stalls, just the final step in a pipeline where the hard work has already happened upstream.
This is the shift, model-first to data-first. And it’s the difference between pipelines that demo well and pipelines that ship.
EXPERT INSIGHT
In our experience, mapping relationships at the metadata layer before any vector is generated is the single biggest determinant of whether accuracy plateaus at 65% or scales past 95%. It changes what the retrieval layer is actually doing – from noisy lookup to structured navigation. Everything downstream gets easier once this one decision is made correctly upstream.
Worth knowing:
- Start with the document, not the model; understand navigation before processing text
- Map relationships at the metadata layer before any vector is generated
- Codify deterministic navigation paths so the model only handles value extraction
- Combine RAG, Graph RAG, deterministic logic, and agentic reasoning – never rely on one
Part VI: What the Shift Looks Like in Practice
One financial services organization had spent years building an internal extraction pipeline for 200-page regulatory documents.
Their team was strong, experienced data scientists with significant budget and great tools. They followed the standard approach: built an RAG pipeline that relied on undifferentiated automated data collection of entire documents into the vector store, and queried with an LLM. When accuracy was low, they optimized retrieval. Better embeddings, re-ranking, and marginal improvements. The pipeline never reached production.
The root cause wasn’t the model or the retrieval setup. It was the ingestion layer. Documents were processed as flat text, with no structural decomposition, no metadata mapping relationships between sections, and no codified navigation paths. The pipeline didn’t know that extracting a single data point required going through a table of contents, three body sections, a definitions appendix, and a conditional clause. It was searching when it should have been navigating.
A data-first approach used the same documents, the same data, and the same extraction requirements, starting with the document’s structure. We studied how domain experts manually performed the extraction, mapped the navigation logic, built structural metadata to represent relationships between sections, codified deterministic paths, and added explicit fallback handling for edge cases.
Same documents, same data. Years of stalled internal work turned into production in just a few months.
The model was the same kind of commodity it always was. The only thing that changed was the data preparation, and it was the only variable that mattered.

Worth knowing:
- Years of stalled internal work can compress to months once the ingestion layer is restructured
- Same documents, same model – only the data preparation changed
- Searching is the wrong primitive for documents that need to be navigated
Part VII: The Economics Nobody Talks About
There’s a cost reality that shapes every RAG project, and it’s worth addressing directly because it compounds the data quality argument.
RAG infrastructure is basically free to run. Vector databases, chunking pipelines, and embedding generation have no meaningful cost. The real cost comes from LLM API calls, and enterprise teams are very sensitive about LLM spending. Every organization pushes back on it.
In practice, this means teams often get stuck with cheaper, lower-performing models. A model that delivers 98% accuracy on some extraction tasks might be blocked for budget or compliance reasons. The approved model delivers much less, but the team is told to make it work anyway.
At that point, you can’t control model quality anymore. Data quality becomes your only lever. This is where the data-first approach really shines: it delivers the highest accuracy from whatever model you’re allowed to use. Clean, structured, relationship-aware data gets more out of a limited model than noisy, unstructured data does from the best model available.
There’s also another optimization that becomes possible once the data foundation is solid: automated prompt optimization. Reinforcement learning agents can take your prompt, test it against a ground-truth evaluation dataset, pinpoint exactly where and why it fails, and auto-generate an improved version, iterating over 5 or 6 rounds with a budget cap of $10 to $20 per run. This squeezes more performance out of cheaper models than manual prompt engineering can, because the agent systematically tests against ground truth instead of relying on intuition.
But, and this is critical, prompt optimization only works when the data feeding the pipeline is clean. Optimizing prompts on top of noisy, poorly structured data is polishing a pipeline that’s broken at the foundation. The data has to be right first, then the optimizations compound.
Caching matters too. Repeated queries and in production, many queries are repeated; they should never hit the LLM twice. Caching common extraction patterns skips the model entirely, cutting both cost and latency.
EXPERT INSIGHT
Once budget constraints take model quality off the table, data quality is the only lever you have left. Clean, relationship-aware data gets more out of a cheaper model than the best model available gets out of noisy inputs. That’s why we treat ingestion as the place where the win is engineered.
Worth knowing:
- RAG infrastructure is effectively free; LLM API calls are the cost driver
- Budget constraints often force cheaper models; clean data becomes the only remaining lever
- Automated prompt optimization compounds the gains, but only on top of clean ingestion
- Caching repeated queries cuts both cost and latency without touching the model
Part VIII: How to Actually Diagnose a Failing Pipeline
When output is wrong, the instinct is to blame the model. In our experience, the model is almost never the root cause. Here are the four layers, listed from the output back to the source. Debug from the bottom up.

Layer 1: Generation. Ask the LLM why it picked the value it did. Confidence scoring and reasoning traces show whether the model was confused by unclear input or just made a bad call with clear input. If the reasoning is solid but the answer is wrong, the problem is upstream.
Layer 2: Augmentation. Check the actual prompt the RAG system sent to the model, not the prompt you think it sent, but the literal text that arrived at the LLM. If the prompt has irrelevant chunks, duplicated context, or missing relationships, the augmentation layer is building a bad input from potentially good retrieval.
Layer 3: Retrieval. Are the right chunks being surfaced? Evaluation frameworks like RAGAS measure retrieval precision and relevance. If the wrong chunks are coming back, the retrieval layer needs tuning. But before tuning, check that the chunks themselves are clean, because if they were noisy at ingestion, no retrieval optimization will yield clean results from dirty data.
Layer 4: Data. Is the source data clean, specific, and well-structured? Do keywords map to precise locations or to dozens? Do relationship maps exist between dependent sections? Is the metadata layer comprehensive? This is where a data quality framework for external sources pays off, giving you the dimensions to check before ingestion, and it’s exactly where the best data observability tools for external data pipelines earn their place, flagging stale or broken feeds before they poison retrieval.
Most failures, the significant majority, trace back to Layer 4. The data itself. Not the model, not the retrieval, not the augmentation. The data that entered the pipeline before any of those layers ran.
Debugging bottom-up, starting at the data layer, saves weeks of misdirected optimization.
Worth knowing:
- Debug bottom-up: Generation, Augmentation, Retrieval, Data
- Check the literal prompt the model received, not the one you think you sent
- Retrieval tuning on noisy chunks will not produce clean results
- The majority of production failures trace back to Layer 4 – the data itself
Part IX: The Moat That Actually Matters
AI models are becoming commodities fast. Inference costs are dropping, and open-source alternatives are closing the gap with proprietary models. Retrieval architecture is converging; vector databases, re-ranking strategies, and hybrid search patterns are becoming standard. The model and retrieval layers are turning into commodity infrastructure.
What isn’t converging: the ability to take a 200+ page document with multi-section dependencies, conditional navigation paths, and complex cross-references and turn it into clean, relationship-aware, retrieval-ready data. That requires understanding document structure, mapping navigation logic, and building metadata that represents how information actually connects across sections. Handling edge cases that don’t follow the pattern.
This is hard, specific work. It doesn’t scale through better hardware or bigger models. It scales through accumulated expertise, every project adding new patterns, new edge cases, new structural variants to the methodology.
The teams succeeding with production-grade RAG aren’t winning because of model selection. They’re winning because of what happens to data before it reaches the model: structural metadata, relationship mapping, deterministic navigation, the unglamorous, foundational work that the standard playbook skips entirely.
The model is a commodity; the data preparation is the moat.
Worth knowing:
- Models and retrieval architectures are converging into commodity infrastructure
- Document-structure mapping and relationship-aware metadata don’t commoditize
- The moat is accumulated structural expertise, not model selection
This article is based on production experience across financial document extraction, web data extraction, and large-scale PDF processing. Accuracy figures and failure patterns are drawn from active projects.
Forage AI builds the data layer that RAG pipelines depend on, structured, clean, and retrieval-ready. If your team is hitting one of these patterns, our managed extraction services can help diagnose where the ingestion layer is breaking before you spend another quarter optimizing retrieval.
Frequently Asked Questions
Does RAG eliminate hallucinations in data extraction?
It dramatically reduces them by grounding the model in external knowledge. But if the ingestion layer feeds noisy or duplicated data, the LLM will still hallucinate and it does so with retrieved context backing it up, which makes the error harder to catch than a bare-LLM hallucination.
When should you use RAG vs. fine-tuning in data extraction?
Fine-tuning changes how the model behaves, its tone, its format, its style of output. RAG changes the model’s knowledge at inference time. If your data is proprietary, changes frequently, or needs to stay off the model’s training servers, RAG is the better architecture. Most production systems end up using both, and they solve different problems.
Which types of documents are hardest to extract for RAG?
Long, structurally complex documents with cross-section dependencies, like financial filings, regulatory PDFs, and legal contracts. The difficulty isn’t the text itself; it’s the navigation logic. When extracting a single value requires following conditional paths across a table of contents, multiple body sections, a definitions appendix, and a conditional clause, basic RAG can’t resolve those dependencies without structural metadata.
Why does adding more data sometimes make accuracy worse?
Noise scales faster than signal. If additional data isn’t well-structured or contains generic keyword matches across dozens of locations, it increases the LLM’s exposure to irrelevant context. Past the 80/20 noise-to-knowledge threshold, hallucination becomes near-certain, and more data actively degrades output.
Is RAG infrastructure expensive to run for data extraction?
The infrastructure, vector databases, chunking pipelines, and embedding generation are effectively free. The cost driver is LLM API calls. Production teams manage spend by caching repeated queries, optimize prompts to extract greater accuracy from cheaper models, and ensure clean data to reduce the number of reprocessing cycles needed.
How do you know if your failure is at the data layer vs. the model layer?
Debug bottom-up. Check the model’s reasoning first (was it confused or confident?). Then check what prompt it actually received. Then check what chunks were retrieved. Then check the source data itself. If the model’s reasoning is sound given the context it received, but the context was wrong, the failure is at ingestion. In our experience, this is where the majority of production failures originate.




