

Every data team we have worked with eventually hits the same wall. The scrapers were never the hard part. Keeping a fleet of them alive is. A site redesign quietly breaks three selectors on Monday, a fresh anti-bot wall goes up on Wednesday, and by Friday a feed has been returning half-empty records that nobody caught because the job still exited zero. The work shifts from building extraction to babysitting it, and the team’s best engineers spend their week patching selectors instead of shipping product.
Managed web data extraction is the answer many teams reach for once that maintenance load stops being occasional and starts being the job. This guide covers what it actually is, how a managed pipeline works in practice, why in-house extraction buckles at scale and when it makes sense to hand it off, the providers worth knowing in 2026, how to evaluate them, and which one fits your situation. By the end you should be able to judge whether outsourcing extraction is the right call for your team and shortlist a partner with confidence. One number to frame the stakes up front: automated traffic crossed 51% of all web traffic in 2024, which means the environment your in-house scrapers run in is now majority machine and hostile by default.
Quick Digest
- What it is: Managed web data extraction is a fully outsourced service where a provider owns the entire extraction lifecycle (discovery, crawling, parsing, QA, enrichment, and delivery) plus ongoing maintenance, and hands you clean structured feeds instead of infrastructure.
- It is not just scraping: The “managed” part is the cleaning, normalizing, validating, maintaining, and compliance layer, not a one-off grab with someone else’s script.
- How it works: A continuous, monitored pipeline delivers schema-validated records in your chosen format and cadence, with breakage detected and fixed before it reaches you; first feeds typically land in two to four weeks.
- Why in-house breaks: Building scrapers is cheap, maintaining them is not. Site changes silently break selectors, anti-bot defenses escalate, and bots are now 51% of web traffic, so upkeep consumes the team.
- When to hand it off: When source count and change frequency outpace your team, SLAs slip, and the data is load-bearing enough that errors cost more than the scraping.
- Top providers (2026): Forage AI, PromptCloud, Grepsr, Datahut, and ScrapeHero lead on done-for-you delivery; Zyte and ProWebScraper are hybrids; Bright Data, Oxylabs, Apify, and Diffbot are powerful but tool/proxy/API-first.
- How to evaluate: Score coverage, a stated QA methodology with an accuracy SLA, compliance posture, customization depth, governance (no reselling, data ownership, on-prem), delivery SLAs, and support.
- Which to pick: Start from your decision signals, not the brand: a fully-managed partner for a true hand-off, a feed-led provider for commodity data, a tool/proxy/API only if you have engineers to keep operating it.

What Managed Web Data Extraction Actually Means
Managed web data extraction is a service model, not a tool. A provider takes ownership of the full pipeline, from finding the right sources through to delivering clean, structured, validated data into your systems, and keeps that pipeline running as the web changes underneath it. You receive feeds, not infrastructure. The distinction that matters here is between three terms people use interchangeably and shouldn’t. Web scraping is the raw act of pulling content off a page. Data extraction is the larger job of turning that raw content into clean, normalized, schema-conformant records. A managed service is when someone else owns that entire job end to end, including the parts that never show up in a tutorial: monitoring, maintenance, QA, and compliance. If you want the underlying mechanics, our guide to web data extraction techniques covers the methods layer.
There are only three ways to operate. You build and run it in-house. You buy a self-serve tool or API and operate that yourself. Or you hand the whole thing to a managed provider. The difference is not capability, it is who carries the operational weight.
Managed extraction is not just web scraping with someone else’s script. The script is the cheap part. What you are actually paying for is the cleaning, normalizing, validating, maintaining, and compliance layer that sits around it, which is the part that breaks and the part that takes a team to keep alive.
This is also the services side of a market that is growing faster than the tooling side. The web scraping market sits at roughly USD 1.03 billion in 2025, and the services segment is growing at a 14.74% CAGR, ahead of software, per Mordor Intelligence. Managed is where the demand is moving, and it is closely related to the broader data-as-a-service model.
| Operating model | Who builds it | Who maintains it | Who owns QA | What you receive |
|---|---|---|---|---|
| In-house DIY | Your engineers | Your engineers, continuously | Your team | Infrastructure you run |
| Self-serve tool / API | Vendor builds the tool, you build the logic | You | You | A tool you operate |
| Managed service | Provider | Provider | Provider | Clean structured feeds |
Quick Summary
Q: What is managed web data extraction?
A: It is a managed service where a provider owns the entire extraction lifecycle (discovery, crawling, parsing, QA, delivery, and ongoing maintenance) and hands you clean structured data, unlike a tool or API you still operate yourself. The value is the transfer of operational ownership, not a better scraper.
How a Managed Extraction Pipeline Actually Works
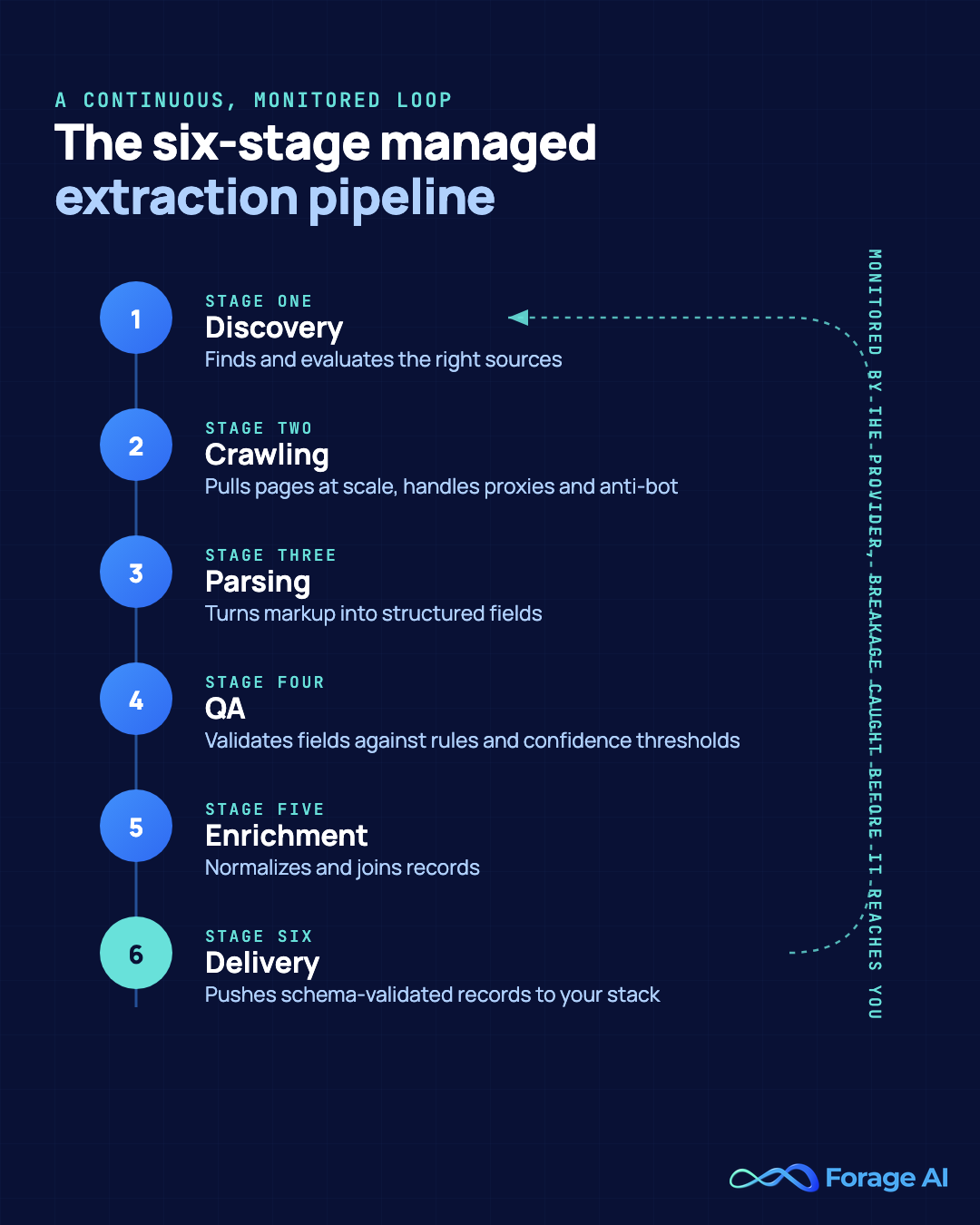
A managed pipeline is a continuous, monitored loop, not a one-time build. Across managed engagements the shape is consistent: six stages, running on a schedule, watched by the provider. Discovery finds and evaluates the right sources. Crawling pulls the pages at scale, handling proxies and anti-bot. Parsing turns markup into fields. QA validates those fields against rules and confidence thresholds. Enrichment normalizes and joins. Delivery pushes schema-validated records to wherever you consume them. This is the same arc we describe in our piece on data extraction automation moving from fragile scripts to managed pipelines.
The engagement itself runs on a predictable arc. Onboarding and discovery, then schema sign-off where you agree the exact shape of the records, then the build, then validation, then your first feed. Expect two to four weeks from kickoff to a first validated feed for a typical program, longer for large or heavily defended source sets.
What you actually consume is the operational artifact: a stable, schema-validated record in the format and cadence you asked for, whether that is JSON, CSV, an API endpoint, or a drop to cloud storage. The provider owns the monitoring, which means breakage gets caught and fixed upstream of you. The good ones lean on human-in-the-loop QA for the records automation flags as low-confidence. In adjacent document-processing pipelines, combined automated-plus-human QA typically reaches 60 to 70% straight-through processing in 2026 industry benchmarks, with the strongest deployments above 95%, meaning most records need no human touch while the uncertain ones get routed for review.
Here is the contract that matters to you as the consumer: a single validated record, with its QA metadata attached.
{
"source_url": "https://example.com/product/123",
"extracted_at": "2026-06-29T08:15:00Z",
"fields": { "product_name": "Acme Widget", "price": 19.99, "currency": "USD", "in_stock": true },
"qa": { "confidence": 0.98, "validation_method": "automated+human", "review_status": "passed" }
}
Quick Summary
Q: How does a managed web data extraction pipeline work?
A: A provider runs a continuous, monitored pipeline (discovery, crawling, parsing, QA, enrichment, delivery) and hands you schema-validated records in your chosen format, catching and fixing breakage before it reaches you. First feeds usually arrive in two to four weeks, and what you consume is a stable validated record with QA metadata attached.
Why In-House Extraction Breaks, and When to Hand It Off
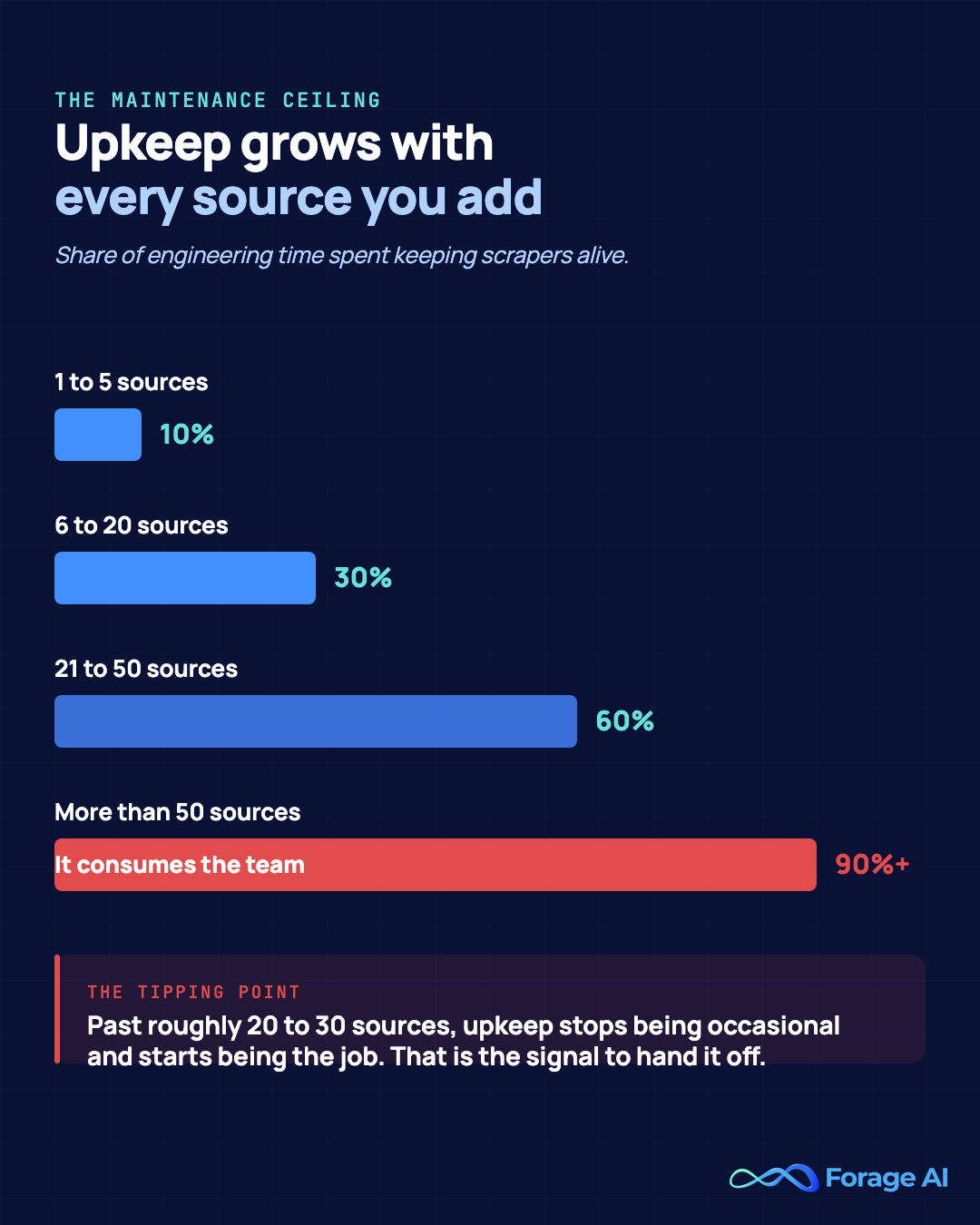
In-house extraction does not fail at the build. It fails at the upkeep. Standing up a scraper for one site is an afternoon. Keeping fifty of them returning correct data through redesigns, anti-bot changes, and seasonal layout shifts is a standing commitment that competes directly with the work your team was hired to do.
The operating environment has turned actively hostile, and that is the part teams underestimate. Site redesigns silently break selectors, so the job keeps running and quietly collects the wrong values. Anti-bot systems now fingerprint at the network and TLS layer, not just the user agent, and behavioral models score every session. Bad bots reached 37% of all internet traffic in 2024, up from 32%, with 44% of advanced bot traffic aimed at APIs, per the Imperva 2025 Bad Bot Report. The blocking has also moved to the infrastructure layer. On July 1, 2025, Cloudflare began blocking AI crawlers by default for new domains, and Cloudflare sits in front of roughly 20% of the web. Access went from opt-out to opt-in across a fifth of the internet in a single change.
Then there is where the time actually goes. A 2025 survey of data decision-makers found 64% of organizations had data teams spending more than half their time on repetitive or manual work. That is the maintenance tax, and it is exactly the load a managed partner absorbs. At our own scale, 500M+ websites crawled and multi-method extraction (XPath, NLP, and custom ML models running in parallel) is what lets a pipeline survive the site changes that would break a single hardcoded selector.
The dangerous failure is the silent one. A scraper that throws an error gets noticed. A scraper that returns 200 and a structurally valid but stale or partial record does not, and your dashboard stays green while downstream decisions inherit the bad data. Silent failures cause more data-quality incidents than hard crashes.
So when is it worth handing off? The signals are operational, not just financial. Hand it off when source count climbs past roughly 20 to 30 and change frequency is high, when 25 to 50% of engineering time is going to upkeep, when anti-bot escalation is outpacing your team, when freshness or coverage SLAs keep slipping, or when the data feeds a revenue- or model-bearing process where errors are expensive. The honest way to weigh it is against the cost of bad data, not the line-item cost of scraping. A widely-cited Gartner benchmark puts poor data quality at an average of USD 12.9 million per year per organization (2020 figure, still the reference point in 2026). A separate industry survey found teams averaging 67 data incidents a month and 15 hours to resolve each one, which is a 24/7 burden in-house teams cannot realistically staff.
Managed is not always the right call. Keep extraction in-house when it is your core product and moat, when your sources are few, niche, and static, when you have idle engineering capacity that genuinely wants the work, or when data can never leave your premises (though note that on-prem managed delivery exists for exactly that case). For the full money comparison, see our build vs buy decision guide, and for the managed-versus-self-service question specifically, our managed vs automated breakdown. If your problem is that off-the-shelf tools stopped scaling, custom web scraping covers that path.
Quick Summary
Q: Why does in-house web data extraction break, and when should you hand it off?
A: It breaks because maintaining scrapers, not building them, is the real cost: redesigns silently break selectors and anti-bot defenses escalate while bots now make up 51% of web traffic. Hand it off when source count and change frequency outpace your team, SLAs slip, and the data is load-bearing enough that errors cost more than the scraping. Keep it in-house when extraction is your core moat or your sources are few and static.
Expert Insights
“The surge in AI-driven bot creation has serious implications for businesses worldwide. In this rapidly changing environment, businesses must evolve their strategies. It’s crucial to adopt an adaptive and proactive approach.”
Tim Chang, General Manager of Application Security, Thales
“These results show teams having to make a lose-lose choice between spending too much time solving for data quality or suffering adverse consequences to their bottom line.”
Barr Moses, CEO and co-founder, Monte Carlo
Top Managed Web Data Extraction Providers (2026)
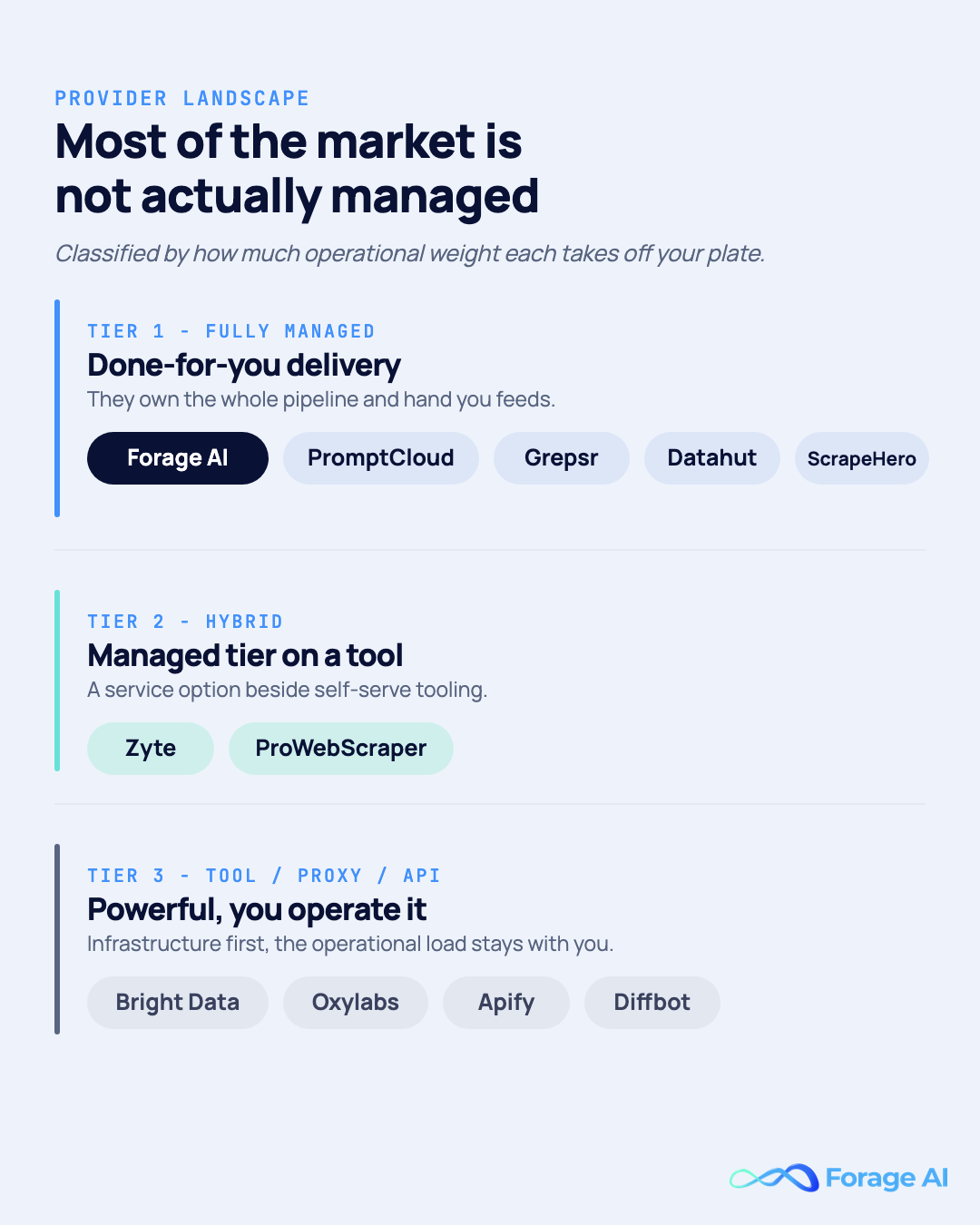
The market is broad, and most of it is not actually managed. Many “best web data extraction” lists flatten proxies, APIs, no-code tools, and done-for-you services into one ranking, which is useless if what you want is to stop operating extraction yourself. So we have classified every provider by how much operational weight it actually takes off your plate: Managed (fully done-for-you delivery), Hybrid (a managed tier on top of a tool or API), and Tool / proxy / API (powerful infrastructure you still operate). No vendor paid for placement.
A note on the ratings below. Each provider carries its public review scores from G2 and Capterra as of June 2026. Capterra figures are page-verified; G2 figures are corroborated across sources but worth a glance before you rely on them, and several newer providers have small review counts, so weigh the number against the sample size. Pricing changes often, so treat every figure as directional and confirm against the live page. Last reviewed June 2026.
Providers at a glance:
- Forage AI (Managed): best for a true end-to-end hand-off with custom schemas, deep QA, and compliance
- PromptCloud (Managed): best for hands-off, high-volume managed feeds
- Grepsr (Managed): best for recurring managed workflows with a success-manager layer
- Datahut (Managed): best for eCommerce and retail pricing data on a smaller budget
- ScrapeHero (Managed): best for done-for-you scraping plus ready-made datasets
- Zyte (Hybrid): best for engineering teams scraping tough anti-bot sites who want an API plus a service
- ProWebScraper (Hybrid): best for small teams wanting point-and-click plus a free scraper-setup service
- Bright Data (Tool/proxy/API): best for the widest proxy pool and highest unblock success at scale
- Oxylabs (Tool/proxy/API): best for premium, reliable proxies and scraper APIs with account management
- Apify (Tool/proxy/API): best for developers wanting a ready-made actor marketplace
- Diffbot (Tool/proxy/API): best for AI extraction of unstructured content plus a knowledge graph
Best Fully-Managed (Done-For-You)
These are the providers that take the whole job. You hand over the sources and a target schema, and they own discovery through delivery, plus the maintenance and QA. This is the tier to look at if your goal is to stop operating extraction entirely, and it is where a real hand-off lives.
Forage AI
Forage AI is a fully-managed extraction partner rather than a tool you operate. It owns the entire pipeline from source discovery to delivery, and it is built for the custom, high-scale, quality-sensitive programs that break self-serve tooling. The model is a dedicated team and a co-engineered pipeline, not a dashboard you log into.
| Attribute | Detail |
|---|---|
| Best for | A true end-to-end hand-off where data quality and compliance are non-negotiable |
| User reviews (Jun 2026) | G2 4.8/5 (smaller but strong review base) |
| Pricing | Custom / project-based, contact sales |
| Standout | End-to-end ownership + multi-layer QA (3x industry-average QA team, 200% QA) + multi-method extraction (XPath/NLP/ML) + governance (no reselling, on-prem, GDPR/CCPA) |
| Watch-out | Built for custom scale, not tiny one-off scrapes; no public pricing |
Who it is for: teams that want to truly offload extraction, including the maintenance, QA, and compliance burden, on complex or regulated data. Forage combines four things few rivals hold together at once: end-to-end pipeline ownership, deep human-plus-AI QA, high customization at scale, and explicit governance. The watch-out: this is a partnership model, so it is not the cheapest way to grab a few thousand rows off one static site, and there is no public price list. What users say: Forage holds a 4.8/5 on G2 across a smaller review base, with clients citing datasets collected and refreshed at scale and scraping, diff-checking, and parsing automated across hundreds of thousands of sites and documents; the recurring ask is better UI and documentation. If you need a managed pipeline you can stop thinking about, start with the web data extraction services line.
PromptCloud
PromptCloud is a long-running data-as-a-service provider that delivers structured web data as a recurring feed, so your team never touches a scraper. It leans toward high-volume, schema-stable feeds rather than one-off projects.
| Attribute | Detail |
|---|---|
| Best for | Hands-off, high-volume structured feeds at recurring scale |
| User reviews (Jun 2026) | G2 4.6/5 (16) · Capterra 4.2/5 (14) |
| Pricing | Basic from $150/mo (Capterra); serious recurring work is custom-quoted |
| Standout | Mature DaaS delivery and responsive support |
| Watch-out | Pricing skews higher-end and opaque; data-freshness visibility gaps |
Who it is for: companies that want clean feeds delivered on a schedule without building infrastructure. What users praise: responsive support and reliable, multi-year delivery at scale. The watch-out: reviewers flag pricing as higher-end and opaque, with conflicting figures across sources, and some note limited weekend support and freshness visibility.
Grepsr
Grepsr is fully-managed extraction with a strong customer-success layer, aimed at teams that want recurring data without hiring scraping specialists. It is one of the better-reviewed managed providers on Capterra.
| Attribute | Detail |
|---|---|
| Best for | Recurring, large-scale managed extraction with hands-on account management |
| User reviews (Jun 2026) | Capterra 4.8/5 (85) · G2 4.5/5 (23) |
| Pricing | From $350/mo (record-based), Starter/Growth/Enterprise |
| Standout | Reliability plus proactive support (Capterra customer-service sub-score 5.0) |
| Watch-out | Limited self-serve control; changes route through their team and can be slow |
Who it is for: teams that want the engineering burden gone and value a responsive account team. What users praise: consistent QA and delivery, and proactive support. The watch-out: you cannot tweak extraction logic on the fly, complex changes go through Grepsr’s team, and the backend interface draws occasional “unintuitive” complaints.
Datahut
Datahut is a managed service focused on eCommerce and retail data (pricing, catalogs, competitor monitoring) with a low entry point and a consultative, founder-accessible style. Its review base is thin but uniformly positive.
| Attribute | Detail |
|---|---|
| Best for | eCommerce and retail product and pricing data on a smaller budget |
| User reviews (Jun 2026) | Capterra 4.9/5 (10, small sample) |
| Pricing | Basic from $40/user/mo; plans from $99/mo; custom enterprise |
| Standout | Affordable, accurate, consultative; takes on tough anti-bot sites |
| Watch-out | Thin review volume; narrower vertical focus; no free trial |
Who it is for: smaller buyers and retail-focused teams that want accurate, ready-to-use data without an in-house team. What users praise: clean accurate output, cost-effectiveness, and direct founder access on hard sites. The watch-out: the review sample is small (10 on Capterra, a handful on G2), so the sentiment is positive but not battle-tested, and the focus is narrower than a general-purpose partner.
ScrapeHero
ScrapeHero spans low-cost self-serve scraping and a custom managed tier, plus ready-made datasets. The managed side is a done-for-you delivery with responsive support and a well-reviewed track record.
| Attribute | Detail |
|---|---|
| Best for | Done-for-you scraping plus ready-made datasets, low engineering lift |
| User reviews (Jun 2026) | G2 4.7/5 (63) · Capterra 4.7/5 (26) |
| Pricing | Managed On Demand from $550/site/refresh; Business from $199/mo/site; Enterprise from $1,500/mo |
| Standout | Responsive support, accurate refresh, large prebuilt-scraper library |
| Watch-out | Credits expire with no rollover; managed tier can feel expensive; learning curve |
Who it is for: teams that want managed delivery with the option of self-serve and prebuilt scrapers. What users praise: responsive support, accurate and frequent refresh, and an organized scraper marketplace. The watch-out: monthly credits expire without rollover, the self-serve-versus-managed pricing causes confusion, and non-technical users report a learning curve.
Hybrid (Managed Tier Plus Tool or API)
Hybrids sell a strong tool or API with a managed service alongside it. You can get a hand-off, but the company’s center of gravity is the self-serve product, so the burden of steering toward the service (and away from doing it yourself) sits with you.
Zyte
Zyte (formerly Scrapinghub, and the team behind Scrapy) is an extraction API and toolkit with a managed option, known for high success rates on heavily defended sites. It is the most engineering-centric entry in this tier.
| Attribute | Detail |
|---|---|
| Best for | Engineering teams scraping tough anti-bot sites who want an API plus an optional service |
| User reviews (Jun 2026) | Capterra 4.4/5 (43) · SoftwareAdvice 4.4/5 (43) |
| Pricing | Usage-based, 5 automatic difficulty tiers; ~$0.13 to $1.27 per 1,000 HTTP requests PAYG; committed from ~$500/mo |
| Standout | High reliability on hard targets; automatic proxy and ban management; AI auto-extraction |
| Watch-out | Complex 5-tier pricing (you may not know a site’s tier until you scrape it); no PAYG spend cap; mixed support response times |
Who it is for: developer teams that want a reliable API for hard targets and can manage variable usage cost. What users praise: strong success rates on protected sites and automatic proxy/ban handling. The watch-out: the five-tier pricing is hard to predict, there is no spending cap on pay-as-you-go (one reviewer reported a bill 40x higher than expected), and support can be slow.
ProWebScraper
ProWebScraper bridges no-code and managed: a point-and-click scraper plus a “free scraper setup” service where their team builds the scraper for you. Its third-party review footprint is thin, which is the main trust barrier.
| Attribute | Detail |
|---|---|
| Best for | Small and mid teams wanting point-and-click plus a hands-on setup service |
| User reviews (Jun 2026) | Thin (Capterra 5.0/5 from a single review; no reliable aggregate) |
| Pricing | Self-serve from ~$40/mo (5,000 pages) up to ~$1,000 (500,000 pages); managed is custom-quoted |
| Standout | Easy point-and-click usable by non-developers; free expert scraper setup |
| Watch-out | Almost no verifiable third-party reviews; some spam/GDPR complaints on Trustpilot |
Who it is for: smaller teams that want an accessible tool with a human assist to get started. What users praise: the point-and-click interface and the free setup service (experts build a scraper, often within a couple of hours). The watch-out: the verifiable review volume is almost nonexistent, so there is little independent signal, and some Trustpilot complaints mention unsolicited email.
Tool / Proxy / API (You Still Operate It)
These are powerful infrastructure, not a hand-off. They solve the hard parts of fetching (proxies, unblocking, AI extraction) but you still build, run, monitor, and QA the pipeline. Include them only if you have the engineering capacity to operate extraction yourself.
Bright Data
Bright Data is the largest proxy and scraping platform, with a residential network, scraping APIs, and prebuilt datasets, and the strongest review base in this group. It is infrastructure first, with a managed add-on.
| Attribute | Detail |
|---|---|
| Best for | The widest proxy pool and highest unblock success at scale |
| User reviews (Jun 2026) | G2 4.7/5 (316) · Capterra 4.7/5 (68) |
| Pricing | Residential PAYG from $4/GB; committed ~$2.50 to $3.50/GB; custom enterprise |
| Standout | Low error rate and high unblock success; broad, well-supported product suite |
| Watch-out | Steep pricing for small or high-volume use; reports of being charged for failed requests; some degraded success against the hardest anti-bot stacks |
Who it is for: large or enterprise teams that need maximum unblock success and will pay for it. What users praise: high unblock rates, responsive support, and a broad easy-to-use suite. The watch-out: pricing is steep at both ends, and reviewers report being billed for failed or blocked requests on the unblocker. Weighing it specifically? See our Bright Data alternatives guide.
Oxylabs
Oxylabs is a premium proxy and scraper-API provider with strong account management, positioned for enterprises rather than value-seekers. Reliability and support are the recurring themes.
| Attribute | Detail |
|---|---|
| Best for | Premium, reliable proxies and scraper APIs with dedicated account management |
| User reviews (Jun 2026) | G2 4.5/5 (421) · Capterra 4.7/5 (23) |
| Pricing | Starter 5GB/$30 ($6/GB) to Corporate 1TB/$2,500 ($2.50/GB); PAYG and custom |
| Standout | Reliable, fast IPs; strong support and dedicated account managers |
| Watch-out | Premium pricing at low volume; learning curve; some billing and refund friction |
Who it is for: businesses that want premium reliability and a real account team, not the cheapest option. What users praise: stable, high-quality IPs and strong support. The watch-out: premium pricing is the single most-cited concern at low volumes, the dashboard has a learning curve, and some reviewers report whitelisting and billing friction.
Apify
Apify is a developer platform built around a marketplace of prebuilt scrapers (“Actors”) plus managed infrastructure (proxies, scheduling, storage). It is the most popular entry here by review volume.
| Attribute | Detail |
|---|---|
| Best for | Developers wanting a ready-made actor marketplace plus managed infrastructure |
| User reviews (Jun 2026) | G2 4.7/5 (~430) · Capterra 4.8/5 (492) |
| Pricing | Free $0; Starter $29/mo; Scale $199/mo; Business $999/mo; Enterprise custom |
| Standout | Large prebuilt actor marketplace; reliable infrastructure; strong value and support |
| Watch-out | Cost predictability is hard (compute units accumulate); learning curve; community actors break when sites change |
Who it is for: developers who want to start fast from prebuilt scrapers and run them on managed infrastructure. What users praise: the marketplace, reliable infrastructure, and value for money. The watch-out: compute-unit billing makes costs hard to predict, and third-party actors can break when target sites change.
Diffbot
Diffbot takes a different approach: AI and computer-vision extraction that auto-structures pages without per-site selectors, plus a large knowledge graph, all via API. It is built for breadth across unstructured content.
| Attribute | Detail |
|---|---|
| Best for | AI extraction of unstructured content plus a knowledge graph, via API |
| User reviews (Jun 2026) | G2 4.9/5 (29) · Capterra 4.5/5 (4, small sample) |
| Pricing | Free $0 (10k credits/mo); Startup $299/mo; Plus $899/mo; Enterprise custom |
| Standout | Selector-free AI extraction; saves scraper-maintenance time; strong knowledge graph |
| Watch-out | Learning curve (query language); raw output can need cleaning; occasional instability |
Who it is for: developers who want AI extraction across many sites without maintaining individual scrapers. What users praise: the time saved versus building custom scrapers, and accurate API data plus the knowledge graph. The watch-out: there is a learning curve to the query model, and raw output sometimes needs cleanup.
Beyond these, Nimble, ScraperAPI, ScrapingBee, Octoparse (see our Octoparse alternatives guide), and Mozenda round out the tool and no-code tier. For the wider toolkit landscape, our top data extraction tools comparison goes deeper.
This is an established, fast-growing category, not a fringe one. The web scraping market is projected to grow from USD 1.03 billion in 2025 to USD 2.23 billion by 2031, a 13.78% CAGR, per Mordor Intelligence. North America holds the largest regional share of that market, roughly a third, which is why most teams comparing these providers are US data teams deciding whether to hand off extraction or keep building it in-house.
| Provider | Class | Best for | Pricing | User reviews (Jun 2026) |
|---|---|---|---|---|
| Forage AI | Managed | End-to-end hand-off, regulated/custom | Custom / project | G2 4.8/5 (small base) |
| PromptCloud | Managed | High-volume feeds | From $150/mo, custom | G2 4.6 (16) · Capterra 4.2 (14) |
| Grepsr | Managed | Recurring managed workflows | From $350/mo | Capterra 4.8 (85) · G2 4.5 (23) |
| Datahut | Managed | eCommerce/retail | From $40-99/mo | Capterra 4.9 (10) |
| ScrapeHero | Managed | Done-for-you + datasets | Business from $199/mo/site | G2 4.7 (63) · Capterra 4.7 (26) |
| Zyte | Hybrid | Hard anti-bot sites, API + service | Usage, committed from ~$500/mo | Capterra 4.4 (43) |
| ProWebScraper | Hybrid | Point-and-click + setup service | Self-serve from ~$40/mo; managed custom | Thin (no reliable aggregate) |
| Bright Data | Tool/proxy/API | Widest proxy pool, unblock | Residential from $4/GB | G2 4.7 (316) · Capterra 4.7 (68) |
| Oxylabs | Tool/proxy/API | Premium proxies + APIs | $6/GB down to $2.50/GB | G2 4.5 (421) · Capterra 4.7 (23) |
| Apify | Tool/proxy/API | Actor marketplace | Free to $999/mo | G2 4.7 (~430) · Capterra 4.8 (492) |
| Diffbot | Tool/proxy/API | AI extraction + knowledge graph | Free to $899/mo | G2 4.9 (29) · Capterra 4.5 (4) |
Quick Summary
Q: Who are the top managed web data extraction providers?
A: For a true done-for-you hand-off, the managed-service leaders are Forage AI, PromptCloud, Grepsr, Datahut, and ScrapeHero. Zyte and ProWebScraper are hybrids that pair a tool or API with a service. Bright Data, Oxylabs, Apify, and Diffbot are powerful but tool/proxy/API-first, which means you still operate them. Match the class to how much operational weight you actually want to give up.
How to Evaluate a Managed Provider
Now that you have seen the field, here is the rubric that separates one managed provider from another. The criteria are the same ones we would apply to ourselves, and most of them come down to whether the provider can answer a specific question with a specific number.
Score every candidate on these:
- Coverage and scale: can they handle your source count, geographies, and refresh frequency without degrading?
- QA methodology and accuracy SLA: ask for the actual method (automated plus human review, confidence thresholds, low-confidence routing) and a stated accuracy number.
- Compliance posture: GDPR and CCPA where relevant, with documentation, not just claims.
- Customization: multi-method extraction tuned to your schema and business rules, versus a single AI method and fixed fields.
- Governance and data ownership: explicit no-reselling, your ownership of the data, and an on-prem option if you need it.
- Delivery: formats, cadence, and delivery SLAs that fit your stack.
- Support and change requests: a named team and a turnaround you can plan around, not a ticket queue.
The reasoning behind the rubric is simple. “We’re accurate” without a number is a red flag. A productized feed is not the same as a co-engineering partner. And a tool or proxy with a “managed tier” bolted on is not the same as a provider whose core business is managed delivery. In 2026 industry benchmarks, the strongest extraction pipelines reach 99%+ field accuracy and 95%+ straight-through processing, so a provider should be able to state where they land. When a provider answers the QA question well, it sounds concrete: automated validation on every record, human review on anything below a confidence threshold, and a measured accuracy figure they will put in a contract, which is the model we run as a 200% QA approach. For the deeper buyer’s version of this, our enterprise evaluation checklist goes criterion by criterion.
On pricing, expect roughly three shapes as of 2026: subscription tiers (starter around USD 50 to 300 a month, professional around USD 300 to 2,000), usage or per-site pricing, and custom enterprise quotes for managed programs. Treat any specific figure as directional and confirm it live.
Screen for the risks that vendor listicles skip. Data reselling, where your extracted data gets reused or aggregated across clients. Vendor lock-in and whether you can export and leave. Black-box pipelines you cannot audit. And compliance liability, which stays with you as the data controller even when the provider does the scraping. Get the answers in writing. For the legal dimension, our guide to the legal and ethical issues in web scraping is the starting point. This is general guidance, not legal advice; consult qualified counsel for your organization’s specific requirements.

Quick Summary
Q: How do you evaluate a managed web data extraction provider?
A: Score them on coverage, a stated QA methodology with an accuracy SLA, compliance posture, customization depth, governance (no reselling, data ownership, on-prem option), delivery SLAs, and support. Treat vague accuracy claims, opaque pricing, and silence on data reselling as red flags, and get the risk answers in writing.
Expert Insights
“Data engineering is boring, gritty and repetitive. Data teams are wasting valuable hours on low-value build, maintenance and management.”
Matthew Scullion, CEO, Matillion
“Data testing remains data engineers’ number one defense against data quality issues, and that’s clearly not cutting it.”
Lior Gavish, CTO and co-founder, Monte Carlo
Which Managed Web Data Extraction Provider Should You Pick?
Start from your situation, not the brand. Map the decision signals from earlier and the rubric above onto a provider class:
- You need a true hand-off with custom schemas, deep QA, and compliance: choose a fully-managed partner like Forage AI.
- You need commodity data like eCommerce pricing at volume: a feed-led managed provider fits.
- You have engineering capacity and want infrastructure, not a partner: a tool, proxy, or API is the right call.
- Your need is small, static, or one-off: DIY or a self-serve tool is more economical.
The one trap to avoid is picking on headline price alone, or trusting a vendor’s own listicle ranking. Trust in data has become the priority it should have been all along: the share of teams citing it as a top priority jumped from 66% to 83% year over year. Pick the model that makes your data trustworthy and your operation sustainable.

Quick Summary
Q: Which managed web data extraction provider should you choose?
A: Start from your decision signals. Choose a fully-managed partner like Forage AI when you need a true hand-off with custom schemas, deep QA, and compliance; a feed-led managed provider for commodity data; and a tool, proxy, or API only if you have the engineering capacity to keep operating it.
Expert Insights
“Organizations that treat governance as infrastructure, not an afterthought, are the ones that will make the most of what AI can do.”
Jason Ganz, Director of Community, Developer Experience and AI, dbt Labs
The Goal Is a Data Operation You Can Sustain
The point of managed web data extraction is not to scrape more. It is to run a data operation your team can keep healthy as sources multiply and anti-bot pressure climbs. If your in-house setup is holding, keep it running. If the maintenance load is quietly winning, you now have the signals to judge the hand-off, the criteria to evaluate a provider, and a shortlist to start from. When you are ready to pressure-test a managed partner against your own sources and schema, that conversation is the fastest way to learn whether the fit is real.

Frequently Asked Questions
What is the difference between web scraping and managed web data extraction?
Web scraping is the raw act of pulling content off a page. Managed web data extraction is the full service around it: cleaning, structuring, validating, enriching, delivering, and maintaining the pipeline, all owned by a provider. Scraping is a step; managed extraction is the whole operation handed off.
How much does managed web data extraction cost?
As of 2026, expect three pricing shapes: subscription tiers (roughly USD 50 to 300 a month for starter, USD 300 to 2,000 for professional), usage or per-site pricing, and custom enterprise quotes for managed programs. Managed partnerships are quote-based because they are scoped to your sources and schema. For the full cost comparison against building in-house, see our build vs buy guide.
Is outsourcing web data extraction legal and safe?
Legality depends on what you collect and how, not on who does the collecting. The key thing operators miss is that compliance liability stays with you as the data controller even when a provider does the scraping, so governance matters. Screen providers for a no-reselling commitment, clear data ownership, and documented compliance. This is general guidance, not legal advice.
How long does it take to get the first data feed?
For a typical managed program, two to four weeks from discovery to a first validated feed. Larger source sets, heavily defended sites, or complex schemas push that longer. The early time goes into source discovery and schema sign-off, which is what makes the later feeds reliable.
What are the risks of outsourcing web data extraction?
The main ones are data reselling, vendor lock-in, black-box pipelines you cannot audit, and the compliance liability that stays with you. Each is screenable: ask for a no-reselling clause, confirm data export and portability, require visibility into QA and methodology, and keep your own compliance review. A provider that answers all four clearly is a safer bet than one that deflects.
Sources
- Mordor Intelligence (2026): Web scraping market size and services-segment CAGR, mordorintelligence.com
- Imperva, a Thales company (2025): 2025 Bad Bot Report, bot traffic and API targeting, thalesgroup.com
- Cloudflare (2025): Default blocking of AI crawlers, July 1, 2025, cloudflare.com
- Matillion / Perspectus Global (2025): Data teams’ time spent on manual tasks (n=307).
- dbt Labs (2026): State of Analytics Engineering, trust-in-data priority shift.
- Gartner (2020): Average annual cost of poor data quality ($12.9M), widely cited through 2026.
Related Articles
- Data Extraction Automation: From Fragile Scripts to Resilient Managed Pipelines, the operational profile of managed extraction done well
- Managed vs Automated Web Scraping Services, choosing between full-service and self-service
- Data Extraction Company: Enterprise Evaluation Checklist (2026), the deep buyer’s checklist
- Build or Buy? A Strategic Guide to Web Data Extraction, the TCO and build-vs-buy decision




